
在深度学习中喂饱gpu

前段时间训练了不少模型,发现并不是大力出奇迹,显卡越多越好,有时候1张v100和2张v100可能没有什么区别,后来发现瓶颈在其他地方,写篇文章来总结一下自己用过的一些小trick,最后的效果就是在cifar上面跑vgg的时间从一天缩到了一个小时,imagenet上跑mobilenet模型只需要2分钟每个epoch。(文章末尾有代码啦)
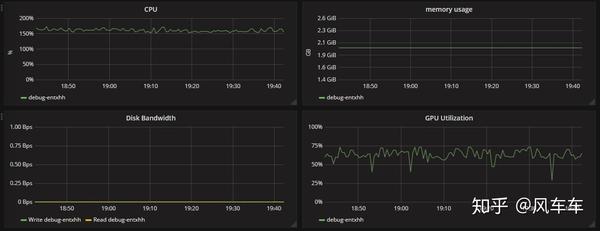
先说下跑cifar的时候,如果只是用torchvision的dataloader(用最常见的padding/crop/flip做数据增强)会很慢,大概速度是下面这种,600个epoch差不多要一天多才能跑完,并且速度时快时慢很不稳定。


我最初以为是IO的原因,于是挂载了一块内存盘,改了一下路径接着用torchvision的dataloader来跑,速度基本没啥变化。。。


然后打开资源使用率看了下发现cpu使用率几乎已经满了(只能申请2cpu和一张v100...),但是gpu的使用率非常低,这基本可以确定瓶颈是在cpu的处理速度上了。
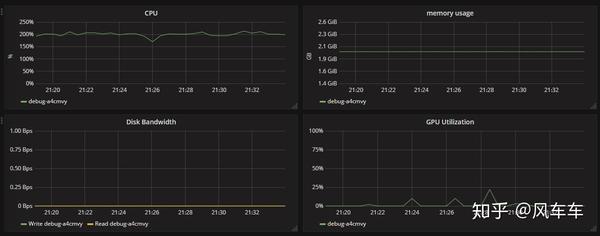

后来查了一些资料发现nvidia有一个库叫dali可以用gpu来做图像的前处理,从输入,解码到transform的一整套pipeline,看了下常见的操作比如pad/crop之类的还挺全的,并且支持pytorch/caffe/mxnet等各种框架。
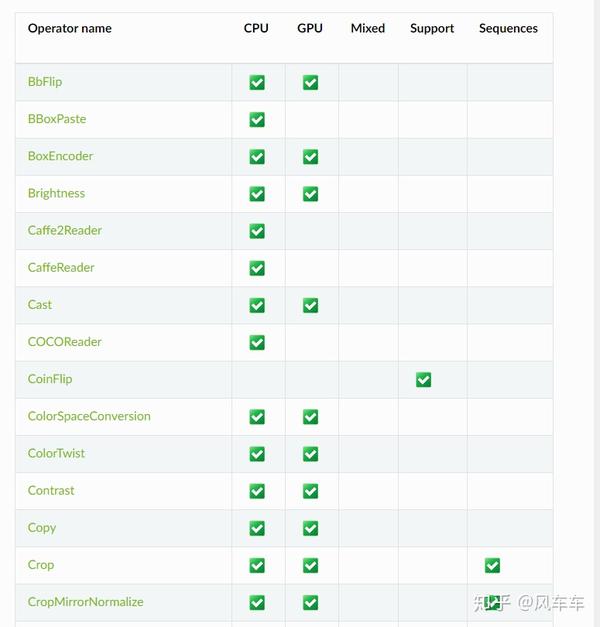

可惜在官方文档中没找到cifar的pipeline,于是自己照着imagenet的版本写了个,最初踩了一些坑(为了省事找了个cifar的jpeg版本来解码,发现精度掉得很多还找不到原因,还得从cifar的二进制文件来读取),最后总归是达到了同样的精度,再来看一看速度和资源使用率,总时间直接从一天缩短为一小时,并且gpu使用率高了很多。



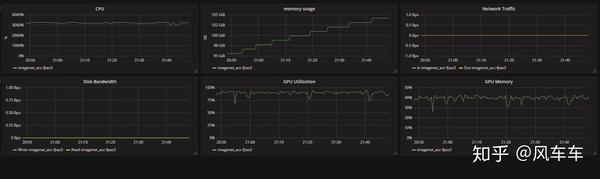
再说下imagenet的训练加速,最初也是把整个数据集拷到了挂载的内存盘里面(160g大概够用了,从拷贝到解压完成大概10分钟不到),发现同样用torchvision的dataloader训练很不稳定,于是直接照搬了dali官方的dataloader过来,速度也是同样起飞hhhh(找不到当时训练的图片了),然后再配合apex的混合精度和分布式训练,申请4块v100,gpu使用率可以稳定在95以上,8块v100可以稳定在90以上,最后直接上到16张v100和32cpu,大概也能稳定在85左右(看资源使用率发现cpu到顶了,不然估计gpu也能到95以上),16块v100在ImageNet上跑mobilenet只需要2分钟每个epoch。

写的dataloader放到了github上,我测试的精度跟torchvision的版本差不多,不过速度上会比torchvision快很多,后面有空也会写一些其他常用dataloader的dali版本放上去