
数据分析|如何做一个ABtest测验

A/B-test是为同一个目标制定两个方案,在同一时间维度,分别让组成成分相同(相似)的用户群组随机的使用一个方案,收集各群组的用户体验数据和业务数据,最后根据显著性检验分析评估出最好版本正式采用。
A/B-test显著性检验
随机将测试用户群分为2部分,用户群1使用A方案,用户群2使用B方案,经过一定测试时间后,根据收集到的两方案样本观测数据,根据显著性检验结果选取最好方案。
为了下文方便说明,我们不妨设A方案为参考方案(或旧方案),B方案为实验方案(或新方案)。
由于每次实验结果要么转化成功,要么失败,所以A,B的分布可看作是伯努利分布;
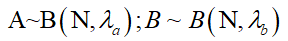
我们知道,二项分布当n--> \infty ,可以近似的看作服从正态分布;其均值方差为:u=np,\sigma^{2}=np(1-p)
假设,A方案的人数为 N_{a} ,B方案的人数为 N_{b} ( N_{a}=N_{b}=N );
由样本计算出A/B方案的签到率:
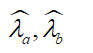
假设检验:
按照假设检验的“套路”,H1是我们想要的假设,H0是要拒绝的假设:

由于是双样本均值显著性检测,我们可以用Z检验:

\sigma_a,\sigma_b,\lambda_{a},\lambda_{b}都是业务沉淀获得的先验数据,或是先做一次测试,对这些值进行估计。
单侧检验值,当显著性水平为0.05时, Z_{a}=1.645
当 Z_{a}>Z_{c} ,拒绝原假设;反之,则不能拒绝原假设;
还有一个重要的问题,那就是如何选择样本量,我们最低抽取多少人做ABtest?
如何确定分配多少样本量?
样本量太小,得出的结论不靠谱,容易受到偶然因素影响;
样本量太大,大公司AB测试很多,样本有限,且样本量大,试错成本就大!
网上提供的AB测试样本量计算器:
l Statistical power(1-β)
l Significance Level (α)Statistical Significance(1-α)
l Baseline rate(conversation rate)
l Minimum detectable effect


由于判断错了,我们把这类错误叫做第一类错误(Type I error),我们把第一类错误出现的概率用α表示。这个α,就是Significance Level。一般选择5%,即保证第一类错误的概率不超过5%。Statistical Significance=1-level,表示有多大的把握不冤枉好人!
判断正确。我们把做出这类正确判断的概率叫做Statistical Power。这一个一般要大!
我们的判断又错了。这类错误叫做第二类错误(Type II error),用β表示。根据条件概率的定义,可以计算出β = 1 - power。
总结一下,对于我们的实验:
· 第一类错误α不超过5%。也就是说Statistical Significance =1-α=95%
· 第二类错误β不超过20%。也就是说,Statistical Power = 1 -β = 80%。
对α与β的理解:
对两类错误上限的选取(α是5%,β是20%),我们可以了解到A/B实验的重要理念:宁肯砍掉4个好的产品,也不应该让1个不好的产品上线。
baseline Rate:
这个看的是在实验开始之前,对照组本身的表现情况。在我们的实验里,baseline就是旧方案的点击率;
l 这个参数越小,你需要的样本量越大(分母越大,这个参数越小)
l 这个参数越大,你需要的样本量越小
在工作中,这个参数完全是历史数据决定的。在我们的实验中,我们假定,实验开始之前的历史点击率是5%。所以Baseline Rate=5%。
Minimum Detectable Effect
顾名思义,这个参数衡量了我们对实验的判断精确度的最低要求。
l 参数越大(比如10%),说明我们期望实验能够检测出10%的差别即可。检测这么大的差别当然比较容易(power变大),所以保持power不变的情况下,所需要的样本量会变小。
l 参数越小(比如1%),说明我们希望实验可以有能力检测出1%的细微差别。检测细微的差别当然更加困难(power变小)所以样本量越大,所以如果要保持power不变的话,需要的样本量会增加。
在工作中,这个参数的选定往往需要和业务方一起拍板。在我们的实验中,我们选定Minimum Detectable Effect=5%。这意味着,如果“签到赚钱”真的提高了点击率5个百分点以上,我们希望实验能够有足够把握检测出这个差别。如果低于5个百分点,我们会觉得这个差别对产品的改进意义不大(可能是因为点击率不是核心指标),能不能检测出来也就无所谓了。

