
go语言并发原理和机制【一】

从这篇文章开始,开启Go语言CSP并发模型的学习
老实说,我不太想讲太多关于进程、线程、虚拟内存等内容;毕竟这对于计算机专业的同学来说,鄙人的讲解简直就是班门弄斧。但我思来想去,我觉得还是要从比较底层的东西,层层往上,这样也有助于理解;况且高等操作系统这门课马上就要期末考试了,权当复习复习。
接触Go语言、并发模型,甚至之前写过得关于python线程库threading的源码解读,都是出于偶然,或者兴趣使然,或者是我于枯燥乏味的研究生(单身:))生活中寻找地一点亮光。


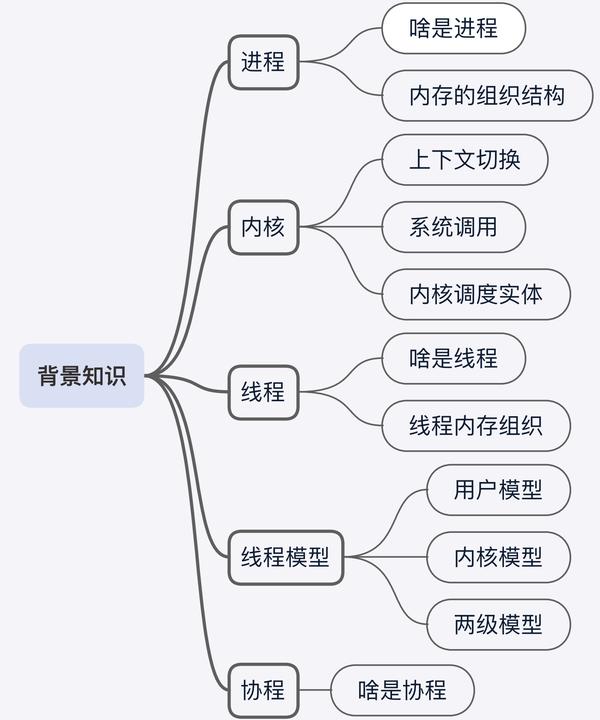

背景知识
我觉得要了解这个并发模型、知晓它凭什么能够做到高并发、知晓系统内核与线程(协程)之间的关系、知晓更加底层的东西,我们还是要来补一补操作系统的知识。
(1)进程
- 进程是一个假象~
每个程序都运行在某个进程上下文中。上下文是由程序正确运行所需的状态组成的,包括:存放在内存中的代码和数据,它的栈、通用目的寄存器、程序计数器、环境变量以及打开的文件描述符的集合。
每次用户通过向shell输人一个可执行目标文件的名字,运行程序时,shell 就会创建一个新的进程,然后在这个新进程的上下文中运行这个可执行目标文件。应用程序也能够创建新进程,并且在这个新进程的上下文中运行它们自己的代码或其他应用程序。
- 内存组织结构
在内存中,系统为每一个进程提供了4G的虚拟内存,制造出一种独占地址空间的假象。其中用户留了3G,内核留了1G;其中用户区包括堆栈、从ELF文件中加载的信息等等。
参考《Computer Systems A Programmer's Perspective》图8-13,以及网上找到一个图解:
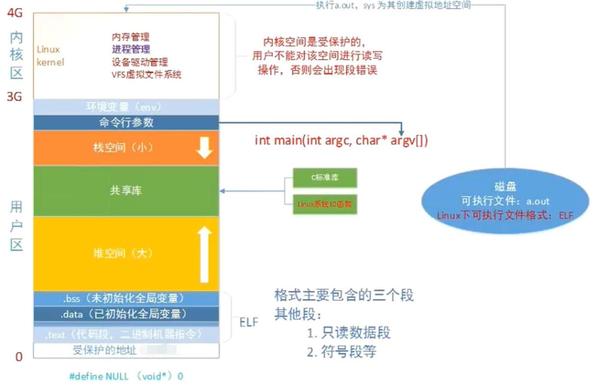

受保护地址段往上三层(有些书就是两层)映射到ELF文件(Executable and Linkable Format)包括:
- 只读代码段:
.text:机器代码
.rodata:只读数据,比如const修饰的变量和字符串常量
- 读/写段:
.data:已初始化的全局和静态变量
.bss:未初始化的全局和静态变量,和初始化为 0 的全局和静态变量
- 然后是堆——共享库内存映射——栈
堆:malloc创建,向上增长,brk指向堆顶部
栈:运行时分配,向下增长,保存一些局部变量等,%esp指向栈顶(小地址)
看个代码,ubuntu19.04 、gcc编译:


运行结果:


不过好像不是从0X00400000开始增长的 可能是机器的问题,再用
/proc/<pid>/maps
/proc —— 文件模式允许用户模式进程访问内核数据结构
查看下这个进程使用的内存段


