
AIGC 绘画理论与保姆级实战

开局prompt献上
(masterpiece, finely detailed beautiful eyes: 1.2), (on the moon, space, looking back into earth), white hair, black tank top, volumetric lighting, white jacket, glowing headphone, cyberpunk, futuristic, multi-color eyes, detailed eyes, hyper detailed,light smile, highly detailed, beautiful, small details, ultra detailed, best quality, intricate, hyperrealism, sharp, digital illustration, detailed, realism, intricate, 4k, 8k, trending on artstation, good anatomy, beautiful lighting, award-winning, photorealistic, realistic shadows, realistic lighting, beautiful lighting, raytracing, intricate details, moody, rule of thirds, masterpiece, (illustration:1.1), highres, (extremely detailed CG, unity, 8k wallpaper:1.1), beautiful face, highly detailed face, ultra realistic, masterpiece, bokeh, extremely detailed, intricate, zoomout, colorful, vibrant colors, red nail polish, side view,
Negative prompt: (worst quality, low quality:1.4), monochrome, zombie,
Steps: 25, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3459739368, Size: 512x1024, Model hash: 30953ab0de, Model: meinamix_meinaV8
介绍
stable-diffusion开源AI绘画模型的横空出世,Aigc的蓬勃发展,绘画师的地位岌岌可危了。大家都能无门槛的生成自己的二次元老婆、名画创作、家居设计等等应用场景
本文章主要为大家介绍嵌套在 stable-diffusion中的各个功能,并在后续的实战技巧篇中,提高大家的玩法,生成属于大家可控的老婆。
抛弃MidJounry、NovelAi,我们要走白嫖路线,怎么能让别人薅我们羊毛
此文章的最终目标
- 免费免费免费
- Ai 老婆
- Ai 换衣
- Ai 手势
- 其它场景的应用普及(如家居设计、视频制作实现、
Lora训练等)
觉得自己理论足够了,可以直接看实战篇的各种玩法
理论篇
下面涉及到stable-diffusion理论知识大概,领大家具备一些参数知识,大家一起做个调参侠
基础模型
checkpoint:完整模型的常见格式,模型体积较大,一般单个模型的大小在3~7G 左右,通常称之为基础模型(基模 base model)。常见的模型chilloutmix_NiPrunedFp32Fix 就是4G。
VAE:负责将潜空间的数据转换为正常图像,就是改变滤镜和色彩。有一些checkpoint merge会自带VAE
训练方式
几种stable-diffusion的fine-tune技术,主要用于让模型通过少量样本的学习,掌握训练数据未出现的一些新概念,比如人脸、宠物和画风等。

