kaggle支付反欺诈:IEEE-CIS Fraud Detection第一名方案复现过程(有代码)

写在前面:
IEEE-CIS Fraud Detection比赛参加人数有6000多人,有很多国内和国外的竞赛大神都参与其中,算是含金量比较高的比赛了。楼主前期基本上徘徊在100名左右,但到后期由于工作上的事情,后来基本上也没时间搞了(主要也是能力有限,哈哈)。因为自己也是做反欺诈这块的工作,所以希望能够通过这次比赛能够学到一些能在工作中使用的小trick。
本文主要是针对第一名的方案进行复现(后面也会写前排其他大佬的方案,待更新。。。),包括在复现过程中的一些问题和思考,希望能给大家带来一些启发。当然,本人能力有限,有说的不对的地方,希望大家能够评论指证。
相关链接,参考:
(1)第1名方案:
part1: 1st Place Solution - Part 1
part2: 1st Place Solution - Part 2
比赛数据:链接:https://pan.baidu.com/s/1e3KceZHOpHyWeOYVATIZGw 密码:yigf
复现代码:https://github.com/DJofOUC/IEEE-CIS-Fraud-Detection/tree/master
赛题简析:
该赛题的主要目标是识别出每笔交易是否是欺诈的。其中训练集样本约59万(欺诈占3.5%),测试集样本约50万。数据主要分为2类,交易数据transaction和identity数据,数据字段的有关说明见:Data Description (Details and Discussion)
具体的样本量和特征维度如下图:
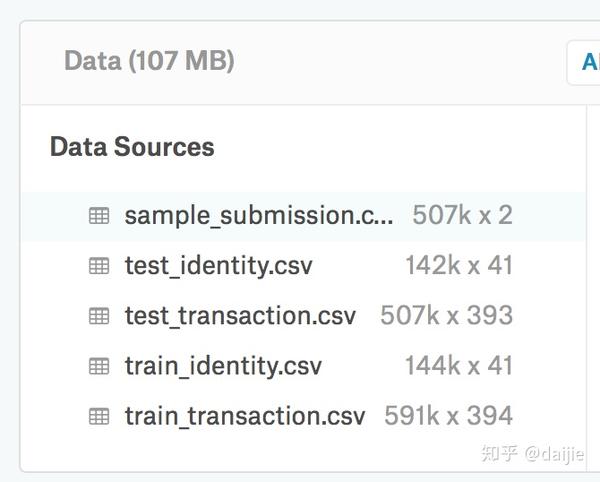
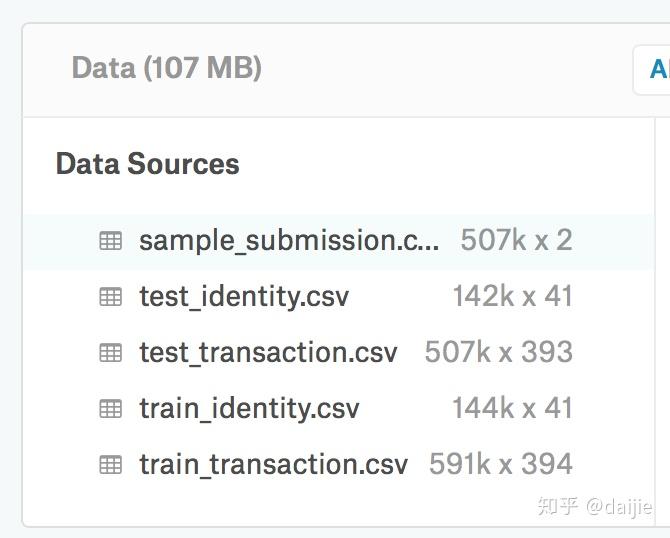
从上图可以看出,总共的特征维度有393 + 41 = 434维,很明显,我们要做数据降维。
如何定位支付欺诈?支付欺诈背后真正的业务意义是什么?
(我的理解)打标签的逻辑:将该次交易之后用户提出了退款的交易定义为欺诈(一般是受骗之后,用户发现了,然后向银行提出取消交易或退款),当然正常的退款除外,如退货之类的。并且若其他的交易与欺诈交易相关的用户的账户,email和账单地址有直接联系,也定义为欺诈(isFraud=1)。若该次交易发生120天后还没有被定义为欺诈,那么该次交易就是正常交易(isFraud=0)。
理解了打标签的逻辑,在分析欺诈的特征的时候,就会发现,有73838位用户是有2次或2次以上的交易,其中71575位 (96.9%)是没有欺诈标签的(isFraud=0),2134位 (2.9%)是全部都是欺诈标签(isFraud=1),只有129 位(0.2%)是既有欺诈标签也有非欺诈标签的。从中,我们可以获得在业务中欺诈的逻辑,一个用户有过欺诈经历,那么他下次欺诈的概率还是非常高的,我们需要关注到这一点。
如何找到用户的唯一标识?
