
LightGBM+gridsearchcv调参

本人最近在项目中用到的LightGBM比较多,总结下在使用LightGBM时的调参经验,也希望能够抛砖引玉,多学习学习大家在工作中的经验。
一 LightGBM核心参数
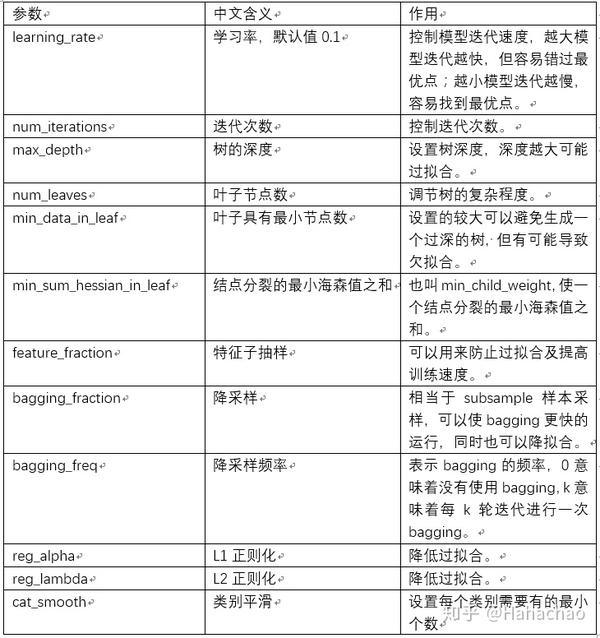

二 gridsearchcv工作机制
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。
这两个概念都比较好理解,网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个循环和比较的过程。
GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,它要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。
交叉验证的概念也很简单:
- 将训练数据集划分为K份,K一般为10(我个人取3到5比较多) ;
- 依次取其中一份为验证集,其余为训练集训练分类器,测试分类器在验证集上的精度 ;
- 取K次实验的平均精度为该分类器的平均精度。
参数名称及含义如下:
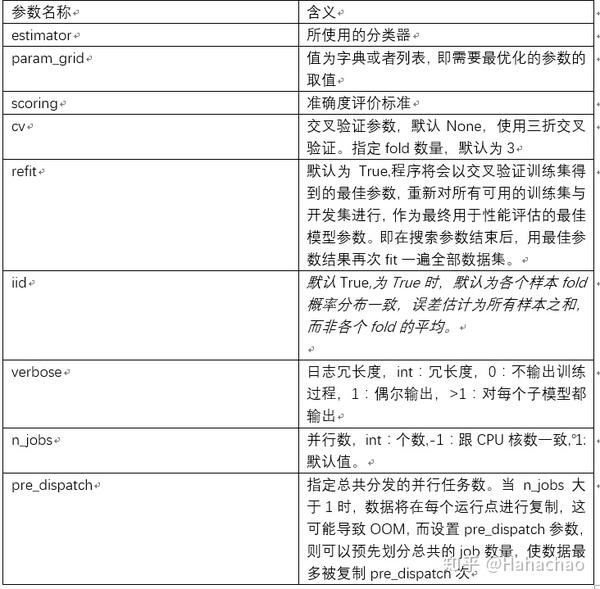
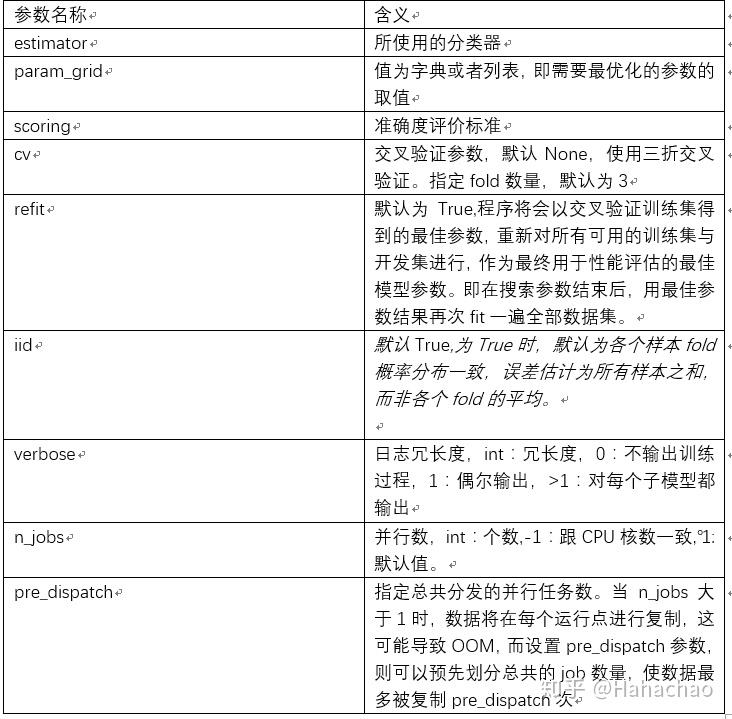
三 使用gridsearchcv对lightgbm调参
对于基于决策树的模型,调参的方法都是大同小异。一般都需要如下步骤:
- 首先选择较高的学习率,大概0.1附近,这样是为了加快收敛的速度。这对于调参是很有必要的。
- 对决策树基本参数调参
- 正则化参数调参
- 最后降低学习率,这里是为了最后提高准确率
下面我们以具体的案例来操作一把,手头上正好有个根据用户的浏览行为,预测其下单概率的项目。首先,我们需要设置一些默认参数,可以用以往项目中的参数,也可以直接使用lightGBM的默认参数。
本人一般使用的默认参数如下:
objective = 'binary',
is_unbalance = True,
metric = 'binary_logloss,auc',
max_depth = 6,
num_leaves = 40,
learning_rate = 0.1,
feature_fraction = 0.7,
min_child_samples=21,
min_child_weight=0.001,
bagging_fraction = 1,
bagging_freq = 2,
reg_alpha = 0.001,
reg_lambda = 8,
cat_smooth = 0,
num_iterations = 200,
开始时,需要把学习率和迭代次数调整到一个比较大的值。本人一般刚开始时设置learning_rate=0.1,num_iterations = 200。
Step 1 调整max_depth 和 num_leaves
这两个参数基本可以确定树的大小及复杂度,可以同时调整,代码如下:
parameters = {
'max_depth': [4,6,8],
'num_leaves': [20,30,40],
}
gbm = lgb.LGBMClassifier(objective = 'binary',
is_unbalance = True,
metric = 'binary_logloss,auc',
max_depth = 6,
num_leaves = 40,
learning_rate = 0.1,
feature_fraction = 0.7,
min_child_samples=21,
min_child_weight=0.001,
bagging_fraction = 1,
bagging_freq = 2,
reg_alpha = 0.001,
reg_lambda = 8,
cat_smooth = 0,
num_iterations = 200,
)
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='roc_auc', cv=3)
gsearch.fit(X_0_train, Y_0_train)
print('参数的最佳取值:{0}'.format(gsearch.best_params_))
print('最佳模型得分:{0}'.format(gsearch.best_score_))
print(gsearch.cv_results_['mean_test_score'])
print(gsearch.cv_results_['params'])
Step2 调整min_data_in_leaf 和 min_sum_hessian_in_leaf
该步骤主要是防止树过拟合。代码如下:
parameters = {
‘min_child_samples’: [18,19,20,21,22],
‘min_child_weight’:[ [0.001,0.002]
}
gbm = lgb.LGBMClassifier(objective = 'binary',
is_unbalance = True,
metric = 'binary_logloss,auc',
max_depth = 6,
num_leaves = 40,
learning_rate = 0.1,
feature_fraction = 0.7,
min_child_samples=21,
min_child_weight=0.001,
bagging_fraction = 1,
bagging_freq = 2,
reg_alpha = 0.001,
reg_lambda = 8,
cat_smooth = 0,
num_iterations = 200,
)
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='roc_auc', cv=3)
gsearch.fit(X_0_train, Y_0_train)
print('参数的最佳取值:{0}'.format(gsearch.best_params_))
print('最佳模型得分:{0}'.format(gsearch.best_score_))
print(gsearch.cv_results_['mean_test_score'])
print(gsearch.cv_results_['params'])
Step 3 调整feature_fraction
该步骤主要是通过随机选择一定比列的特征去模型中,防止过拟合。
parameters = {
'feature_fraction': [0.6, 0.8, 1],
}
gbm = lgb.LGBMClassifier(objective = 'binary',
is_unbalance = True,
metric = 'binary_logloss,auc',
max_depth = 6,
num_leaves = 40,
learning_rate = 0.1,
feature_fraction = 0.7,
min_child_samples=21,
min_child_weight=0.001,
bagging_fraction = 1,
bagging_freq = 2,
reg_alpha = 0.001,
reg_lambda = 8,
cat_smooth = 0,
num_iterations = 200,
)
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='roc_auc', cv=3)
gsearch.fit(X_0_train, Y_0_train)
print('参数的最佳取值:{0}'.format(gsearch.best_params_))
print('最佳模型得分:{0}'.format(gsearch.best_score_))
print(gsearch.cv_results_['mean_test_score'])
print(gsearch.cv_results_['params'])
Step 4 调整bagging_fraction和bagging_freq
bagging_fraction+bagging_freq参数必须同时设置,bagging_fraction相当于subsample样本采样,可以使bagging更快的运行,同时也可以降拟合。bagging_freq默认0,表示bagging的频率,0意味着没有使用bagging,k意味着每k轮迭代进行一次bagging。
parameters = {
'bagging_fraction': [0.8,0.9,1],
'bagging_freq': [2,3,4],
}
gbm = lgb.LGBMClassifier(objective = 'binary',
is_unbalance = True,
metric = 'binary_logloss,auc',
max_depth = 6,
num_leaves = 40,
learning_rate = 0.1,
feature_fraction = 0.7,
min_child_samples=21,
min_child_weight=0.001,