Lora:冻结预训练好的模型权重参数,然后在每个Transformer(Transforme就是GPT的那个T)块里注入可训练的层,由于不需要对模型的权重参数重新计算梯度,所以,大大减少了需要训练的计算量(目前最focus的地方)显存8GB以上
Hypernetwork:额外辅助神经网络预测原网络的新权重。一般为.pt后缀格式,大小一般在几十兆左右。显存6GB以上
Textual Inversion:创建另外的Text2embedding,捕捉新prompt 概念。显存12GB以上
Dreambooth:微调扩散至模型。显存12GB以上
Lora
英文全称Low-Rank Adaptation of Large Language Models(大语言模型的低阶适应)
LoRA的做法是,冻结预训练好的模型权重参数,然后在每个Transformer(Transforme就是GPT的那个T)块里注入可训练的层,由于不需要对模型的权重参数重新计算梯度,所以,大大减少了需要训练的计算量。目前最新的stable-diffusion已经原生支持Lora了,直接move模型进行就好了。
这个特性意味着大家也可以fine-tune训练微调,降低参数门槛了!末尾会放koreanDollLikeness的oneFormer 地址
怎么知道模型是base模型还是Lora模型呢
根据Type和文件大小就可以区分,文件很大基本都是base model
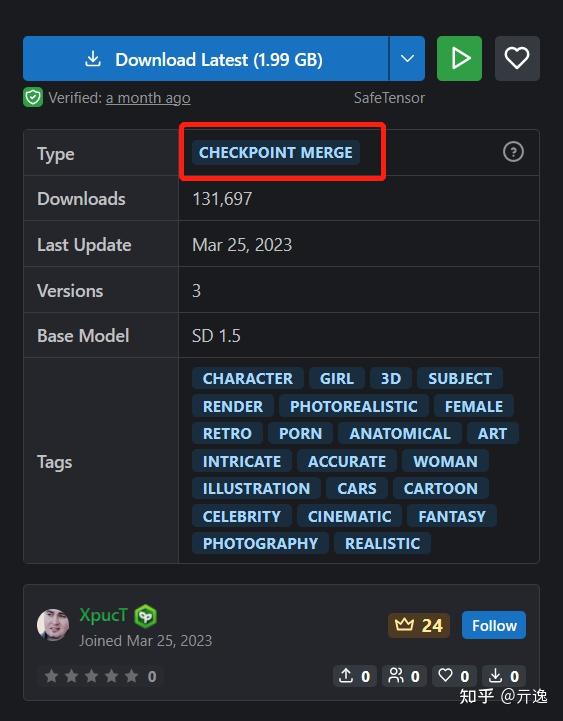



模型资源:https://civitai.com/
koreanDollLikeness:https://huggingface.co/amornlnw7/koreanDollLikeness_v15/blob/main/koreanDollLikeness_v15.safetensors
ControlNet
特别提到一下,ControlNet的作者是中国人!!!张吕敏大佬(致敬)
ControlNet模块是用于img2img 的精准控制的(后面实战会根据其中的open pose模块进行实验),以插件的形式存在于stable-diffusion中
ControlNet 把每一种不同类别的输入分别训练了模型,目前公开的有下面8个。分别是:canny,depth,hed,mlsd,normal,openpose,scribble,seg。
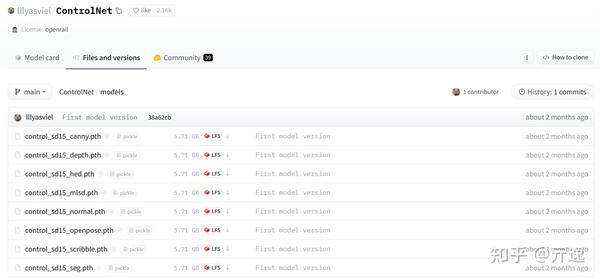

没有最牛逼的模型,只有最适合自己的模型
canny:边缘检测,属于比较通用的模型
hed:HED边缘提取,跟canny类似
scribble:手稿模型,随手涂鸦然后生成一个精美的画面
openpose:姿势控制专用模型,用于人物动作
normal:模型识别,适用于建模
depth:深度检测,提取深度图
seg:语义分割识别
mlsd:线段检测,一般用于建筑、物体的检测,常用于室内装潢,建筑设计
效果参考:https://zhuanlan.zhihu.com/p/606983243
模型资源:https://huggingface.co/lllyasviel/ControlNet/tree/main/models
插件扩展:https://github.com/Mikubill/sd-webui-controlnet#examples
txt2img 参数介绍
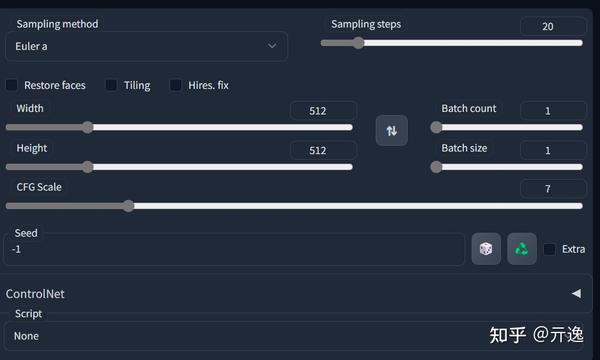

Sampling method:各种采样的方式,太多了,想认真看的话就参考下面资源模块。懒得对比:请使用DPM++ 2M或DPM++ 2M Karras或UniPC,想要点惊喜和变化,Euler a、DPM++ SDE、DPM++ SDE Karras、DPM2 a Karras(注意调正对应eta值)
Restore faces:调用一个神经网络模型对面部进行修复,影响面部
Tilling:CUDA的矩阵乘法优化,影响出图速度和降低显存消耗
Hires.fix:提升图片的画质(里面也对应不同的模型)
CFG Scale:图像与你的prompt 匹配程度 / AI对描述参数的倾向程度。
Width/Height:生成图片的宽/高
Batch count/Batch size:batch 出图数量,先后和一同之分
Seed:生成图片的随机数种子(如果想复刻别人的图片,最好也用别人的随机数种子提高一致性)
Sampling method 详细介绍:https://zhuanlan.zhihu.com/p/612572004
实战篇
Ai 生成
咱们一步步来走进 stable-diffusion的应用,实战检验
万物由一个引子开始,由点到面铺开,先从生成属于自己的 "老婆"先,不需要多复杂的prompt
1girl, <lora:koreanDollLikeness_v15:1>
Negative prompt: (worst quality, low quality:1.4),
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 8, Size: 512x1024, Model: chilloutmix_NiPrunedFp32Fix


弱弱的说一句,koreanDollLikeness 的Lora 已经很好看了
好了,一个属于自己的老婆已经产生了,但是我想加点其它元素,比如换件衣服啊,带个小猫耳,那就需要在 prompt 上面下功夫了
Ai 换衣
换件衣服带个猫耳,带个黑色项圈,那就变成了下面这张图了
1girl, <lora:koreanDollLikeness_v15:1>,cat ears,best quality, ultra high res, (photorealistic:1.4), 1woman, sleeveless white button shirt, black skirt, black choker, cute,(Kpop idol), (aegyo sal:1), (platinum blonde hair:1), ((puffy eyes)), looking at viewer, full body, facing front
Negative prompt: (worst quality, low quality:1.4),
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 1486173605, Size: 512x1024, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix


还不错,但是还不够好,我想她的手可以不要老放下去,做一下我预期能控制的动作,那就引入了刚刚讲的 ControlNet中的open pose 模块了
Ai 手势
需求:我想让我的老婆手势和我喜欢的奥特曼一样,这才是我xp
做法一:准备一张我喜欢的奥特曼的图片,让我的ai 老婆也学习一下打怪兽,然后将图片插入到ControlNet 模块当中


部分参数说明
Enable:启用ControlNet
Invert Input Color:将你用画笔涂抹的区域颜色进行反转
RGB to BGR:颜色通道反转
Low VRAM:低显存模式如果你的显卡内存小于4GB,建议勾选此选项
weight:权重,代表使用ControlNet生成图片的权重占比影响
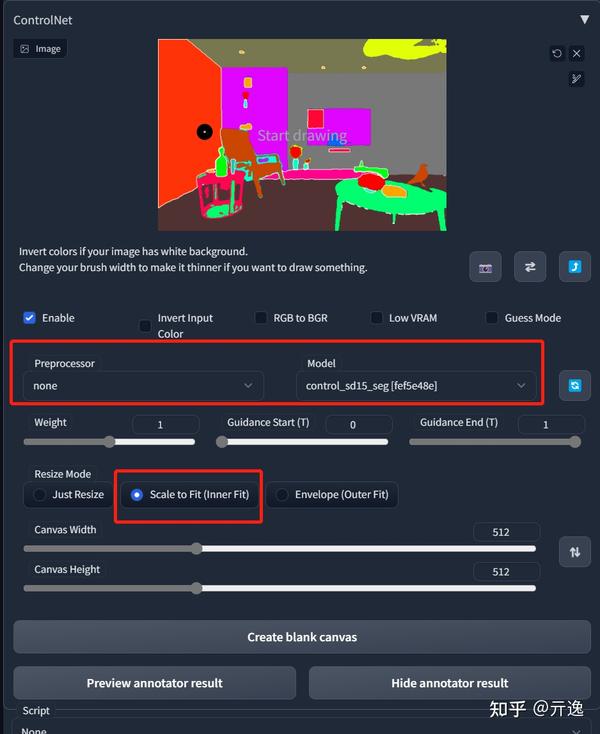
Preprocessor:与图片进行预处理的模型(模型功能在上述介绍ControlNet 模块有讲到)
Model:该列表的模型选择,必须与预处理选项框内的模型名称一致。如果预处理与模型不致也可以出图,但效果无法预料,且并不理想
为了确保图片能够被open pose所解析成功,可点击下面的Preview annotator result进行预查看,避免动作解析无效


