
Attention Mechanism

题图来源: ICML 2019 Tutorial: Attention in Deep Learning
注意力机制Attention在Deep Learning中很常见,但是原理并不复杂。它的数学本质是加权平均 c=\sum_{j}\alpha_jh_j 。
Key,Value, Query, Memory
迷惑之处在于,有时候有的人会说Key,Value, Query这一套术语来描述attention,令人摸不着头脑。
根据[1]:
The key/value/query concepts come from retrieval systems. For example, when you type a query to search for some video on Youtube, the search engine will map your query against a set of keys (video title, description etc.) associated with candidate videos in the database, then present you the best matched videos (values).
Query, Key, Value来自于检索系统。
CS224n[2]中定义广义的attention为:
Given a set of vector values, and a vector query, attention is a technique to compute a weighted sum of the values, dependent on the query.
对应于seq2seq + attention 模型:
- decoder hidden state : (query)
- encoder hidden states: (values)
Transfomer中还多一个Key, 具体指代什么暂时没有研究:
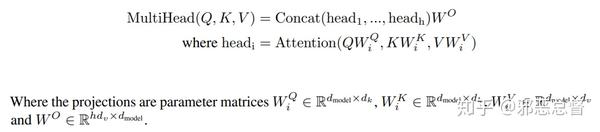

至于Memory记忆是什么鬼?其实在seq2seq里就是encoder的hidden states。这个名字可能是根据生物背景起的。 这里的解释不错:
Attention = (Fuzzy) Memory?
The basic problem that the attention mechanism solves is that it allows the network to refer back to the input sequence, instead of forcing it to encode all information into one fixed-length vector. As I mentioned above, I think that attention is somewhat of a misnomer. Interpreted another way, the attention mechanism is simply giving the network access to its internal memory, which is the hidden state of the encoder. In this interpretation, instead of choosing what to “attend” to, the network chooses what to retrieve from memory. Unlike typical memory, the memory access mechanism here is soft, which means that the network retrieves a weighted combination of all memory locations, not a value from a single discrete location. Making the memory access soft has the benefit that we can easily train the network end-to-end using backpropagation (though there have been non-fuzzy approaches where the gradients are calculated using sampling methods instead of backpropagation).
Memory Mechanisms themselves have a much longer history. The hidden state of a standard Recurrent Neural Network is itself a type of internal memory. RNNs suffer from the vanishing gradient problem that prevents them from learning long-range dependencies. LSTMs improved upon this by using a gating mechanism that allows for explicit memory deletes and updates.
TensorFlow 1.13.1 Seq2seq中的Attention
Seq2Seq常见的两种attention是Luong Attention和Bahdanau Attention,计算scoring的函数分别定义如下:
Bahdanau Score:
def _bahdanau_score(processed_query, keys, normalize):
"""Implements Bahdanau-style (additive) scoring function.
This attention has two forms. The first is Bhandanau attention,
as described in:
Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio.
"Neural Machine Translation by Jointly Learning to Align and Translate."
ICLR 2015. https://arxiv.org/abs/1409.0473
The second is the normalized form. This form is inspired by the
weight normalization article:
Tim Salimans, Diederik P. Kingma.
"Weight Normalization: A Simple Reparameterization to Accelerate
Training of Deep Neural Networks."
https://arxiv.org/abs/1602.07868
To enable the second form, set `normalize=True`.
Args:
processed_query: Tensor, shape `[batch_size, num_units]` to compare to keys.
keys: Processed memory, shape `[batch_size, max_time, num_units]`.
normalize: Whether to normalize the score function.
Returns:
A `[batch_size, max_time]` tensor of unnormalized score values.
"""
dtype = processed_query.dtype
# Get the number of hidden units from the trailing dimension of keys
num_units = tensor_shape.dimension_value(
keys.shape[2]) or array_ops.shape(keys)[2]
# Reshape from [batch_size, ...] to [batch_size, 1, ...] for broadcasting.
processed_query = array_ops.expand_dims(processed_query, 1)
v = variable_scope.get_variable(
"attention_v", [num_units], dtype=dtype)
if normalize:
# Scalar used in weight normalization
g = variable_scope.get_variable(
"attention_g", dtype=dtype,
initializer=init_ops.constant_initializer(math.sqrt((1. / num_units))),
shape=())
# Bias added prior to the nonlinearity
b = variable_scope.get_variable(
"attention_b", [num_units], dtype=dtype,
initializer=init_ops.zeros_initializer())
# normed_v = g * v / ||v||
normed_v = g * v * math_ops.rsqrt(
math_ops.reduce_sum(math_ops.square(v)))
return math_ops.reduce_sum(
normed_v * math_ops.tanh(keys + processed_query + b), [2])
else:
return math_ops.reduce_sum(v * math_ops.tanh(keys + processed_query), [2])这里Unnormalized版本计算的核心就是把query和key合并到一起,乘上一个向量v然后通过tanh(反正和我在CS224n作业里看到版本不太一样)。
Luong Score:
def _luong_score(query, keys, scale):
"""Implements Luong-style (multiplicative) scoring function.
This attention has two forms. The first is standard Luong attention,
as described in:
Minh-Thang Luong, Hieu Pham, Christopher D. Manning.
"Effective Approaches to Attention-based Neural Machine Translation."
EMNLP 2015. https://arxiv.org/abs/1508.04025
The second is the scaled form inspired partly by the normalized form of
Bahdanau attention.
