《Sentence-BERT》论文笔记

学生


Motivation
Bert虽然支持求两个句子相似度的任务,但并不支持句向量(sentence vector)的功能,简单地利用[CLS]的输出作为句向量的方法被证明效果并不好(比Glove向量的平均要差)。而把句子嵌入为向量是许多后续任务所必须的,试想在一个10000个句子的数据集中索引某一个句子最接近的句子,这就需要运行10000次BERT,这显然是不可接受的。句向量可以让这个索引大大加速。
Model
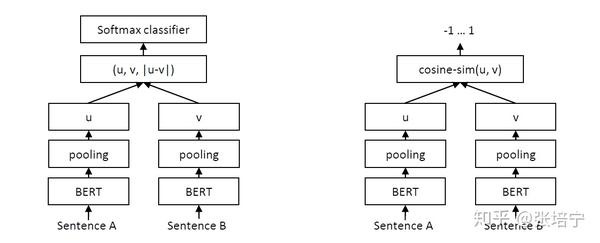

这里的图一是训练时利用Bert训练句向量的任务,是在一个有句子相似度标签的数据集上finetune,用来判断两个句子是否相似。图二是推断时用的结构,也是一个训练任务,用余弦相似度作为输出,训练时最小化均方误差。
Conclusion
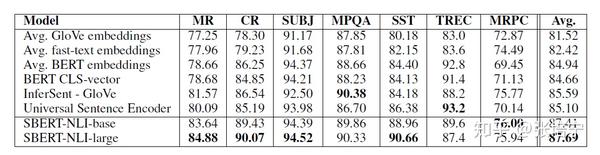
模型很简单,但是可以看出做了很多实验,在下游u,v的组合方式,上游的Pooling方式上都做了很多探索。不过虽然有一些共同的指标和评测任务,但是由于预训练任务的不同,这一类论文的比较也比较困难。SentEval上的结果并不比18年的MC-QT更好,而且可以想见要慢不少,估计基于Bert的句向量还会有进步。

编辑于 2019-09-17 05:44