bagging_fraction = 1,
bagging_freq = 2,
reg_alpha = 0.001,
reg_lambda = 8,
cat_smooth = 0,
num_iterations = 350,
)
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='roc_auc', cv=3)
gsearch.fit(X_0_train, Y_0_train)
print('参数的最佳取值:{0}'.format(gsearch.best_params_))
print('最佳模型得分:{0}'.format(gsearch.best_score_))
print(gsearch.cv_results_['mean_test_score'])
print(gsearch.cv_results_['params'])
Step 5 调整lambda_l1(reg_alpha)和lambda_l2(reg_lambda)
本步骤通过L1正则化和L2正则化降低过拟合。
parameters = {
'bagging_fraction': [0.8,0.9,1],
'bagging_freq': [2,3,4],
}
gbm = lgb.LGBMClassifier(objective = 'binary',
is_unbalance = True,
metric = 'binary_logloss,auc',
max_depth = 6,
num_leaves = 40,
learning_rate = 0.1,
feature_fraction = 0.7,
min_child_samples=21,
min_child_weight=0.001,
bagging_fraction = 1,
bagging_freq = 2,
reg_alpha = 0.001,
reg_lambda = 8,
cat_smooth = 0,
num_iterations = 350,
)
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='roc_auc', cv=3)
gsearch.fit(X_0_train, Y_0_train)
print('参数的最佳取值:{0}'.format(gsearch.best_params_))
print('最佳模型得分:{0}'.format(gsearch.best_score_))
print(gsearch.cv_results_['mean_test_score'])
print(gsearch.cv_results_['params'])
Step 6 调整cat_smooth
cat_smooth为设置每个类别拥有最小的个数,主要用于去噪。
parameters = {
'cat_smooth': [0,10,20],
}
gbm = lgb.LGBMClassifier(objective = 'binary',
is_unbalance = True,
metric = 'binary_logloss,auc',
max_depth = 6,
num_leaves = 40,
learning_rate = 0.1,
feature_fraction = 0.7,
min_child_samples=21,
min_child_weight=0.001,
bagging_fraction = 1,
bagging_freq = 2,
reg_alpha = 0.001,
reg_lambda = 8,
cat_smooth = 0,
num_iterations = 200,
)
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='roc_auc', cv=3)
gsearch.fit(X_0_train, Y_0_train)
print('参数的最佳取值:{0}'.format(gsearch.best_params_))
print('最佳模型得分:{0}'.format(gsearch.best_score_))
print(gsearch.cv_results_['mean_test_score'])
print(gsearch.cv_results_['params'])
Step 7 最后,本人会适当调小learning_rate的值以及调整num_iterations的大小。
参考:
https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
