LLM/a0测试集C-EVAL中文__排行榜--C-EVAL:一个多层次多学科中文基础模型评价套件 [中文LLM评估基准]

paper地址:https://arxiv.org/pdf/2305.08322v1.pdf----C-EVAL: A Multi-Level Multi-Discipline Chinese
Evaluation Suite for Foundation Models
code地址:https://github.com/SJTU-LIT/ceval
https://github.com/SJTU-LIT/ceval/blob/main/README_zh.md
排行榜home页:A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
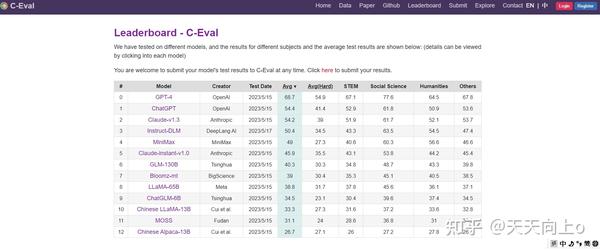
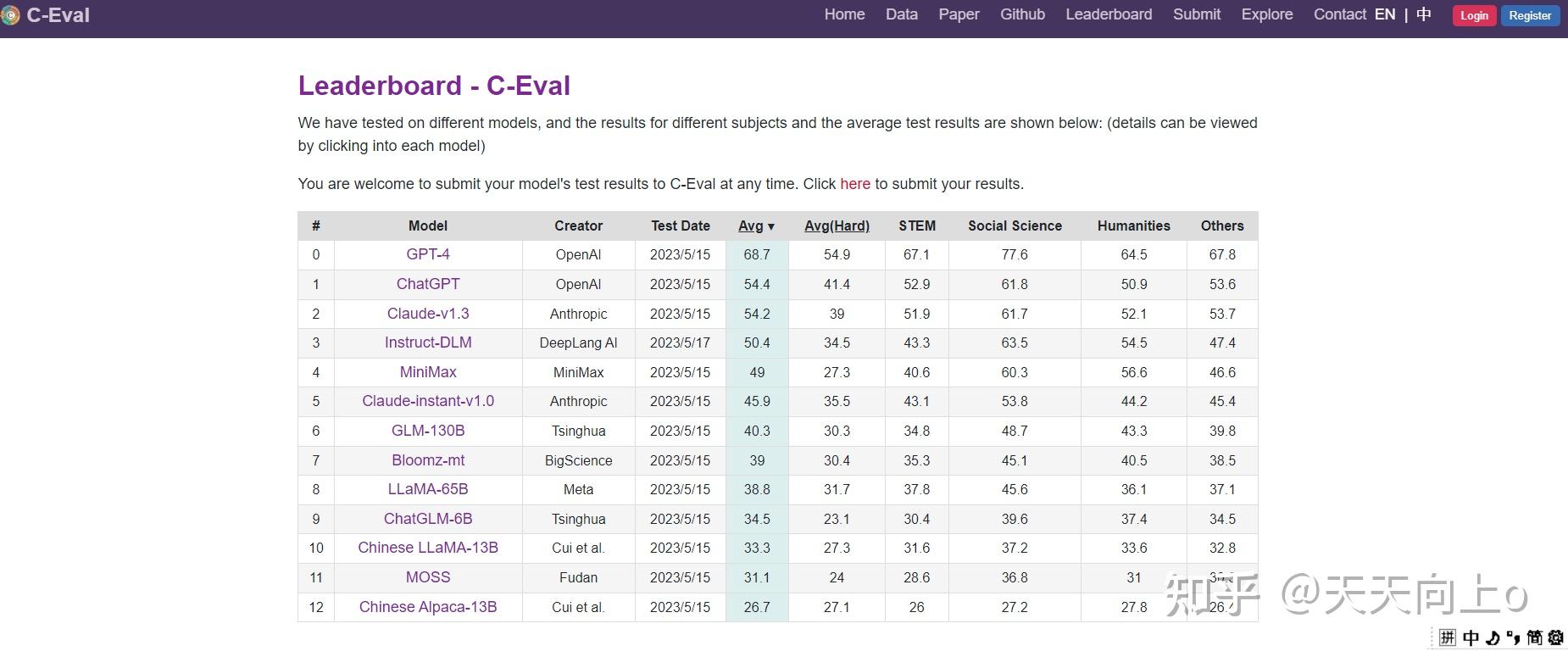
排行榜Leaderboard页:https://cevalbenchmark.com/stat
C-Eval是一个全面的中文基础模型评估套件。 它由13948个多项选择题组成,涵盖52个不同的学科和四个难度级别,如下所示。
您可以在Explore查看我们的数据集示例,或查看我们的论文以了解更多详细信息。涵盖了52个不同学科的13948个多项选择题,
分为四个难度级别。更多详情请访问我们的网站或查看我们的论文。
#
我们的数据可以直接从OneDrive或通过Huggingface数据集下载。请参考我们的GitHub了解如何读取和使用数据。
对于C-Eval有任何问题?请通过ceval.benchmark@gmail.com联系我们,或在Github上创建一个issue。如果您有可能的合作意向,请联系junxianh2@gmail.com。
#
下载
方法一:从 Onedrive 下载,数据以 csv 格式存储,使用 UTF-8 编码。然后可以使用 pandas加载数据:
import os
import pandas as pd
File_Dir="data"
test_df=pd.read_csv(os.path.join(File_Dir,"test","advanced_mathematics_test.csv"))
方法二:使用huggingface datasets直接加载数据集。示例如下:
from datasets import load_dataset
dataset=load_dataset(r"ceval/ceval-exam",name="advanced_mathematics")关于作者:1上海交通大学 2清华大学 3爱丁堡大学
0 摘要Abstract
随着LLM的快速发展,迫切需要新的NLP基准来保持更新。我们提出了C-EVAL,这是第一个全面的中文评估套件,旨在评估基础模型在中文语境下的先进的知识和推理能力。C-EVAL包括四个难度级别的多项选择题:初中、高中、大学和专业。问题涉及涵盖52个不同的学科领域,从人文学科到科学和工程学科不等。C-EVAL还附带有C-EVAL HARD,这是C-EVAL中非常具有挑战性的一部分主题(子集),需要高级推理能力才能解决。我们对最先进的LLM在C-EVAL上进行了全面评估,包括面向英语和中文导向的模型。结果表明,只有GPT-4能够达到超过60%的平均准确率,这表明当前的LLM仍有显著的改进空间。我们预计C-EVAL将有助于分析基础模型的重要优势和缺点,并促进它们在中文用户中的发展和增长。
1 Introduction
怎么去评估一个大语言模型呢?
- 在广泛的NLP任务上进行评估。
- 在高级LLM能力上进行评估,比如推理、解决困难的数学问题、写代码。


2 The C-EVAL Evaluation Suite
2.1 Design Principle
- 虽然不同的LLMs在简单的场景中(如休闲谈话)可能表现相似,但复杂的任务往往是LLMs之间的关键区别(OpenAI,2023).
