
BERT生成式之MASS解读

距离上篇文章又一个月了。。。时光飞逝。。。再次立下一周一篇的flag
最近读了一篇专栏文章BERT时代与后时代的NLP,收获颇丰。算是作者的同行,最近也在做类似的东西,但是作者都给总结了起来,让我又重新串了一遍那些思想,查漏补缺。另外最近没怎么追踪前沿,看到作者又列举了两篇我一直关注的transformer系文章,赶紧打出来看了,顺便写篇文章记录下收获。
1. MASS模型
MASS的主要贡献是提出一种新的Pre-train seq2seq任务的方法。
BERT的成功把nlp带向了pretrain+finetune时代,而对于文本生成任务(机器翻译、文本摘要、生成问答),由于语料对较少,更需要使用pretrain的模型来减少标注代价。
看到这里的读者可以先自己想一下如何pretrain seq2seq的任务。大家首先能想到的估计就是BERT+LM,因为BERT的编码能力比其他BiLM的能力强一些。但这样pretrain的问题就是,如果我们的语料是unsupervised,就要分开预训练encoder和decoder,可能会导致两者的分布不一致。
于是MASS的作者就借鉴了Masked LM的思想,只用一句话就让encoder和decoder同时训练。具体做法是mask掉句子的一部分x,再用decoder去预测x,如下图:
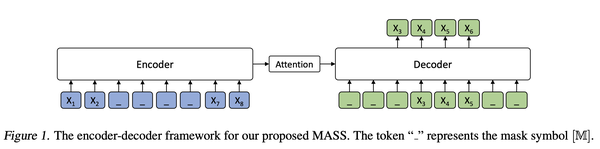

注意,在经典的seq2seq结构中,decoder的输入都是完整的,而这里只输入应该被预测的token,作者的解释是这样可以让decoder依赖于encoder的编码,让两者更好地共同训练。
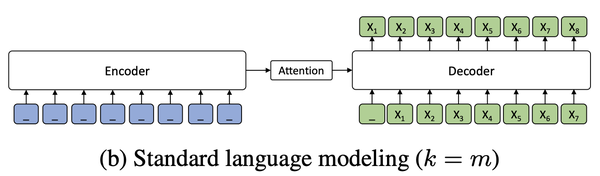
之后,作者更进一步,居然把BERT和GPT统一了起来:
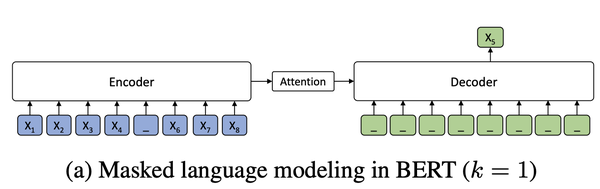


图a): 可能会有同学觉得decoder不是双向的,没法把encoder和decoder看成BERT,但其实只把encoder看成BERT就可以,decoder看作classifier层。
图b): 单向LM(GPT),从左到右进行预测,encoder没有给decoder任何信息。
2. 实验细节
- 语言:因为要应用到机器翻译任务,所以预训练模型采用4种语言,作者把四种语言同时进行Byte-Pair Encoding,生成一个60k的词表。在预训练的时候也是同时用四种语言的语料,即一个batch是32*4个句子。
- Mask策略:从随机一个位置开始,连续mask掉句子长度50%的tokens(经过实验验证较优)。且参考BERT的策略,80%的时间用[M],10%用随机的token,10%保留原token。
- Decoder优化:因为预测的token都是连续的,在训练decoder时可以直接把padding去掉,但要注意保留positional encoding,这样可以节省50%的时间。
- 预训练LR=1e-4,NMT的精调LR=1e-4。(感觉精调的LR应该小一些吧)
3. 结论
- MASS达到了机器翻译的新SOTA
- MASS > BERT+LM式的预训练
- mask掉连续的token,可以得到更好的语言建模能力(已实验验证)
- 只让decoder从encoder侧获取信息,得到的模型效果更好(已实验验证)
总体来讲,MASS还是给我开阔了新的思路(毕竟我没什么思路),其实仔细想这个想法也是不难想出来的,关键还是要动手去验证,并且花心思去提升效果,细节见英雄。

