
Flink 实时计算 - 维表 Join 的实现


大家好,我是Lake,专注互联网科技见解分享、程序员经验分享、大数据技术分享。
前言
Flink 1.9 版本可以说是一个具有里程碑意义的版本,其内部合入了很多 Blink Table/SQL 方面的功能,同时也开始增强 Flink 在批处理方面的能力,真的是向批流统一的终极方向开始前进。Flink 1.9 版本在 8.22 号也终于发布了。本文主要介绍学习 Flink SQL 维表 Join,维表 Join 对于SQL 任务来说,一般是一个很正常的功能,本文给出代码层面的实现,和大家分享用户如何自定义 Flink 维表。


1. 什么是维表
维表作为 SQL 任务中一种常见表的类型,其本质就是关联表数据的额外数据属性,通常在 Join 语句中进行使用。比如源数据有人的身份证号,人名,你现在想要得到人的家庭地址,那么可以通过身份证号去关联人的身份证信息,就可以得到更全的数据。
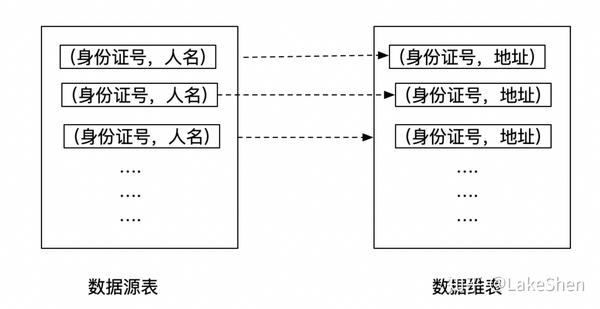

维表可以是静态的数据,也可以是动态的数据(比如定时更新的数据),一般会通过特定的主键来进行关联。它可以在 Mysql 中进行存储,也可以在 Nosql 数据库中进行存储,比如 HBase等。
2. Flink 中的维表
Flink 1.9 中维表功能来源于新加入的Blink中的功能,如果你要使用该功能,那就需要自己引入 Blink 的 Planner,而不是引用社区的 Planner。由于新合入的 Blink 相关功能,使得 Flink 1.9 实现维表功能很简单,只要自定义实现 LookupableTableSource 接口,同时实现里面的方法就可以进行,下面来分析一下 LookupableTableSource的代码:
public interface LookupableTableSource<T> extends TableSource<T> {
TableFunction<T> getLookupFunction(String[] lookupKeys);
AsyncTableFunction<T> getAsyncLookupFunction(String[] lookupKeys);
boolean isAsyncEnabled();
}
isAsyncEnabled 方法主要表示该表是否支持异步访问外部数据源获取数据,当返回 true 时,那么在注册到 TableEnvironment 后,使用时会返回异步函数进行调用,当返回 false 时,则使同步访问函数。
可以看到 LookupableTableSource 这个接口中有三个方法
getLookupFunction 方法返回一个同步访问外部数据系统的函数,什么意思呢,就是你通过 Key 去查询外部数据库,需要等到返回数据后才继续处理数据,这会对系统处理的吞吐率有影响。
getAsyncLookupFunction 方法则是返回一个异步的函数,异步访问外部数据系统,获取数据,这能极大的提升系统吞吐率。具体是否要实现异步函数方法,这需要用户自己判定是否需要对异步访问的支持,如果同步方法的吞吐率已经满足要求,那可以先不用考虑异步的实现情况。
2.2 同步访问函数getLookupFunction
getLookupFunction 会返回同步方法,这里你需要自定义 TableFuntion 进行实现,TableFunction 本质是 UDTF,输入一条数据可能返回多条数据,也可能返回一条数据。用户自定义 TableFunction 格式如下:
public class MyLookupFunction extends TableFunction<Row> {
@Override
public void open(FunctionContext context) throws Exception {
super.open(context);
}
public void eval(Object... paramas) {
}
}
open 方法在进行初始化算子实例的进行调用,异步外部数据源的client要在类中定义为 transient,然后在 open 方法中进行初始化,这样每个任务实例都会有一个外部数据源的 client。防止同一个 client 多个任务实例调用,出现线程不安全情况。
eval 则是 TableFunction 最重要的方法,它用于关联外部数据。当程序有一个输入元素时,就会调用eval一次,用户可以将产生的数据使用 collect() 进行发送下游。paramas 的值为用户输入元素的值,比如在 Join 的时候,使用 A.id = B.id and A.name = b.name, B 是维表,A 是用户数据表,paramas 则代表 A.id,A.name 的值。
2.3 异步访问函数
getAsyncLookupFunction 会返回异步访问外部数据源的函数,如果你想使用异步函数,前提是 LookupableTableSource 的 isAsyncEnabled 方法返回 true 才能使用。使用异步函数访问外部数据系统,一般是外部系统有异步访问客户端,如果没有的话,可以自己使用线程池异步访问外部系统。至于为什么使用异步访问函数,无非就是为了提高程序的吞吐量,不需要每条记录访问返回数据后,才去处理下一条记录。异步函数格式如下:
public class MyAsyncLookupFunction extends AsyncTableFunction<Row> {
@Override
public void open(FunctionContext context) throws Exception {
super.open(context);
}
public void eval(CompletableFuture<Collection<Row>> future, Object... params) {
}
}
维表异步访问函数总体和同步函数实现类似,这里说一下注意点:
1. 外部数据源异步客户端初始化。如果是线程安全的(多个客户端一起使用),你可以不加 transient 关键字,初始化一次。否则,你需要加上 transient,不对其进行初始化,而在 open 方法中,为每个 Task 实例初始化一个。
2. eval 方法中多了一个 CompletableFuture,当异步访问完成时,需要调用其方法进行处理.
为了减少每条数据都去访问外部数据系统,提高数据的吞吐量,一般我们会在同步函数和异步函数中加入缓存,如果以前某个关键字访问过外部数据系统,我们将其值放入到缓存中,在缓存没有失效之前,如果该关键字再次进行处理时,直接先访问缓存,有就直接返回,没有再去访问外部数据系统,然后在进行缓存,进一步提升我们实时程序处理的吞吐量。
一般缓存类型有以下几种类型:
- 数据全部缓存,定时更新。
- LRU Cache,设置一个超时时间。
- 用户自定义缓存。
3. 总结
Flink 在 1.9 版本开源出维表功能,用户可以结合自己的具体需求,自定义的去开发维表。Flink 1.9 版本在Flink SQL方面的开源出很多功能,用户可以自己选择具体 Planner进行使用,社区的Planner、Blink的 Planner。希望 Flink 在未来越来越好。
更多精彩内容,欢迎关注我的个人公众号:LakeShen,专注于大数据技术、个人见解、个人经验分享,全部原创首发,如果你有任何问题,也欢迎随时联系我,我会第一时间解答
回复 ‘’Flink‘’,获取我个人整理的 Flink 学习书籍、论文、以及Flink 学习博客推荐。Flink学习,我与你一起前行。
