
知识蒸馏论文选读(二)

Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
原文链接:https://arxiv.org/pdf/1903.12136.pdf
Preprint
Abstract
在该文中,作者证明了初级的、轻量级的神经网络,在不改变结构、不增加训练数据和额外特征的情况下,可以取得和预训练语言模型可比的结果。
作者提出将BERT中的知识蒸馏到一个单层的BiLSTM中。实验发现,这样得到的BiLSTM可以取得和ELMo可比的结果,而模型的参数是ELMo的 1 / 100 ,运行时间是ELMo的 1/15 。
1 Introduction
ELMo、BERT以及GPT-2等大规模的预训练语言模型在应用中面临计算资源和延迟等方面的限制。摩尔定律和登纳德缩放比例定律的逐渐失效也表明,我们在选择模型时需要慎重考虑,对模型进行压缩是有必要的。
作者的这篇文章有两方面的贡献:
作者提出了一种简单有效的、基于任务类型的知识蒸馏方法,将BERT的知识迁移到BiLSTM中。作者做了两方面的讨论:首先,作者说明了简单模型在表示方面确实不够给力;其次,作者探索了将知识进行迁移的有效方法,具体地讲,作者使用了Caruana等人和Hinton等人的方法,用复杂模型作为老师,用简单模型作为学生以模仿老师的输出。原文这里用“model agnostic”形容作者提出的方法,直译过来就是“模型不可知”,个人理解可以意译为“模型黑盒”,即Hinton提出的,将模型的知识看做一个抽象的映射,而非模型的具体参数。
作者还提出了一种用于NLP任务的数据增强方式。知识蒸馏一般需要大规模的、无标注的数据集(也可以是有标注的),称为“迁移集”。大模型对这些数据做出预测,提供给小模型学习。在计算机视觉中,通常可以使用旋转、附加噪声和其他失真方法来增强数据以轻松获得未标记的图像。但是,在NLP中很难获得特定任务的额外甚至是未标注的数据。NLP中的传统数据增强方式通常是特定于任务的,很难扩展到其他任务。作者提出了一种新颖的、基于规则的文本数据扩充方法,用于构建知识迁移集。尽管作者的扩充样本不是流畅的句子,但实验结果表明,该方法出奇地适用于知识蒸馏。
作者在单句分类和句对匹配的三个任务上进行了实验。实验结果表明,通过知识蒸馏学习的小模型,其性能比从头训练的小模型好,其结果与采用ELMo输出作为词向量的结果可比。
2 Related Work
作者在该部分介绍了预训练语言模型和模型压缩两部分的相关工作。
预训练语言模型效果好,但是其推断结果需要的时间长,所以模型在部署的时候一般要将其压缩。
3 Our Approach
在该部分,作者首先选择了师生模型(大模型和小模型)。然后,作者描述了蒸馏的两个过程:第一,在目标函数附加logits回归部分;第二,构建迁移数据集,从而增加了训练集,可以更有效地进行知识迁移。
3.1 Model Architecture
作者选择BERT+分类层作为其大模型。对于单句分类和句对分类两个不同的任务,作者采用了不同的办法:
- 对于单句分类任务,作者将BERT输出的句子的向量表示过dense层和softmax层,得到logits输出。
- 对于句对分类任务,作者分别将两个句子过BERT,得到两个句子各自的向量表示。然后将两个向量拼接起来过dense层和softmax层(作者为什么不使用BERT自带的句对分类?)。
- 在蒸馏训练小模型的过程中,作者对BERT和分类层的参数都进行了微调。
作者选择单层的BiLSTM作为其小模型。对于单句分类和句对分类两个不同的任务,作者采用了不同的结构:
- 对于单句分类任务,小模型就是一个普通的BiLSTM。具体结构为:sentence -> Embedding Layer -> Word Embeddings -> BiLSTM -> Hidden States (Bidirection) -> dense -> Relu -> dense -> logits ->softmax