- 只选择多选题的形式,因为指标定义明确(准确率),而且其是评估基础模型高级能力一个简单而有效的任务。每个问题有四个选项,只有一个选项是正确答案。
- 减轻数据污染:来自国家考试的试题,如中国的国家高考(通常称为高考)和国家专业考试,通常在网上广泛传播和获取。因此,这些试题可能在无意中被抓取并纳入训练,导致潜在的数据泄露问题。为了减少这种风险,作者从模拟考试或小规模的地方考试中收集数据。此外C-EVAL中的大多数样本来自互联网上的PDF或Microsoft Word文档,而不是直接来自纯文本或结构化问题。 这些文件随后被作者解析并仔细注释,以获得最终的结构化格式,这个过程往往涉及到某些题目的复杂的LATEX方程式转换,这进一步减少了数据污染的风险。
2.2 Data Collection
- Subject selection科目选择:C-EVAL涵盖四个难度级别:初中、高中、大学和专业。除了英语科目外,包含了初中、高中的标准科目。对于大学,从中国教育部列出的所有13个官方本科专业类别中选择了25个有代表性的科目、每个类别中至少有一个科目被纳入C-EVAL,以确保全面性。在专业层面上,参考了中国官方的国家职业资格目录5并选择了12个有代表性的科目,如医生、法律专业和公务员资格考试。还将这些科目按其主题分为四类:STEM(科学、技术、工程和数学)、社会科学、人文学科和其他领域。所有52个科目及其指定的类别如图1所示。
- Data sources数据来源:主要来源是互联网上免费提供的模拟考试。一部分大学阶段的试题是来自中国顶尖大学的过去的考试题,由学生公开分享。一小部分大学试题是全国研究生入学考试的模拟试题,来源是维普网站。这些问题不能免费向公众提供,本文已经获得了他们的授权,将大约2000个这样的问题纳入C-EVAL。
- Data Processing数据处理:收集到的数据有多种格式,主要是PDF或Microsoft Word文档,还有一小部分是 网页。PDF文件最初是用OCR工具处理成文本。所有的问题随后被解析,在可能的情况下自动解析,否则由作者手动解析变成结构化格式。====对于具有复杂数学符号的科目,如STEM类别中的许多科目,手动将其转换为标准的LATEX格式。C-EVAL中的所有问题都经过处理,正好包括四个选择。大部分的原始问题伴随着四个选择,还消除了少于四个选项的问题。并对有四个以上选项的问题随机放弃不正确的选择。所有的问题也都经过了标准的数据预处理管道,如重复数据删除和清理。在此之后,这些问题经过了作者的几轮人工验证,所有的LATEX符号都被确保符合要求,没有语法错误。作者为每个科目处理了至少200个问题,并在每个科目中随机地将问题分成一个开发集、一个验证集和一个测试集。每个科目的开发组由五个示例组成,以方便进行少量的评估。这些示范题还附有解释,以便于进行少量的评估。验证集和测试集的比例为1:9.
- Explanation data generation解释数据的生成:将自动生成和人工注释结合起来,为开发部分产生高质量的解释数据。具体来说,作者首先提示GPT-4生成一步一步的解释,以解释正确的答案,然后作者手动修改生成的解释以获得最终解释。
