
flink源码阅读第一篇—入口

编程的
前序
- 由于最近接触了flink相关项目,封装flink-table模块,这部分模块应该在flink官方1.9x版本进行发布,截止目前还是beta版本,等待最终的release版本发布。在开发期间,出于工作和兴趣的需求,就阅读了部分源码,阅读源码期间也是阅读了很多博客文章,发下文章写错的也比比皆是呀,哎有时也会误导人。先叙述第一篇总体轮廓篇。该篇总体思路是从flink任务提交开始,从本地提交代码逻辑,到服务端如果接收任务,最后运行的不同分支逻辑。了解这部分逻辑,需要一些基础知识,包括yarn, netty最基本的了解。关于yarn和netty介绍可以参考
flink任务提交方式
- flink提交方式和spark类似,比spark还略微复杂些。大体分这么几类 1、单机本地体检,2、多机集群提交,3、yarn-session提交,4、yarn-cluster per-job提交、5、还包括mesos和docker提交(这俩个略叙)。 生产环境中用第四种比就多,每个任务作为一个yarn application提交到集群,申请的资源和其他任务是隔离的,其他方式相对这个都略显简单。下面主要介绍第四种Per-Job-Cluster。
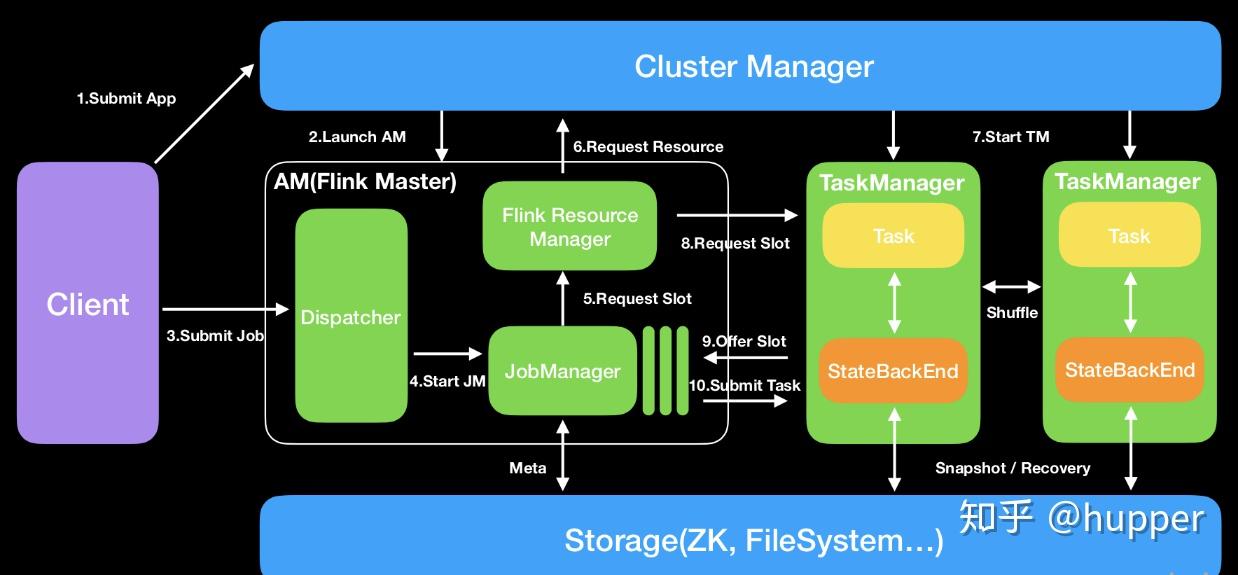
- 在看代码之前先对flink组件有个大概的初步认知:
- 1、Dispatcher(Application Master)提供REST接口来接收client的application提交,它负责启动JM和提交application,同时运行Web UI。
- 2、ResourceManager:一般是Yarn,当TM有空闲的slot就会告诉JM,没有足够的slot也会启动新的TM。kill掉长时间空闲的TM。
- 3、JobManager :接受application,包含StreamGraph(DAG)、JobGraph(logical dataflow graph,已经进过优化,如task chain)和JAR,将JobGraph转化为ExecutionGraph(physical dataflow graph,并行化),包含可以并发执行的tasks。其他工作类似Spark driver,如向RM申请资源、schedule tasks、保存作业的元数据,如checkpoints。如今JM可分为JobMaster和ResourceManager(和下面的不同),分别负责任务和资源,在Session模式下启动多个job就会有多个JobMaster。
- 4、TaskManager:类似Spark的executor,会跑多个线程的task、数据缓存与交换。

代码分析:
- Per-Job-Cluster模式也分为本地和远端。

编辑于 2019-09-19 13:35