- 对于句对分类任务,小模型其实也是普通的BiLSTM。作者将同个句对的每个句子使用同一个BiLSTM编码,然后将两个句子的BiLSTM表示做标准的拼接比较操作。令 h_{s1} 、 h_{s2} 分别为两个句子的BiLSTM表示,那么句对的表示可以通过该计算得到: S_{pair}=[h_{s1}, h_{s2}, h_{s1} \odot h_{s2}, |h_{s1}-h_{s2}|] , \odot 是元素对位相乘操作。具体结构为:sentence -> Embedding Layer -> Word Embeddings -> BiLSTM -> Hidden States (Bidirection) -> concatenate-compare unit -> sentence pair representation -> dense -> Relu -> dense -> logits ->softmax
- 为了重新审视BiLSTM的表示能力,作者没有使用其他的结构。
3.2 Distillation Objective
直接放Loss函数:
\mathscr{L}=\alpha \cdot \mathscr{L}_{CE} + (1-\alpha) \cdot \mathscr{L}_{distill} =-\alpha\Sigma_{i}t_{i}logy^{(S)}_{i}-(1-\alpha)||z^{(B)}-z^{(S)}||^{2}_{2}
如果蒸馏训练的数据是带标签的,那么 t 是one-hot真值 ;如果迁移集不带标签,那么t是通过大模型softmax输出转换得到的ont-hot向量。
z^{(B)} 和 z^{(S)} 分别是大模型和小模型的logits输出。 y 是小模型的softmax输出。
3.3 Data Augmentation for Distillation
在蒸馏过程中,小数据集可能无法完全表达大模型的知识。因此,文中提出了三种任务无关的数据增强方法来人为扩充数据集,防止过拟合。
相比CV,NLP的数据增强要更困难。首先,在CV领域有大量的同源图像。其次,通过加噪等方式合成接近自然生成的图像是可能的,但如果我们对句子做一些改变,句子可能就不流畅,这种样本在NLP数据增强中的作用尚不清楚。
- Masking:以一定的概率,用[MASK]标签来取代句子中的某个单词。
- POS-guided word replacement:以一定的概率,用同词性的词来取代当前词。根据原始训练集中同词性词语的词频来确定取代词。
- n-gram sampling:以一定的概率,用n-gram来取代原始的句子。n的取值范围是[1,5]。这个操作相当于dropout,是升级版的Masking。
数据增强的步骤如下:
- 先遍历句子中的每个单词,对每个单词产生一个平均分布的[0,1]区间的概率。根据概率落在的区间,选择用Masking还是POS方式替换当前词。
- 遍历完成后,以一定的概率选择是否进行n-gram sampling。
- 对每个句子,进行 n_{iter} 次增强,产生n_{iter} 个伪数据。对句对匹配任务,固定第一个句子、第二个句子、两个句子都不固定,进行3 n_{iter} 次数据增强。
4 Experimental Setup
介绍了数据集、超参数和一些用到的预训练语言模型。
作者用4个不同的学习率,微调好4个BERT,取在验证集上最好的模型作为大模型。微调过程中没有使用数据增强。
在蒸馏训练的过程中,作者将原始训练集和增强伪数据同时输入。通过实验发现,只使用蒸馏目标项的时候可以取得最好的结果。
5 Results and Discussion
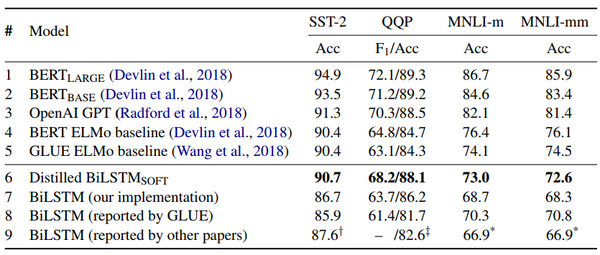

结论:
- 在SST-2和QQP任务上,蒸馏模型的效果超过了基于ELMo词向量的双向LSTM。在NMLI任务上,蒸馏模型也比普通的BiLSTM好很多。
- 总体来看,蒸馏模型与ELMo是可比的。
- 虽然蒸馏模型和BERT以及GPT的差距较大,但是参数少,效率高。
6 Conclusion and Future Work
在本文中,作者探索了从BERT蒸馏知识到简单的基于BiLSTM模型的方法。蒸馏模型获得了与ELMo可比的结果,但是参数量和推理时间要更少。结果表明,浅层的BiLSTM对于自然语言任务的表达能力比之前认知的要强。
未来工作的一个方向是探索更简单的体系结构,例如卷积神经网络,甚至支持向量机和逻辑回归;另一个相反的方向是使用成对单词交互和注意之类的技巧,探索稍微复杂的体系结构。
Referrnce
