
0基础看懂BERT中attention机制的套路

最近在做bert pretraining,顺便复习了一下bert中Transformer模型的attention。从一个比较直觉化的角度来写一下。
Attention套路框架
先不上公式,从思想上来说attention是一个类似于查询数据库的套路:


将Source中的构成元素想象成一个数据库,由<Key,Value>数据对构成,此时给定一个连续的查询序列Query中的某个元素q,通过计算q和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而q和Key用来计算对应Value的权重系数。[1]
Transformer中的attention
1.单个attention:
在transformer的论文中[2]attention的公式长这样:
\text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V\\
\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}, 分别代表query,key,value矩阵。形状为: \boldsymbol{Q} \in \mathbb{R}^{n \times d_{k}} , \boldsymbol{K} \in \mathbb{R}^{m \times d_k} , \boldsymbol{V} \in \mathbb{R}^{m \times d_{v}} 。这个attention框架是支持query和key-value对不等长,query由n个token组成,key-value都是由m个token组成。
那么上式具体怎么理解呢:


\boldsymbol{Q} 矩阵的每一行是一个query向量,与 \boldsymbol{K^T} 矩阵中每一列的key向量内积得到相似度,然后在对 \boldsymbol{QK^T} 向量每行做softmax,即第一行就是 q_1 与\boldsymbol{K^T}矩阵中每个key向量的归一化相似度。
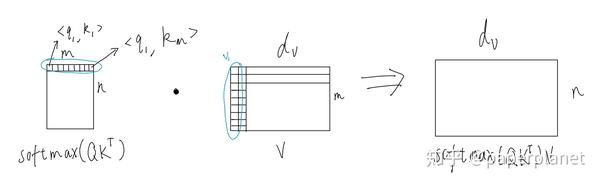

先暂时忽略分母上的常数\sqrt{d_{k}} ,这个是为了softmax训练时避免值过大梯度进入饱和区难以优化。矩阵乘法 \operatorname{softmax}(Q K^{T}) 的每一行与 V 的每一列内积,\operatorname{softmax}(Q K^{T})V的每一行相当于m个 d_v 维向量根据\operatorname{softmax}(Q K^{T})每一行的权重求加权和。 \operatorname{softmax}(Q K^{T})V 矩阵的第一行第一列元素的值即为V矩阵第一列的加权和,第一行第x列以此类推)。
query向量与key向量直接做点积只是求加权值的一种方式,如果要在attenion处改模型还可以在更换各种姿势来求query与key之间的相似性或者相关性。
在阅读理解中key-value对可以是文章的token序列,query可以问题的token序列。也即通过query去查询"全文数据库"。在机器翻译以及bert当中则是query,key,value都是encoder的输入token序列,求encoder输入token内部的相关性,称之为self-attention。
2.multi-head attention:
multi-head attention仅仅是把n组 \operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V 的输出向量做拼接,每组随机初始化,能学到n种不同的attention组合。
在BERT-BASE与标准transformer中d_v与d_k都是64,BERT-BASE有12个attention head,因此每层encoder的输出维度都是12*64=768;标准transformer是8个attention head,每层encoder的输出维度都是8*64=512。
参考资料:
https://zhuanlan.zhihu.com/p/37601161
https://arxiv.org/abs/1706.03762
https://kexue.fm/archives/4765
http://jalammar.github.io/illustrated-transformer/