To enable the second form, call this function with `scale=True`.
Args:
query: Tensor, shape `[batch_size, num_units]` to compare to keys.
keys: Processed memory, shape `[batch_size, max_time, num_units]`.
scale: Whether to apply a scale to the score function.
Returns:
A `[batch_size, max_time]` tensor of unnormalized score values.
Raises:
ValueError: If `key` and `query` depths do not match.
"""
depth = query.get_shape()[-1]
key_units = keys.get_shape()[-1]
if depth != key_units:
raise ValueError(
"Incompatible or unknown inner dimensions between query and keys. "
"Query (%s) has units: %s. Keys (%s) have units: %s. "
"Perhaps you need to set num_units to the keys' dimension (%s)?"
% (query, depth, keys, key_units, key_units))
dtype = query.dtype
# Reshape from [batch_size, depth] to [batch_size, 1, depth]
# for matmul.
query = array_ops.expand_dims(query, 1)
# Inner product along the query units dimension.
# matmul shapes: query is [batch_size, 1, depth] and
# keys is [batch_size, max_time, depth].
# the inner product is asked to **transpose keys' inner shape** to get a
# batched matmul on:
# [batch_size, 1, depth] . [batch_size, depth, max_time]
# resulting in an output shape of:
# [batch_size, 1, max_time].
# we then squeeze out the center singleton dimension.
score = math_ops.matmul(query, keys, transpose_b=True)
score = array_ops.squeeze(score, [1])
if scale:
# Scalar used in weight scaling
g = variable_scope.get_variable(
"attention_g", dtype=dtype,
initializer=init_ops.ones_initializer, shape=())
score = g * score
return scoretranspose_b: If True, b is transposed before multiplication.
总的来讲这里的Luong Score就是 h_i^T\tilde{h_j} 其中 h_i 是encoder hidden state, \tilde{h_j} 是decoder hidden state
注意到这里的代码涉及到key, value, query
我的理解是(在这个版本的TF实现中):
- Query: decoder的hidden states, 大小是num_units
- Value: encoder的hidden states(masked后), 这里又被称作memory
- Key: Value之上加一层dense layer转换成num_units大小的一层,用来计算attention
然后看Luong Attention的实现:
class LuongAttention(_BaseAttentionMechanism):
"""Implements Luong-style (multiplicative) attention scoring.
This attention has two forms. The first is standard Luong attention,
as described in:
Minh-Thang Luong, Hieu Pham, Christopher D. Manning.
"Effective Approaches to Attention-based Neural Machine Translation."
EMNLP 2015. https://arxiv.org/abs/1508.04025
The second is the scaled form inspired partly by the normalized form of
Bahdanau attention.
To enable the second form, construct the object with parameter
`scale=True`.
"""
def __init__(self,
num_units,
memory,
memory_sequence_length=None,
scale=False,
probability_fn=None,
score_mask_value=None,
dtype=None,
name="LuongAttention"):
"""Construct the AttentionMechanism mechanism.
Args:
num_units: The depth of the attention mechanism.
memory: The memory to query; usually the output of an RNN encoder. This
tensor should be shaped `[batch_size, max_time, ...]`.
memory_sequence_length: (optional) Sequence lengths for the batch entries
in memory. If provided, the memory tensor rows are masked with zeros
for values past the respective sequence lengths.
scale: Python boolean. Whether to scale the energy term.
probability_fn: (optional) A `callable`. Converts the score to
probabilities. The default is `tf.nn.softmax`. Other options include
`tf.contrib.seq2seq.hardmax` and `tf.contrib.sparsemax.sparsemax`.
Its signature should be: `probabilities = probability_fn(score)`.
score_mask_value: (optional) The mask value for score before passing into
`probability_fn`. The default is -inf. Only used if
`memory_sequence_length` is not None.
dtype: The data type for the memory layer of the attention mechanism.
name: Name to use when creating ops.
"""
# For LuongAttention, we only transform the memory layer; thus
# num_units **must** match expected the query depth.
if probability_fn is None:
probability_fn = nn_ops.softmax
if dtype is None:
dtype = dtypes.float32
wrapped_probability_fn = lambda score, _: probability_fn(score)
super(LuongAttention, self).__init__(
query_layer=None,
memory_layer=layers_core.Dense(
num_units, name="memory_layer", use_bias=False, dtype=dtype),
memory=memory,
probability_fn=wrapped_probability_fn,
memory_sequence_length=memory_sequence_length,
score_mask_value=score_mask_value,
name=name)
self._num_units = num_units
self._scale = scale
self._name = name
def __call__(self, query, state):
"""Score the query based on the keys and values.
Args:
query: Tensor of dtype matching `self.values` and shape
`[batch_size, query_depth]`.
state: Tensor of dtype matching `self.values` and shape
`[batch_size, alignments_size]`
(`alignments_size` is memory's `max_time`).
Returns:
alignments: Tensor of dtype matching `self.values` and shape
`[batch_size, alignments_size]` (`alignments_size` is memory's
`max_time`).
"""
with variable_scope.variable_scope(None, "luong_attention", [query]):
score = _luong_score(query, self._keys, self._scale)
alignments = self._probability_fn(score, state)
next_state = alignments
return alignments, next_state_call_函数调用了一下_luong_score函数计算Luong Attention score, 然后放进softmax。注意这里next_state 和 alignments是一样的东西,那么存在的意义是什么呢?