(2)内核调度实体,上下文切换,系统调用
- 上下文切换
上下文就是内核为进程运行保存其所需的状态:
通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈和各种内核数据结构,比如描述地址空间的页表、包含有关当前进程信息的进程表,以及包含进程已打开文件的信息的文件表。(书里的)
切换呢就是保存当前进程上下文 ——> 恢复先前进程上下文 ——> 控制传递给新恢复的进程
- 系统调用
用户模式,限制用户一个应用可以访问的地址空间。特殊控制寄存器用一个模式位提供 用户模式<->内核模式 的转换。用户模式下,只能通过系统调用,间接访问内核代码和数据。


- 内核调度实体
在系统内核中,对于每一个用户进程,内核都要用至少一个“内核调度实体”(KSE)来与之对应;系统以此来调度进程和进程创建的若干线程。
所以可以想象成一个操作系统下统领着一堆KSE,也可以叫他们“内核线程”,一个用户创建的进程至少与一个内核线程对应,受其管理和支配。借用这篇博客的图:
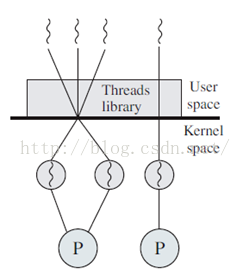
他们之间有不同的模式和对应关系,具体看(4)。
(3)线程
- 啥是线程:线程真的挺复杂的
写到这又不想写很多字了2333(划掉)
我这些天一直在学习,一个线程到底是什么,他的内存在哪里,谁来调度他们呢?进程的话好理解。线程呢?我一直想从内存的角度来理解这个东西。
首先Linux系统当然支持POSIX线程标准(可移植性操作系统借口)。
《Computer System A Programmer's Perspective》中这么说的:线程(thread)就是运行在进程上下文中的逻辑流。在本书里迄今为止,程序都是由每个进程中一个线程组成的。但是现代系统也允许我们编写一个进程里同时运行多个线程的程序。线程由内核自动调度(也就是上面提到的内核调度实体)。每个线程都有自己的上下文,包括一个唯一的整数线程ID、栈、栈指针(%rsp)、程序计数器、通用目的寄存器和条件码。所有的运行在一个进程里的线程共享该进程的整个虚拟地址空间。
- 线程内存模型
线程栈具体在虚拟内存中的哪里?栈里还是在堆里?他们的内存结构是什么样的呢?会不会从虚拟空间中划分出一片区域?
原先我疯狂的上网查找资料,但是说法不统一,知识很碎片。现在我发现《Computer System A Programmer's Perspective》真是本神书,很多疑问我都在上面找到了答案。原书第三版,P696这样说到:
1)每个线程都有自己独立的上下文,每个线程和其他线程一起共享进程上下问的其他部分;
2)让一个线程去读写另外一个线程的寄存器值是不可能的,但是如果修改或共享虚拟内存其他部分,是可以的;
3)各自独立的线程栈的内存模型不是那么整齐清楚的,这些栈保存在虚拟空间的栈区域中,并且通常由线程独立访问。
对操作系统来说,线程是最小的执行单元,进程是最小的资源管理单元。
(4)线程模型
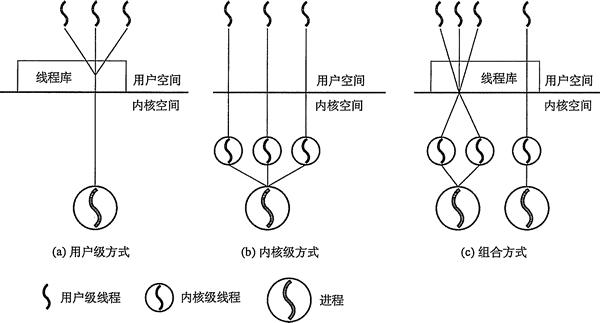
- 用户级线程模型
N:1线程模型。一个保护 N 个线程的进程只会映射到一个内核进程——即 N:1。用户进程全权控制所有线程。内核调度实体只能调度一个进程。可是进程的颗粒度还是太低了。对于我们想要的骚操作,比如线程优先级、让不同进程在不同CPU上运行的意义就微乎其微了。
- 内核级线程模型
1:1线程模型。每个线程对应一个内核调度实体。调度器可以将不同线程调度到不同cpu,真正实现了并行。但是内核管理线程的成本很高。
- 两级模型
N:M线程模型。如果我们把内核级线程模型和用户级线程模型结合起来,可以实现“1:1线程模型”带来的真正并行性,同时还可以利用“N:1线程模型”的低成本切换。不过也不能太绝对。调度器的设计就更加复杂了。
参考下图更加直观(来源网络):

(5)协程
协程,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。 最重要的是,协程不是被操作系统内核所管理,而完全是由用户进程所控制。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。

代码中创建了一个叫做consumer的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销。
(关于协程的概念,我也仅仅是知道一些皮毛,希望大佬们多多指正)