假设检验还可以这样做(如果假设都能满足的话)
某公司想知道产品优化是否有效,设立实验组与对照组收集一周点击率,请检验产品优化是否有效
实验组7天点击率分别为:0.72,0.75,0.7,0.75,0.73,0.72,0.71
对照组7天点击率分别为:0.7,0.76,0.69,0.75,0.7,0.69,0.68
由于不同统计日之间是有随机波动的差异,而且实验组和对照组流量相等且随机,可以认为样本来自同一个总体,实验组是对同一天的对照组进行优化的结果,所以可以采用相关样本t检验。
Step1:
H0:功能优化之后与优化前没有差异(μ2-μ1=0)
H1:功能优化之后与优化前有差异(μ2-μ1≠0)
μ为点击率
Step2:确定显著性水平α=0.05
Step3:计算统计量,相关样本t检验是以每一组数据的差值作为检验的,所以以点击率差作检验
day1:0.72-0.7=0.02 …… day7:0.71-0.68=0.03
Md为七组差值的均值,经计算为0.0157;样本方差(0.02-0.016)^2+……+(0.03- 0.016)^2/(7-1)=0.000262,开根号得到标准误=0.0161最后代入t分数:t=(0.0157-0)*sqrt(n-1)/0.0161=2.38
Step4:查表,按α=0.05,df=6,确定临界值,2.447。Step3中的t=2.38在临界值内,接受零假设,认为功能优化没有效果。
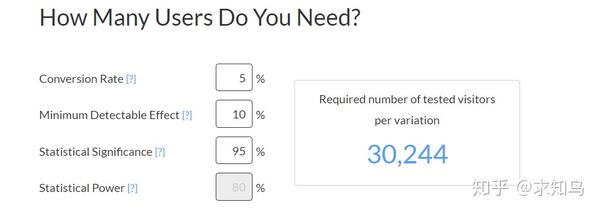
如何选择采用哪种假设检验?
Z检验:一般用于大样本(即样本容量大于30)平均值差异性检验的方法。它是用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数的差异是否显著。在国内也被称作u检验。
T检验:主要用于样本含量较小(例如n < 30),总体标准差σ未知的正态分布。T检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
卡方检验:卡方检验是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。



如何用Python实现AB测试?
服从什么分布,就用什么区间估计方式,也就就用什么检验!
比如:两个样本方差比服从F分布,区间估计就采用F分布计算临界值(从而得出置信区间),最终采用F检验。

实例背景简述:
某司「猜你想看」业务接入了的新推荐算法,新推荐策略算法开发完成后,在全流量上线之前要评估新推荐策略的优劣,所用的评估方法是A/B test,具体做法是在全量中抽样出两份小流量,分别走新推荐策略分支和旧推荐策略分支,通过对比这两份流量下的指标(这里按用户点击衡量)的差异,可以评估出新策略的优劣,进而决定新策略是否全适合全流量。
实例A/B test步骤:
指标:CTR
变体:新的推荐策略
假设:新的推荐策略可以带来更多的用户点击。
收集数据:以下B组数据为我们想验证的新的策略结果数据,A组数据为旧的策略结果数据。均为伪造数据。
我们是想证明新开发的策略B效果更好,所以可以设置原假设和备择假设分别是:
H0:A>=B
H1:A < B
利用 python 中的 scipy.stats.ttest_ind 做关于两组数据的双边 t 检验,为了得到单边检验的结果,需要将 计算出来的 pvalue 除于2 取单边的结果(这里取阈值为0.05)。
from scipy import stats
import numpy as np
import numpy as np
import seaborn as sns
A = np.array([ 1, 4, 2, 3, 5, 5, 5, 7, 8, 9,10,18])
B = np.array([ 1, 2, 5, 6, 8, 10, 13, 14, 17, 20,13,8])
print('策略A的均值是:',np.mean(A))
print('策略B的均值是:',np.mean(B))
'''
策略A的均值是: 6.416666666666667
策略B的均值是: 9.75
'''
import scipy.stats
t, pval = scipy.stats.ttest_ind(B,A) #表示B-A
print(t,pval)
'''
1.556783470104261 0.13379164919826217
'''根据 scipy.stats.ttest_ind(x, y) 文档的解释,这是双边检验的结果。为了得到单边检验的结果,需要将 计算出来的 pvalue 除于2 取单边的结果(这里取阈值为0.05)。
求得pvalue=0.13462981561745652,p/2 > alpha(0.05),所以不能够拒绝假设,暂时不能够认为策略B能带来多的用户点击。
参考文献:
https://blog.csdn.net/buracag_mc/article/details/74905483
这篇文章将AB-test的商业逻辑讲的很清楚,我反复看了这篇文章,其中有很多细节可以商榷,但足够致命!
以下是我对AB-test显著性检测的想法(欢迎指正):
A/Btest,如果不能保证足够多的试验次数,和足够大的样本量,将没有任何意义。实际上,假设检验的前提条件过于完美,需要样本服从独立同分布;假设检验P<0.05, 也不能拒绝H0,因为独立同分布的假设压根无从验证。再说,0.05的合法性?实际上是拍脑袋出来的。现在学术界已经在science上专门批评了假设检验。。。 文章中对检验统计量的推导,可以直接说是双样本均值检验可以使用Z检验。 样本估计值方差用Np(1-p),其实也做了前提假设(假设样本足够大,可以用正态分布替换二项分布);我们实际可以做600次实验(实验周期可以短),每次实验抽取1000个人,这样可以得到600组均值,这600组均值才可以看作是正态分布。
最低样本量的计算:在一系列先验假定下求出的。
参考下工业界ABtest的流程;
怎么圈定哪些用户进行 A 实验,哪些用户进行 B 实验。可以采用hash算法用自增ID来圈定用户,这样进行孤立实验可以,一份流量只能用来做一个测验。目前,业界提出了可重叠分层分桶方法。
具体来说,就是将流量分成可重叠的多个层。因为很多类实验从修改的系统参数到观察的产品指标都是不相关的,完全可以将实验分成互相独立的多个层。例如 UI 层、推荐算法层、广告算法层,或者开屏、首页、购物车、结算页等。
单单分层还不够,在每个层中需要使用不同的随机分桶算法,保证流量在不同层中是正交的。也就是说,一个用户在每个层中应该分到哪个桶里,是独立不相关的。具体来说,在上一层 001 桶的所有用户,理论上应该均匀地随机分布在下一层的 1000 个桶中。
通过可重叠的分层分桶方法,一份流量通过 N 个层可以同时中 N 个实验,而且实验之间相互不干扰,能显著提升流量利用率。
ABTest 实验开关和数据收集的一些实现,从流量划分、到实验开关、到数据收集,基本实现了 ABTest 的主要功能。
ABTest实验设计时需要注意的问题;
后记:
回归分析中的假设检验和机器学习模型的过拟合问题,是核心!!!压倒一切!如果这两点在一本书中没有讲清楚,那这本书将完全没有意义,可以视作垃圾!
假设检验根本讲不清,因为不是假设检验的逻辑有问题,而是假设根本无从验证!
欢迎批评指正,如果没有批评,那我写这些东西将毫无意义!!!
@ 看到本文的你,去做一个敢于质疑的人吧,不然学习将毫无乐趣!