在原始数据中是没有uid这类的字段的,那么如何找到用户的唯一标识呢?这怎么能难到大神们,经过分析(也不知道怎么分析的),card1(银行卡的前多少位),addr1和D1 这三个字段合并起来可以唯一识别一位用户。D1表示截止到目前为止的用户开卡天数。实际上就是通过银行卡的前多少位,用户地址(类似区号代码之类的)和该用户银行卡的使用天数,我们就可以绝大概率对应着某位用户。如下所示:
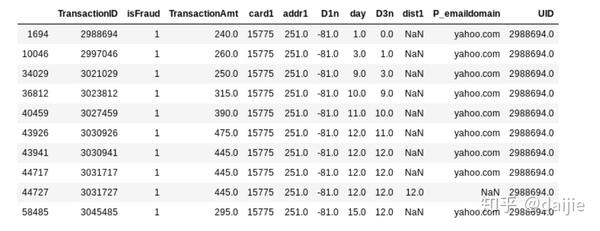

D1n = TransactionDT/ (60*60*24) - D1,表示开卡日期。
用户唯一标识如何使用?
确定了用户的唯一标识之后,我们并不能直接把它当作一个特征直接加入到模型中去,因为通过分析发现,测试集中有68.2%的用户是新用户,并不在训练集中。我们需要间接的使用uid,用uid构造一些聚合特征。
Main magic:
- client identification (uid) using card/D/C/V columns (we found almost all 600 000 unique cards and respective clients)用户的唯一标识(十分重要)
- uid (unique client ID) generalization by agg to remove train set overfitting for known clients and cards使用uid构建聚合特征
- categorical features / supportive features for models类别特征的编码(主要是用频率编码和label encode)
- horizontal blend by model / vertical blend by client post-process(水平方向:模型融合;垂直方向:针对用户的后处理)
特征筛选策略:
- Train 2 month / skip 2 / predict 2
- Train 4 / skip 1 / predict 1
构建一些特征之后,加入到原有特征中去,使用以上方式来验证该特征是否有效。
特征编码:
主要使用以下五种特征编码方式
# encoding function
# frequency encode频率编码
def encode_FE(df1, df2, cols):
for col in cols:
df = pd.concat([df1[col], df2[col]])
vc = df.value_counts(dropna=True, normalize=True).to_dict()
vc[-1] = -1
nm = col + "FE"
df1[nm] = df1[col].map(vc)
df1[nm] = df1[nm].astype("float32")
df2[nm] = df2[col].map(vc)
df2[nm] = df2[nm].astype("float32")
print(col)
# label encode
def encode_LE(col, train=X_train, test=X_test, verbose=True):
df_comb = pd.concat([train[col], test[col]], axis=0)
df_comb, _ = pd.factorize(df_comb[col])
nm = col
if df_comb.max() > 32000:
train[nm] = df_comb[0: len(train)].astype("float32")
test[nm] = df_comb[len(train):].astype("float32")
else:
train[nm] = df_comb[0: len(train)].astype("float16")
test[nm] = df_comb[len(train):].astype("float16")
del df_comb
gc.collect()
if verbose:
print(col)
def encode_AG(main_columns, uids, aggregations=["mean"], df_train=X_train, df_test=X_test, fillna=True, usena=False):
for main_column in main_columns:
for col in uids:
for agg_type in aggregations:
new_column = main_column + "_" + col + "_" + agg_type
temp_df = pd.concat([df_train[[col, main_column]], df_test[[col, main_column]]])
if usena:
temp_df.loc[temp_df[main_column] == -1, main_column] = np.nan
#求每个uid下,该col的均值或标准差
temp_df = temp_df.groupby([col])[main_column].agg([agg_type]).reset_index().rename(
columns={agg_type: new_column})
#将uid设成index
temp_df.index = list(temp_df[col])
temp_df = temp_df[new_column].to_dict()
#temp_df是一个映射字典
df_train[new_column] = df_train[col].map(temp_df).astype("float32")
df_test[new_column] = df_test[col].map(temp_df).astype("float32")
if fillna:
df_train[new_column].fillna(-1, inplace=True)
df_test[new_column].fillna(-1, inplace=True)
print(new_column)
# COMBINE FEATURES交叉特征
def encode_CB(col1, col2, df1=X_train, df2=X_test):
nm = col1 + '_' + col2
df1[nm] = df1[col1].astype(str) + '_' + df1[col2].astype(str)
df2[nm] = df2[col1].astype(str) + '_' + df2[col2].astype(str)
encode_LE(nm, verbose=False)
print(nm, ', ', end='')
# GROUP AGGREGATION NUNIQUE
def encode_AG2(main_columns, uids, train_df=X_train, test_df=X_test):
for main_column in main_columns:
for col in uids:
comb = pd.concat([train_df[[col] + [main_column]], test_df[[col] + [main_column]]], axis=0)
mp = comb.groupby(col)[main_column].agg(['nunique'])['nunique'].to_dict()
train_df[col + '_' + main_column + '_ct'] = train_df[col].map(mp).astype('float32')
test_df[col + '_' + main_column + '_ct'] = test_df[col].map(mp).astype('float32')
print(col + '_' + main_column + '_ct, ', end='')聚合特征的构建:见以上代码
模型融合:
三个经典的GBDT模型
- Catboost (0.963915 public / 0.940826 private)
- LGBM (0.961748 / 0.938359)
- XGB (0.960205 / 0.932369)
目前复现的结果还只是单XGB的结果,提交了late submission得分如下:


