
混沌工程(Chaos Engineering) 总结

Netflix工程师创建了Chaos Monkey,使用该工具可以在整个系统中在随机位置引发故障。正如GitHub上的工具维护者所说,“Chaos Monkey会随机终止在生产环境中运行的虚拟机实例和容器。”通过Chaos Monkey,工程师可以快速了解他们正在构建的服务是否健壮,是否可以弹性扩容,是否可以处理计划外的故障。
2012年,Netflix开源了Chaos Monkey。今天,许多公司(包括谷歌,亚马逊,IBM,耐克等),都采用某种形式的混沌工程来提高现代架构的可靠性。 Netflix甚至将其混沌工程工具集扩展到包括整个“Simian Army(中文可以译为猿军)”,用它攻击自己的系统。
混沌工程属于一门新兴的技术学科,行业认知和实践积累比较少,大多数IT团队对它的理解还没有上升到一个领域概念。阿里电商域在2010年左右开始尝试故障注入测试的工作,希望解决微服务架构带来的强弱依赖问题。
混沌工程,是一种提高技术架构弹性能力的复杂技术手段。Chaos工程经过实验可以确保系统的可用性。混沌工程旨在将故障扼杀在襁褓之中,也就是在故障造成中断之前将它们识别出来。通过主动制造故障,测试系统在各种压力下的行为,识别并修复故障问题,避免造成严重后果。
它,被描述为“在分布式系统上进行实验的学科,目的是建立对系统承受生产环境中湍流条件能力的信心。”。
Chaos Engineering is the discipline of experimenting on a systemin order to build confidence in the system’s capabilityto withstand turbulent conditions in production.
它也可以视为流感疫苗,故意将有害物质注入体内以防止未来疾病,这似乎很疯狂,但这种方法也适用于分布式云系统。混沌工程会将故障注入系统以测试系统对其的响应。这使公司能够为宕机做准备,并在宕机发生之前将其影响降至最低。
如何知道系统是否处于稳定状态呢?通常,团队可以通过单元测试、集成测试和性能测试等手段进行验证。但是,无论这些测试写的多好,我们认为都远远不够,因为错误可以在任何时间发生,尤其是对分布式系统而言,此时就需要引入混沌工程(Chaos Engineering)。
故障演练:目标是沉淀通用的故障模式,以可控成本在线上重放,以持续性的演练和回归方式运营来暴露问题,不断推动系统、工具、流程、人员能力的不断前进。
Chaos Engineering is a helpful tool in understanding your system’s unknowns, but it is not the means to an end for achieving resilience. Instead, it helps to instill higher confidence in the ability to cope and be resilient in the face of inevitable failures.
混沌工程、故障注入和故障测试在关注点和工具中都有很大的重叠。
混沌工程和其他方法之间的主要区别在于,混沌工程是一种生成新信息的实践,而故障注入是测试一种情况的一种特定方法。当想要探索复杂系统可能出现的不良行为时,注入通信延迟和错误等失败是一种很好的方法。但是我们也想探索诸如流量激增,激烈竞争,拜占庭式失败,以及消息的计划外或不常见的组合。如果一个面向消费者的网站突然因为流量激增而导致更多收入,我们很难称之为错误或失败,但我们仍然对探索系统的影响非常感兴趣。同样,故障测试以某种预想的方式破坏系统,但没有探索更多可能发生的奇怪场景,那么不可预测的事情就可能发生。
混沌工程以实验发现系统性弱点。这些实验通常遵循四个步骤:
1.定义并测量系统的“稳定状态”。首先精确定义指标,表明您的系统按照应有的方式运行。 Netflix使用客户点击视频流设备上播放按钮的速率作为指标,称为“每秒流量”。请注意,这更像是商业指标而非技术指标;事实上,在混沌工程中,业务指标通常比技术指标更有用,因为它们更适合衡量用户体验或运营。
2.创建假设。与任何实验一样,您需要一个假设来进行测试。因为你试图破坏系统正常运行时的稳定状态,你的假设将是这样的,“当我们做X时,这个系统的稳定状态应该没有变化。”为什么用这种方式表达?如果你的期望是你的动作会破坏系统的稳定状态,那么你会做的第一件事会是修复问题。混沌工程应该包括真正的实验,涉及真正的未知数。
3.模拟现实世界中可能发生的事情,目前有如下混沌工程实践方法:模拟数据中心的故障、强制系统时钟不同步、在驱动程序代码中模拟I/O异常、模拟服务之间的延迟、随机引发函数抛异常。通常,您希望模拟可能导致系统不可用或导致其性能降低的场景。首先考虑可能出现什么问题,然后进行模拟。一定要优先考虑潜在的错误。 “当你拥有非常复杂的系统时,很容易引起出乎意料的下游效应,这是混沌工程寻找的结果之一,”“因此,系统越复杂,越重要,它就越有可能成为混沌工程的候选对象。”
4.证明或反驳你的假设。将稳态指标与干扰注入系统后收集的指标进行比较。如果您发现测量结果存在差异,那么您的混沌工程实验已经成功 - 您现在可以继续加固系统,以便现实世界中的类似事件不会导致大问题。或者,如果您发现稳定状态可以保持,那么你对该系统的稳定性大可放心。
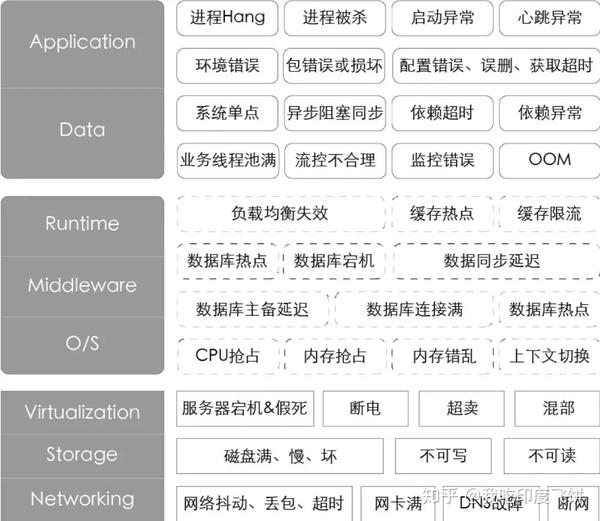
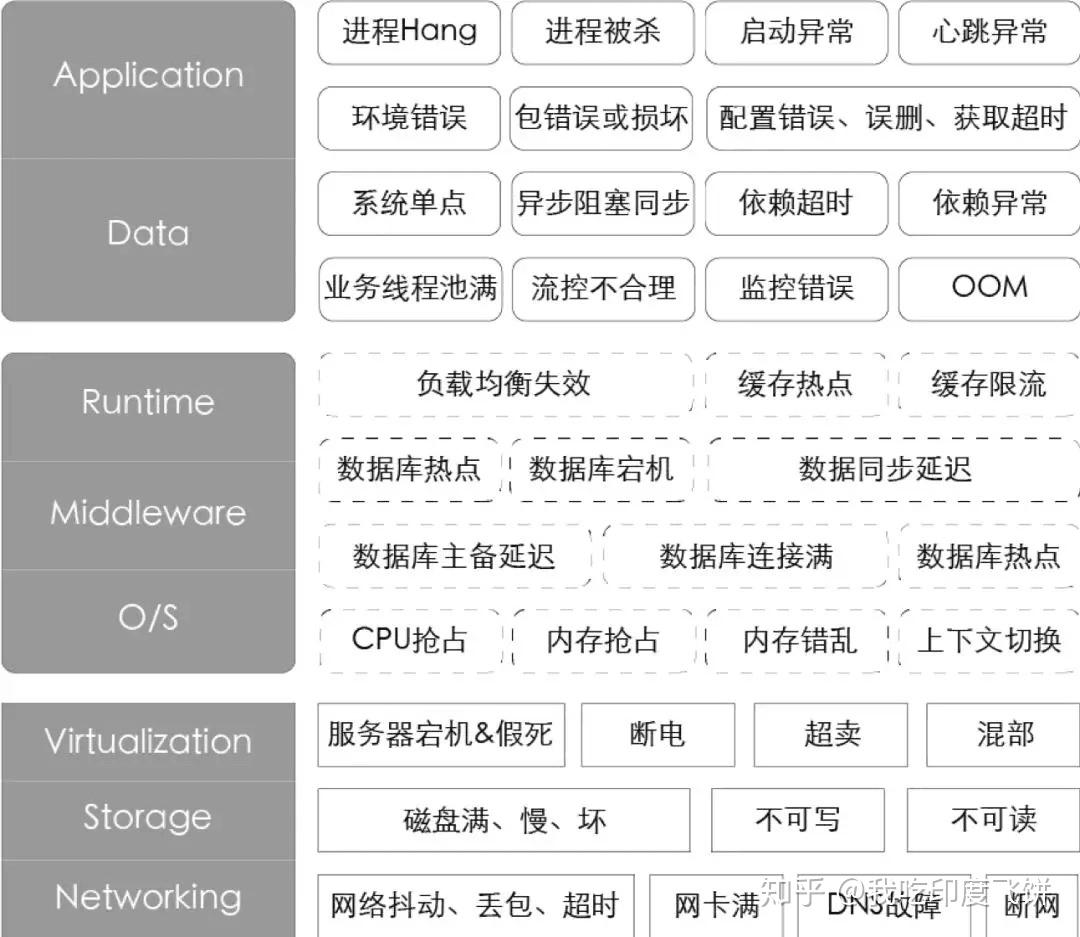
各式各样的故障。这些故障信息就是最真实的混沌工程变量。
为了能够更体感、有效率地描述故障,我们优先分析了P1和P2的故障(P是阿里对故障等级的描述),提出一些通用的故障场景并按照IaaS层、PaaS层、SaaS层的角度绘制了故障画像。
ChaosBlade
ChaosBlade 是一款遵循混沌工程实验原理,建立在阿里巴巴近十年故障测试和演练实践基础上,并结合了集团各业务的最佳创意和实践,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具。
混沌工程比较适合对数据安全性要求较高的场景。此外,如果业务对故障容错有所承诺,也需要通过混沌工程验证系统是否可以支持容错。量化到具体指标来看,如果开发人员确定系统会宕机并且清楚宕机之后会造成较大损失,可以通过“支持快速终止实验”和“最小化实验造成的‘爆炸半径’”等方式实施混沌工程。
在开发混沌工程实验时,可遵循以下原则,将有助于实验设计:
- 建立稳定状态的假设;
- 多样化现实世界事件;
- 在生产环境运行实验;
- 持续自动化运行实验;
- 最小化“爆炸半径”
混沌工程原则 (PRINCIPLES OF CHAOS ENGINEERING)
相关链接:
