ExtremeNet

论文:Bottom-up Object Detection by Grouping Extreme and Center Points
目标检测任务中,往往使用bbox来定位目标,但是目标形状通常是任意的,并且可能放置不正(以目标中心旋转一定角度),如图1,使用bbox定位引入很多背景pixels,不能准确地传递目标的shape和pose信息。


这篇论文作者介绍了ExtremeNet,检测目标的上下左右四个极点,具体而言,网络为每个目标分类(比如COCO则是80)分别生成 上下左右 四个极点的heatmap,此外还为每个分类生成一个用于预测是否是目标中心的heatmap。显然,预测上下左右四个极点的heatmap是独立进行的,如何将四个极点group进一个目标,则需要预测中心heatmap的辅助。我们知道,上下两个极点y坐标的均值,表示center的y坐标,左右两个极点x坐标的均值,表示center的x坐标,所以对于一组上下左右四个极点,我们可以得到其center坐标,然后对应到center heatmap上的值,如果超过一定的阈值,就认为这四个极点属于同一目标。实现时,四个极点分别选择top n个location,枚举 O(n^4) 种组合然后依上述方法进行grouping。n的选择必须小,否则影响计算效率,对于COCO数据集,作者设置 n=40。图2是本文所提方法的概览,
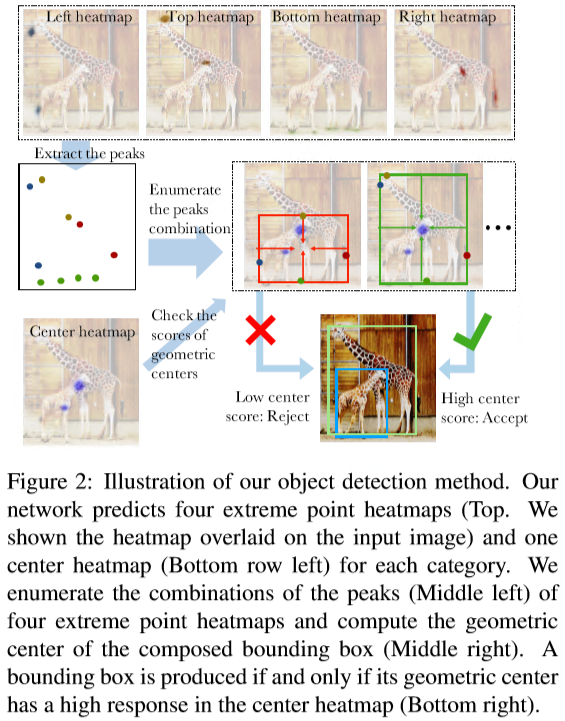

使用关键点预测目标的方法比如之前的CornerNet,是预测左上右下两个对角点,然后根据两个角点的embedding feature判断是否属于同一目标。ExtremeNet与CornerNet的区别在于:
- 预测目标的关键点选取不同。前者是四个极点,后者是两个对角点
- grouping关键点的方法不同。前者是基于纯几何的方法,后者embedding则是映射到抽象空间,需要隐形特征学习。
Corner其实是bbox的另一种形式,所以继承了bbox的缺点。corner通常位于目标外部,不带有较强的目标特征,而extreme point则因为位于目标上,视觉上容易(与背景)区分,且具有一致的局部特征,比如人的top-most 点通常都是head,而汽车或者飞机的bottom-most点则是轮子,这使得 极点检测 更加容易。
极点和中心点
记 (x^{(tl)}, y^{(tl)}, x^{(br)}, y^{(br)}) 表示bbox的四条边。标注一个bbox,通常是点击左上角 (x^{(tl)}, y^{(tl)}) 和右下角 (x^{(br)}, y^{(br)}) ,由于这两点位于目标之外,所以点击角点很难一次准确,往往需要调整几次。因为极点位于目标边缘,使用极点标注bbox则简单得多,记四个极点 (x^{(t)}, y^{(t)}), (x^{(l)}, y^{(l)}),(x^{(b)}, y^{(b)}), (x^{(r)}, y^{(r)}) ,那么bbox可表示为 (x^{(l)}, y^{(t)}, x^{(r)}, y^{(b)}) 。一个点 (x^{(a)},y^{(a)}) 是 a 型极点如果:沿着 a 方向不存在位于目标上其他点, a\in \{top,bottom,left,right\} 。给定这四个极点后,那么对应的中心点坐标为 (\frac {x^{(l)}+x^{(r)}} 2, \frac {y^{(t)}+y^{(b)}} 2) 。
关键点检测
通常为每个关键点生成一个多通道heatmap,每个channel对应一个分类(比如COCO数据集则是80个分类,注意,没有额外的bg分类)。损失函数可以使用L2损失,或者使用per-pixel的logistic 回归损失(交叉熵),记预测heatmap为 \hat {\mathbf Y} , \mathbf Y 为ground truth heatmap,这是一个Gaussian map,在gt 关键点处具有峰值。使用104层的HourglassNet作为backbone,生成size为 H \times W 的heatmap,即 \hat {\mathbf Y} \in (0,1)^{H \times W} 。GT heatmap是多峰值的Gaussian map,每个关键点决定对应高斯核的均值,而高斯核的标准差则可以取一固定值,或者正比于目标size。GT Gaussian heatmap既可以用作L2损失中的回归目标,也可以用作logistic回归中交叉熵损失的weight map(参考CornerNet中相关讨论)。
与CornerNet类似,使用检测部分的损失 L_{det} 和坐标偏差的损失 L_{off} ,由于grouping方法不同,所以没有embedding的损失,即,没有 L_{push}, L_{pull} 。
ExtremeNet目标检测
ExtremeNet使用Hourglass为每个分类检测5个关键点(包括4个极点和1个中心点)。训练步骤与CornerNet中一样,与极点检测不同的是,坐标offset是分类无关的。中心点heatmap没有对应的offset。网络的输出为 5 \times C heatmaps 以及 4 \times 2 offset maps,其中 C 是分类数量, 5 表示4个极点1个中心点, 4 \times 2 表示4个极点,每个极点2个坐标偏差(x,y轴),如图3所示,


Center Grouping
四个极点分布在目标的四条边上,grouping过程比CornerNet中两个角点的grouping复杂些。对于CornerNet中的embedding,可以使用L1范数作为两个embedding的距离,越小相关度越高,但是四个极点的embedding,我感觉要两两距离都很小才能说明四个极点互相相关,计算复杂度直接从 O(1) 变成 O(C_4^2) ,所以作者使用不同的方法。
每个分类有5个heatmaps,记center heatmap为 \hat {\mathbf Y^{(c)}} \in (0,1)^{H \times W} ,四个极点heatmaps为 \hat {\mathbf Y^{(t)}}, \hat {\mathbf Y^{(l)}},\hat {\mathbf Y^{(b)}},\hat {\mathbf Y^{(r)}} \in (0,1)^{H \times W} ,给定一个heatmap,通过检测峰值从而得到候补关键点,峰值定义为:heatmap上某个location处的值超过一定阈值 \tau_p ,并且在以这个location为中心的 3x3 窗口内是最大值。检测峰值的过程称为ExtrectPeak(单词拼写错了。。。)
从四个极点预测heatmaps上分别检测到n个关键点(ExtrectPeak之后取top n即可),那么一共有 n^4 种组合,记某组关键点为 t,b,r,l ,那么得到几何中心点为 c=(\frac {l_x+r_x} 2 , \frac {t_y+b_y} 2) ,如果这个中心点在center heatmap上的值大于一定阈值: \hat {Y^{(c)}}_{c_x,c_y} \ge \tau_c ,那么这组关键点是有效的,即,属于同一个目标。
以上过程对每个分类独立进行。整个算法流程如下,


实验中作者设置 \tau_p=0.1, \ \tau_c=0.1 。
Ghost box suppression
通过上述基于center 的grouping方法可能会得到一些高置信度但其实是假阳性的检测。如下图,顶部三个实线框是表示三个gt bbox,底部虚线box则是ghost box,
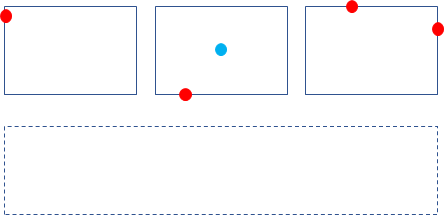

当使用图中顶部的一组 t,l,b,r 关键点时,其几何中心处确实是位于某个gt bbox的中心,故根据这组关键点得到顶部的虚线表示的bbox,训练阶段可以知道这个虚线box是不是假阳性检测。测试阶段,并不知道这个虚线box是不是gt bbox,所以是选择顶部中间的实线box作为检测结果还是选择底部虚线box作为检测结果呢?虽然实际应用中三个相同gt bbox水平排列的情况并不常见,但是毋庸置疑,还是需要处理一下的。
作者使用soft non-maxima suppression方法,根据Algorithm 1,得到所有的bbox以及对应的得分。假设某个bbox,其score为 s_0 ,所有被这个bbox包含的其他bbox的得分之和超出 s_0 的3倍,那么这个bbox的score降为一半为 s_0/2 (视作对这样的bbox的score的惩罚,后期再对bbox得分低于0.5的进行过滤,就能把ghost box过滤掉了)。为什么是3倍?因为如上图所示,至少有3个 bbox,才会有选择中间bbox还是选择紧紧包围三个bbox的大bbox这样两难的问题。实际上,必须有奇数个bbox,才会有可能出现ghost box的可能,而一个image中有大于3的相等大小的bbox水平或垂直排列,这种可能性极低,所以只要考虑3倍足以(纯粹个人理解)。
Edge aggregation
一个目标的极点并不总是能唯一确定,如果目标的水平或垂直边缘形成极点,那么边上任意一点都是这个方向的极点,比如汽车顶部边线上的所有点都是top-most极点。网络预测heatmap沿着目标极点所在边线上的值则较小,而不是一个大的峰值,这可能导致两个问题:1 较小的值可能低于阈值 \tau_p ,不会认为是极点;2 即使满足了第1点,检测出是极点,其得分也不够大,而稍微旋转目标后,由于边线不再是水平或垂直,故产生新的极点,并且具有较强的峰值响应。
使用边聚合(edge aggregation)解决这个问题。对于每个极点,其 响应/score 都是局部(3x3窗口)最大值,对于left和right方向的极点,则沿着垂直方向聚合score,对top和bottom方向的极点,则沿着水平方向聚合score。注意沿着某一方向聚合时,聚合 score单调递减的那些score,并在这个方向上有局部最小score时停止聚合,这是为了避免多个目标bbox 沿轴排列,从而将不同目标的极点score聚合到一起。
令 m 为某一 t/b 型极点,记 N_i^{(m)}=\hat Y_{m_x+i,m_y} 表示包含 m 这个极点的水平线段在heatmap上的值。令 i_0<0<i_1 表示左右两个最近极小值点,即, N_{i_0-1}^{(m)}>N_{i_0}^{(m)} 以及 N_{i_1}^{(m)}<N_{i_1+1}^{(m)} ,于是edge aggregation更新极点 m 的score为 \tilde Y_m=\hat Y_m + \lambda_{aggr} \sum_{i=i_0}^{i_1} N_i^{(m)} ,其中 \lambda_{aggr} 是聚合权重,作者实验中取 \lambda_{aggr}=0.1 。这里需要解释一下,由于 m 是检测出的 极点,其score必然在3x3窗口是局部最大值,所以比左右两个最近邻点 i=-1,i=1 的score都大,然后往左右两个方向分别继续寻找,以向左方向为例,查看 i=-2 处score是否大于 i=-1 处score,如果是,则找到向左最近极小值点 i=-1 ,否则继续查看 i=-3 处score是否大于 i=-2 处score,直到找到向左最近极小值点,记为 i_0 ,向右方向类似进行得到最近极小值点 i_1 。
图4则是edge aggregation效果图,


(a)是原始heatmap图,在边上的模型预测响应较弱,经过edge aggregation后,边的中间点处的响应得到加强。
Extreme Instance Segmentation
比如bounding box,极点携带了更多的目标信息,bbox的标准只要4个数据,左上右下两个corner的4个坐标值,而极点标注则是4个极点共8个坐标值。
基于极点可以创建一个八边形来近似出一个目标的掩模(mask),这个八边形的边以极点为中心,具体做法是:将 t,l,b,r 四个极点分别沿着bbox四个边的方向延伸,得到4个线段,长度分别是bbox四个边的 1/4,如果延伸时遇到 bbox的corner,则截断(不再延伸),将得到的四个线段的端点按顺序连接起来,就得到八边形。
为了进一步微调实例分割,作者使用了Deep Extreme Cut(DEXTR),这个网络被训练用于将人工提供的极点转换为实例分割mask。在这里,作者仅仅将人工提供的极点替换为本文的极点预测网络,得到2-stage的实例分割。
具体而言,对input image,首先通过ExtremeNet得到n组极点,也就是n个bbox,对每个bbox,在image上crop这个区域(四周边上分别留pad=50的距离,零填充),然后resize到512x512,相应的极点坐标也按比例改变,然后gt map则是四个以极点坐标为中心,标准差为10(这里取固定值)的二维高斯map的pixel-wise 求max,得到最终的多峰值gaussian map。不难得知,resized image和GT map大小相同,将两者concatenate起来,得到 h\times w \times 4 的数据块,然后转置为 4 \times h \times w 并增加新的一个axis,得到 1 \times 4 \times h \times w 的数据块作为DEXTR的输入,DEXTR加载预训练的模型,得到的实例分割mask是分类无关的,所以分类还是使用ExtremeNet的分类预测结果。
Experiments
实验部分不细讲了,这部分直接阅读源码。
