
列式数据库和行式数据库的区别

前言
最近学习了hbase,其中涉及的到知识就是hbase采用了列式存贮,而用惯了mysql的我当然一脸懵逼,于是有了本篇文章,本文不是论文,所有涉及的知识点他人都有讲,我只是为了记录一下,如果想要看论文性质的,推荐一篇为《Column-Stores vs. Row-Stores: How Different Are They Really?》,可以自行观看,其中有大量的测试,分析,十分详尽。
存贮数据的方式
第一个对比的就是存贮数据的方式。
现来说行式。比如mysql,我们通过观察知道,他是一行一行的存贮的。为了说明这个问题,我们画个图,草图。
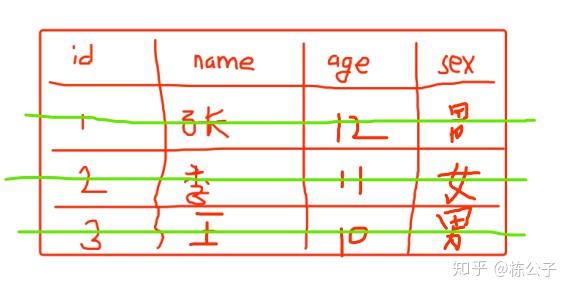

从这个图我们看出,每一行都有id,name,age,sex属性,每一行的所有属性连贯起来存贮起来。即使某一个行某一个字段为空,也会占用一个存贮位置。每一个画绿线的部分里面的数据都被串起来存贮了。比如在北方,蒜这种东西都是被绳子串起来来的,那你现在就可以想象每个绳子串起来的蒜都有id,name,age,sex这四头蒜。
然后再来看列式存贮。画个草图,嗯,是的,很草很草的图。


看上图,这就是列式存贮,发现没有,他是一列都是同一个属性的,是的,看图说话,我感觉已经很明白了哦。再来说到蒜,那么你现在就可以想象每个绳子上的蒜都是同一种,比如这条绳子上的蒜全是id,另外一条绳子上的蒜都是name,以此类推。
是不是很明白的样子。
查询方面的对比
第二个对比的就是查询方面。
先来说行式数据库,通过上面我们知道数据是一行一行的存贮起来的,我们如果想要查询,那么就会一行行的扫描,从而得到我们的数据。还用上面的例子,假定我们只想要name这一行的数据,我们是不是查询的时候也必须把其他的数据顺便给查出来了,因为他们是一起的。那我们就知道了,即使我们只想要一行的数据,也得整行扫描,多的那些数据都是磁盘IO,不得不需要加上额外的不需要的数据。
然后再来说列式数据库,通过上面我们也知道了列式数据库式按照一列一列来存贮的。再来看上面的那个查询问题,我们依旧只想要name这一列,这个时候我们就只需要把这一列查询出来就行了,其他的没有关系的我们也不关心,是不是瞬间就减少了数据量呀,这个优点尤其是在海量数据的时候尤其明显,查询速度秒杀行式数据库。
接着我们再返回行式数据库想一下,比如mysql在做查询优化的时候,最常用的手段就是建立索引,可是我们想一想,数据量一旦大的时候,索引也会成倍的增长。
而列式数据库则不然,他的每一列就是索引,减少了额外建立索引的内容。
当然了,如果我们的需求就是查询所有字段,那个这个时候列式数据库的处理方式就是先把所有列查询出来,然后再拼接起来,速度方面是比不上行式数据库的。不过我们既然用到了列式数据库,那么我们的场景需求就是大量数据,一般在大数据领域,进行所有字段的查询的这个要求少之又少,所以这个缺点我们需要正式,但是我们也可以忽略。
压缩比较
行式数据库因为存贮数据是一行行的来存贮,而每一行数据的差异性太大,所以压缩比很小。列式数据库则不同,因为是按照一列列来存贮,每一列的数据的相同性极高,这就为压缩埋下了很好的种子,压缩比可以达到很大,可以达到5~20倍以上。
接下来看一下网上的一个图来说明问题。
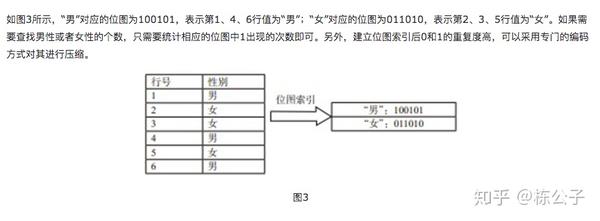

我认为这个压缩比是这种列式存贮在面对海量数据存贮查询的时候灵魂。因为拥有超高的压缩比,在磁盘iO传输的时候,据统计可以达到行式的100倍以上。
当然了,拥有超高的压缩比,另外一方面可以减少磁盘的使用率,不过在现在这个硬盘不值钱的年代,这个优点也不是啥大优点了,最重要的还是在磁盘IO的传输上。
应用场景比较
行式数据库主要应用于传统的业务场景中
列式数据库则应该发挥他查询速度方面的优势,主要用于海量数据分析一类的方面。
总结
以上就是本文全部的内容了,如果读者有补充,也欢迎在下方留言,与几方便也与他方便,共同进步咯。