2.3 C-EVAL HARD
从C-EVAL中选择了8个具有挑战性的数学、物理和化学科目,形成一个单独的基准, 即C-EVAL HARD,其中包括高等数学、离散数学、概率和统计、大学化学、大学物理、高 中数学、高中化学和高中物理。这些科目通常涉及复杂的LATEX方程,需要非微妙的推理 能力来解决。图4显示了一个高级数学的例子。C-EVAL HARD与最近创建困难基准以评估高 级推理能力的努力相一致(Hendrycks等人,2021b;Suzgun等人,2022),这是各学科的关键区别。我们选取了C-Eval中具有挑战性的数学、物理和化学科目组成C-Eval Hard,包括:高等数学、离散数学、概率统计、大学化学、大学物理、高中数学、高中物理、高中化学八个科目。这些科目包含了复杂的LaTex公式,需要非凡的推理能力才能解决。
2.4 Evaluation
我们使用准确性作为度量标准。虽然公开了开发和验证集的真实标签,但我们保持测试集的标签私有。这是为确保 C-EVAL 的公平使用,因为由于网络爬取,C-EVAL 数据可能会无意中包含在预训练数据中。相反,用户需要将他们模型预测提交到 https://cevalbenchmark.com 以自动获得测试准确性,其中维护公共排行榜。用户可以根据自己的喜好选择将其提交结果包括在公共排行榜中。
3 Experiment


3.1 Setup
Few-shot evaluation:
使用5-shot进行评估。也就是提供5个实例样本:
Prompt:
在仅有答案的情况下进行少量评价的一个例子。红色的文字是来自模型的自动完成的反应,而前面的文字是输入的提示。在相应的中文文本下面注明了英文翻译。
在思维链场景中有一个少量评价的例子。红色的文字是来自模型的自动完成的反应,而前面的文字是输入的提示。在相应的中文文本下面注明了英文翻译。
对于某些主题,5-shot可能会超过某些LLM的最大上下文长度。在这种情况下,要动态地减少示例的数量。
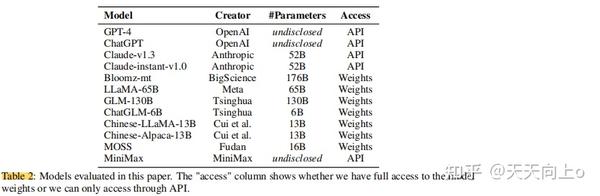

3.2 Models
- ChatGPT和GPT-4 是GPT系列模型,使用从人类反馈中强化学习的方法,增强了其遵循人类指令的能力,使其更有帮助、无害和诚实。GPT-4还支持图像输入,并经过精心设计的训练后对齐过程,以及比大多数现有模型具有更大的规模。GPT-4在各种基准上实现了人类水平的表现,甚至在一些模拟考试中获得了前10%的分数。
- Claude是最新的Anthropic-series LLM,它也专注于人类意图的对齐。采用constitutional AI approach(Bai et al., 2022),Claude设法做到既能帮助别人又值得信赖。Claude-instant是Claude中成27本较低、推理速度较快的轻量级Vesrion。
- BLOOMZ-mt(Muennighoff等人,2022)是通过将多任务提示微调与预训练的多语言BLOOM模型(Scao等人,2022)相结合而创建的,不仅使用英语提示,还使用机器翻译的提示来匹配多语言任务的语言,并且被认为能够进行任务和语言无关的泛化。作者在实验中评估了176B版本。
