HashMap源码分析(jdk1.8,保证你能看懂)

现在的面试当中凡是那些大厂,基本上都会问到一些关于HashMap的问题了,而且这个集合在开发中也经常会使用到。于是花费了大量的时间去研究分析写了这篇文章。本文是基于jdk1.8来分析的。篇幅较长,但是都是循序渐进的。耐心读完相信你会有所收获。
一、带着问题分析
这篇文章,希望能解决以下问题。
(1)HashMap的底层数据结构是什么?
(2)HashMap中增删改查操作的底部实现原理是什么?
(3)HashMap是如何实现扩容的?
(4)HashMap是如何解决hash冲突的?
(7)HashMap为什么是非线程安全的?
下面我们就带着这些问题,揭开HashMap的面纱。
二、认识HashMap
HashMap最早是在jdk1.2中开始出现的,一直到jdk1.7一直没有太大的变化。但是到了jdk1.8突然进行了一个很大的改动。其中一个最显著的改动就是:
之前jdk1.7的存储结构是数组+链表,到了jdk1.8变成了数组+链表+红黑树。
另外,HashMap是非线程安全的,也就是说在多个线程同时对HashMap中的某个元素进行增删改操作的时候,是不能保证数据的一致性的。
下面我们就开始一步一步的分析。
三、深入分析HashMap
1、底层数据结构
为了进行一个对比分析,我们先给出一个jdk1.7的存储结构图


从上图我们可以看到,在jdk1.7中,首先是把元素放在一个个数组里面,后来存放的数据元素越来越多,于是就出现了链表,对于数组中的每一个元素,都可以有一条链表来存储元素。这就是有名的“拉链式”存储方法。
就这样用了几年,后来存储的元素越来越多,链表也越来越长,在查找一个元素时候效率不仅没有提高(链表不适合查找,适合增删),反倒是下降了不少,于是就对这条链表进行了一个改进。如何改进呢?就是把这条链表变成一个适合查找的树形结构,没错就是红黑树。于是HashMap的存储数据结构就变成了下面的这种。
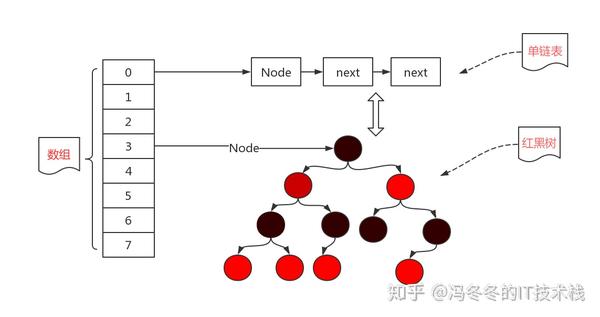
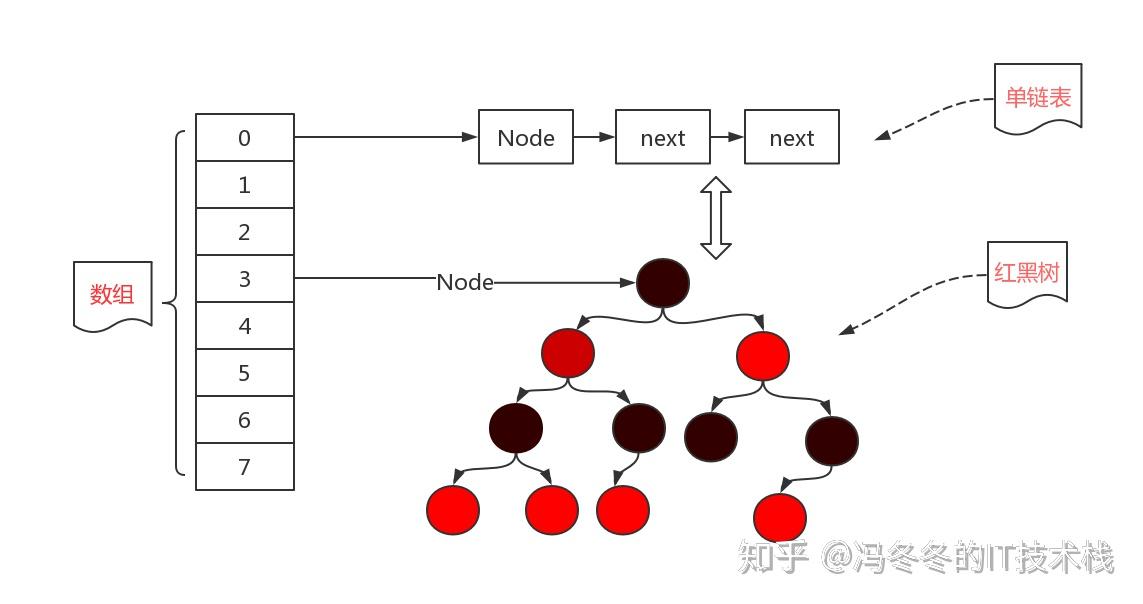
我们会发现优化的部分就是把链表结构变成了红黑树。原来jdk1.7的优点是增删效率高,于是在jdk1.8的时候,不仅仅增删效率高,而且查找效率也提升了。
注意:不是说变成了红黑树效率就一定提高了,只有在链表的长度不小于8,而且数组的长度不小于64的时候才会将链表转化为红黑树,
问题一:什么是红黑树呢?
红黑树是一个自平衡的二叉查找树,也就是说红黑树的查找效率是非常的高,查找效率会从链表的o(n)降低为o(logn)。如果之前没有了解过红黑树的话,也没关系,你就记住红黑树的查找效率很高就OK了。
问题二:为什么不一下子把整个链表变为红黑树呢?
这个问题的意思是这样的,就是