- LLaMA(Touvron等人,2023)是一个Transformer架构的LLM,它是在几个开放资源的混合体上训练的。LLaMA对以前的LLM所使用的vanilla Transformers进行了一些改进,并对其进行了优化,以提高训练效率,LLaMA显示了强大的语言能力,并能超越参数比LLaMA大10倍的模型。作者在实验中评估了LLaMA-65B版本。
- MiniMax是一个基于Transformer结构的新一代中文LLM,使用"用户在循 环"机制, MiniMax根据用户的反馈迭代更新其基础模型。作者在实验中评估了聊天版本。
- GLM-130B和ChatGLM-6B是基于通用语言模型(GLM)的结构,从其双向注意力的优势中获得好处。通过使用可改变的空白数量和长度,GLM可以适应各种任务。GLM-130B是一个双语预训练的GLM,它利用了自我监督学习和多任务指令预训练。GLM-130B还实现了INT4量化,几乎没有质量下降,大大加快了推理效率。ChatGLM-6B是GLM系列的一个轻量级对话版本,专门针对中文语境进行了优化。ChatGLM-6B还应用了量化技术,因此它可以在消费级图形内存要求低至6GB的情况下部署。作者在实验中对这两个模型的fp16设置进行了评估。
- Chinese-LLaMA是对原LLaMA在中文环境中的改编。Chinese-LLaMA在原LLaMA的基础上增加了2万个中文词汇,并在中文数据上进行了二次预训练和指令微调。作者在实验中评估了Chines-LLaMA-13B,这是最大的Chines-LLaMA变体。
- Chinese-Alpaca是基于Chinese-LLaMA检查点,在中文指令调优数据的基础上进一步调优。作者在实验中评估了Chinese-Alpaca-13B,这是最大的Chinese-Alpaca变体。
- MOSS:MOSS是第一个在训练规模和对齐技术上都与ChatGPT相匹配的开源中文LLM。 MOSS以CodeGen(Nijkamp et al., 2022)为初始化,在100B中文标记和200B英文标记上进行了预训练,并进一步集成了监督微调和偏好模型,以及插件增强功能,但并非所有版本都公开 。作者在实验中评估的是moss-moon-003-sft版本。
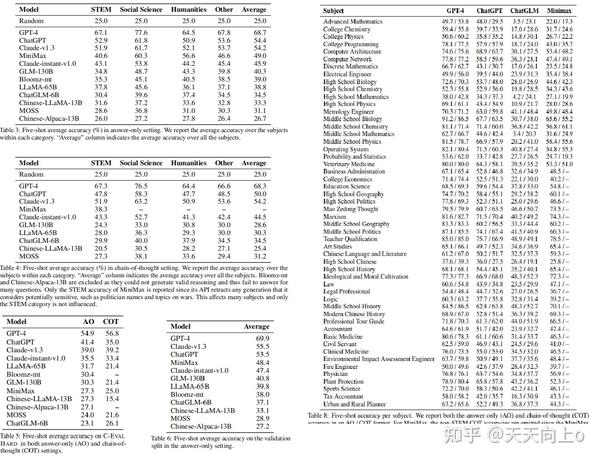
3.3 Results
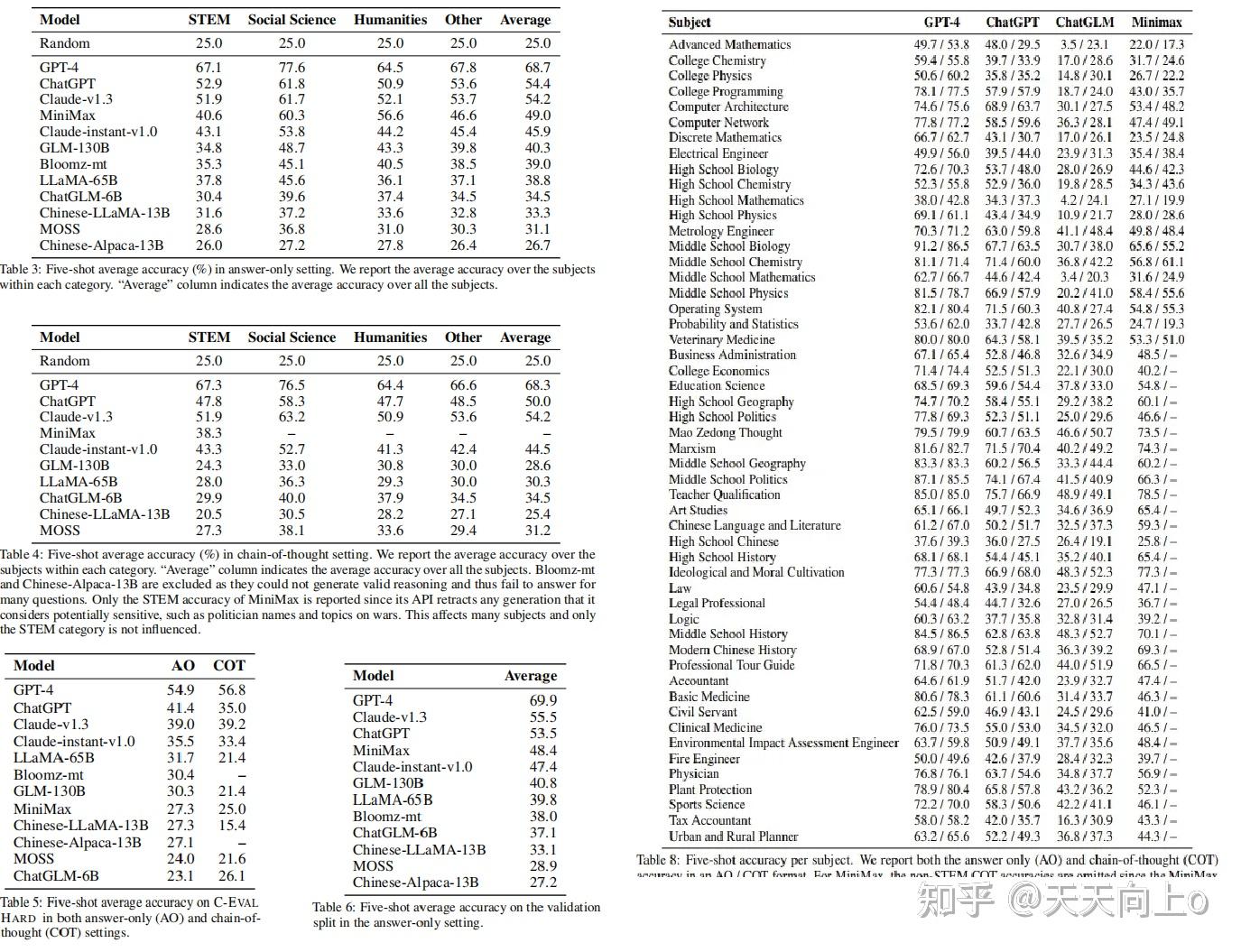
General comparison: 表3展示了所有模型的仅含回答结果,报告平均准确度,而每个主题的详细准确度分布在附录E的表8中提供。GPT-4是唯一超过60%平均准确率的模型,突显了C-EVAL所提出的挑战。 GPT-4明显优于所有其他模型,第二好的模型ChatGPT的平均准确率比GPT-4低了约14个百分点。Claude-v1.3的表现与ChatGPT类似,在类别平均和总体平均方面都表现良好。除了平均准确率之外,表8还显示,GPT-4在几乎所有主题上都优于ChatGPT,表明了全面的优势。这个结果证实了规模扩大的好处 - 即使在ChatGPT的规模下,进一步扩展也可以产生显著的改进。在面向中文的模型中,MiniMax表现最佳,在排行榜上排名第四,平均比ChatGPT低5.4个百分点。排行榜上的下一个模型Claude-instant-v1.0,在平均值方面略微低于MiniMax但再STEM科目胜过MiniMax。其他模型的排名如下:GLM-130B,Bloomz-mt,LLaMA-65B,ChatGLM-6B,Chinese-LLaMA-13B,MOSS和Chinese-Alpaca-13B,表现通常与模型大小相关。我们注意到低于50B参数规模的模型只能实现比随机基线低不到10个百分点的改进(少10分的改进),显示出与大模型之间存在显著的性能差距。这与最近的断言论述相矛盾,即10B规模的指令调整模型可以实现与ChatGPT相当的性能(Taori et al.,2023;Chiang等,2023) --作者认为,虽然尽管这些模型在较简单的任务上可能表现良好,但在面对更复杂的场景时其固有的高级能力明显落后。
Does chain-of-thought prompting help?COT提示不一定能改善C-EVAL中许多科目的结果。其主要原因有两个方面:
- C-EVAL中的许多科目都不是推理密集型的,额外的推理步骤可能会损害性能。
- 一些模型未能利用COT提示的好处,特别是那些没有经过COT包容的指令调整的模型。
Difference between English- and Chinese-oriented models: MiniMax是评估中表现最好的面向中文的模型。虽然MiniMax在表3中平均表现比ChatGPT差5.4分,但它在人文类科目上胜过ChatGPT--表8中的表现分类显示,MiniMax在注重中国知识的科目上明显胜过ChatGPT,如毛泽东思想(73.5%对60.7%)、艺术研究(65.4%对49.7%)、中国语言文学(59.3%对50.2%)和中国现代史(70.1%对62.8%)。这反映了像ChatGPT这样以英语为导向的模型在应用于中国语境时的局限性,突出了以中文为导向的模型可能占据优势的情况。这一观察结果也意味着,将中文数据纳入预训练阶段,对于这些模型在中文语境中有效运作并迎合中国用户的需求来说,确实至关重要。此外,作者观察到MiniMax和ChatGPT在STEM类别中存在12.3分的显著差异,这表明MiniMax和ChatGPT之间的差距并不像它在总体平均水平上看起来那样小。相反,当任务越来越复杂,需要高级推理能力时,它们之间的差距就会扩大。在我们的评估中,MiniMax是表现最好的面向中文的模型,因此我们专注于将其与代表性的面向英文的模型ChatGPT在仅回答设置中进行比较。

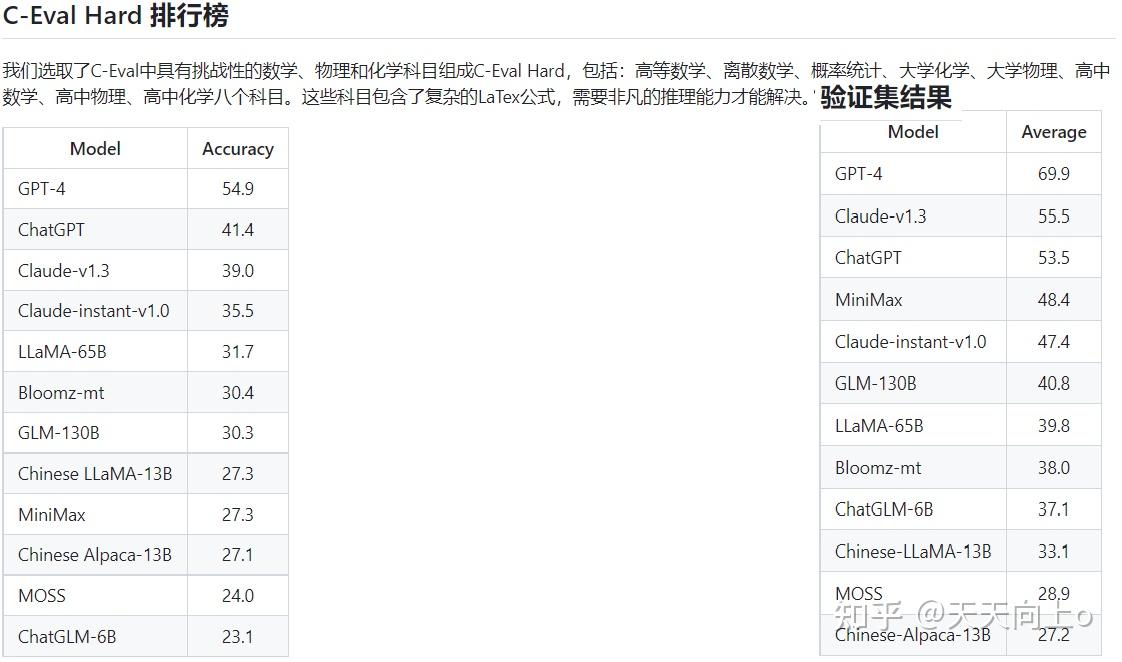
Results on C-EVAL HARD的结果:表5显示了C-EVAL HARD的平均精度。GPT-4只能达到54.9%的准确率 ,暗示了C-EVAL HARD的难度。有趣的是,在这些极富挑战性的题目上,思维链的提示稍微提高了GPT-4的准确性。MiniMax在排行榜上的排名下降幅度最大--虽然它在C-EVAL上 只落后ChatGPT 5.4分,但在C-EVAL HARD上的表现却恶化到几乎是随机的准确度、滞后于ChatGPT 14.1分。事实上只有GPT-4、ChatGPT和Claude的变体能够取得有意义的进步--比随机基线至少提高10分。作者的结果进一步证实,当任务变得足够复杂时,LLM之间的一些关键区别就会出现。作者强调了在这种具有挑战性的环境中评估LLM的重要性, 因为目前的LLM发展已经超越了创建一个休闲的聊天机器人--它涉及到能够与各种数据类型互动、接收反馈、推理和使用工具、甚至执行行动的复杂系统或代理的发展(Mialon等 人,2023)。
Results on the validation split: 由于我们不公开发布测试集的标签,因此我们提供验证集平均准确率作为开发人员的参考。验证集总共包含1346个问题,每个主题平均贡献少于30个验证问题。因此,跟踪特定主题的准确率可能不会产生显著的见解。相反,我们在表6中报告跨所有主题的平均仅回答准确率,平均验证准确率与表3中呈现的平均测试准确率密切相关。此外,在验证集上的模型排名与测试集上的排名大致相对应。这些观察结果表明,开发人员可以使用平均验证准确率作为快速开发流程的良好指标。因为我们不会公开发布测试数据集的标签,所以我们提供验证集的平均准确率作为参考。验证集总共有1346个问题,平均每个科目不到30个问题。因此,特定科目的准确率不具有参考价值。我们在下表中提供在所有科目上的平均准确率。Val集的平均准确率与排行榜中呈现的平均测试准确率非常接近。
4 Related Work
English benchmarks: 英文已经有不少评测基准:
传统的英语基准主要集中于评估模型在单个任务或单一类型任务中的某些能力,例如自然语言理解(NLU,Wang等人(2019))、阅读理解(Rajpurkar等人,2018)、机器翻译(Bojar等人,2014)和摘要(Hermann等人,2015;Narayan等人,2018)。作为代表性的例子,GLUE基准(Wang等人,2019)结合了一系列NLU任务,并由于预训练模型(例如BERT(Kenton&Toutanova,2019)和GPT(Radford等人,2019)的爆发而见证了超人类模型的表现。同时,Goyal等人(2022)最近发现LLM能够生成比CNN / Daily Mail数据集(Hermann等人,2015)中的参考摘要更理想的摘要,导致对这些基准进一步努力的重要性降低。为了更全面地评估LLM的能力,最近的基准已经照亮了更广泛的知识和先进能力。MMLU基准(Hendrycks等人,2021a)提供了来自现实世界考试和书籍的多域和多任务评估。LLM在MMLU上的表现在随机准确率周围波动,直到达到GPT-3的规模。BIG-bench基准(Srivastava等人,2022)由204个不同的任务组成,其中一些被认为超出了当前LLM的能力范围。HELM基准(Liang等人,2022)整合了42个不同的任务,并用7个指标从准确性到鲁棒性评估LLM。
英文已经有不少评测基准:
- 传统英语基准:GLUE是NLU任务的的评测基准。
- MMLU基准(Hendrycks等人,2021a)提供了从真实世界的考试和书籍中收集的多领域和多任务评价。
- BIG-bench基准(Srivastava等人,2022年)包括204个不同的任务,其中一些任务被认为超出了当前LLM的能力。
- HELM基准(Liang等人,2022年)汇总了42个不同的任务,用从准确性到鲁棒性的7个指标来评估LLMs。
Chinese benchmarks: 中文评测基准:
尽管英语基准蓬勃发展,但在中文语境下的语言能力仍未得到充分发展。CLUE基准(Xu等人,2020)是第一个大规模的中文NLU基准,并仍然是最广泛使用和最可用的中文基准。最近,AGIEval基准(Zhong等人,2023)包含来自中国高考、律师资格考试和公务员考试的数据。MMCU Benchmark(Zeng,2023)由四个主要领域的测试组成,包括医学、法律、心理学和教育,这些测试也来自于中国高考、资格考试以及大学考试。与AGIEval和MMCU相比,C-EVAL 1)覆盖的领域更广泛(§2.2),2)具有四个不同难度级别--特别是C-EVAL HARD基准是第一个提供复杂推理问题的中文基准,3)努力缓解数据泄漏问题--我们的问题大多来自于我们进一步处理的模拟考试PDF或Microsoft Word文档,而AGIEval和MMCU则收集来自过去的中国国家考试的确切问题。
中文评测基准:
- CLUE基准(Xu等人,2020)是第一个大规模的中文NLU基准,现在仍然是使用最广泛和最好的中文基准。
- AGIEval基准(Zhong等人,2023)包含了来自中国高考、中国律师资格考试和中国公务员考试的数据。
- MMCU基准(Zeng,2023)包括来自医学、法律、心理学和教育等四大领域的测试,这些数据也是从中国高考、资格考试以及大学考试中收集的。
- 与上述评测基准的区别:C-EVAL特点:1)覆盖更广泛的领域。2)具有四种不同的难度--特别是C-EVAL HARD基准是中国第一个提供复杂推理问题的基准。3)努力减少数据泄漏--作者的问题大多来自模拟考试的PDF或Microsoft Word文件,这些文件由作者进一步处理,而AGIEval和MMCU收集的是中国过去国家考试的确切题目。
5 Discussion
我们认为LLM的评估应该超越休闲会话机器人的范围,指导开发人员准备LLM在更复杂的场景中发挥作用。这是创建C-EVAL(一个具有挑战性的评估套件)的主要动机。我们希望C-EVAL沿着C-EVAL HARD在这个方向上取得重要进展,特别是在中文背景下。我们还注意到C-EVAL沿着所有英语基准-对于LLM评估来说远非完美,还有许多其他功能,例如推理和调用API,以及超出准确性的多个方面,包括安全性,偏差和鲁棒性。我们对未来工作的评估留下进一步的探索,特别强调中文背景下。
参考文献:
zenRRan:上交清华提出中文大模型的知识评估基准C-Eval,辅助模型开发而非打榜
#