做法二:准备好生成人物的参数和Lora、checkpoint基础模型(此处的prompt的之前用的一样)
下图为Ai 老婆根据奥特曼的姿势,自己学习了奥特曼的手势(看来并不能打死怪兽...,丑萌丑萌的)


清晰度提升
需求:机器太差了,生成的图片自己很想要,奈何清晰度不足
打法来了
做法一:准备一张准备模糊的图

做法二:
部分参数介绍
Resize:指定尺寸放大倍数
Upscaler 1:模型A,放大后是图A
Upscaler 2:模型B,放大后是图B
Upscaler 2 visibility:模型B 的透明度(0、1 可完全对应模型B/A)最后参与融合
GFPGAN:面部修复(很有用)
CodeeFormer:面部修复,有对应权重控制显著性
Batch process/from Directory:按照一个batch来提升清晰度


效果图,人脸基本轮廓看清楚了很多(大家还可以基础不同的Upscaler 模型进行调整)


prompt 提词器
需求:不会写prompt
不会还能干嘛,抄呗,下面怼着下面三个网站,照着抄就好了(下面展示krea.ai 中的其中一个例子)
peter rabbit in starship troopers ( 1 9 9 7 ), digital art by eugene de blaas and ross tran, vibrant color scheme, highly detailed, in the style of romanticism, cinematic, artstation, greg rutkowski


注意:未必能很好的复原样例prompt,可能它通过一些fine-tune改过了它的Lora模型或者Text embedding
chatGPT 生成 prompt
你们两个玩,我观战
家具设计
非常有意思的Aigc研究方向,可以自己不断的魔改(如果需要更好的效果,应该还是需要训练)非常有趣的实验需求:想要自己设计自己的屋子,但是没钱请设计师,Ai 给你提意见
做法一:准备自己房子的家居设计图


做法二:通过oneFormer工具,得到一张ADE 20K 标准的元素标记图


做法三:
Chinese style, 1 room, beautiful
Negative prompt: (worst quality, low quality:1.4),
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 179402751, Size: 512x512, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix, Denoising strength: 0.7, ControlNet Enabled: True, ControlNet Module: none, ControlNet Model: control_sd15_seg [fef5e48e], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1, Hires upscale: 2, Hires steps: 6, Hires upscaler: R-ESRGAN 4x+

效果图
Chinese Style


European Style




资源生成:https://huggingface.co/spaces/shi-labs/OneFormer
视频制作实现
目前stable-diffusion用于视频实现的难度还是有点高的,人为干预的成分比较大大家能玩的制作步骤基本都是:
stable-diffusion取出关键帧- 关键帧优化到目标图像(
img2img) - 帧间合成
- 剪辑制作
- 输出视频
目前仍做不到一体化,并且做法较为复杂,此处仅提供方法,不实战演练了
Lora 训练
此处仅介绍做法,图片就不展示了,涉及隐私
不过colab应该没多少资源了,大家也可以通过kohay_ss GUI本地部署进行训练
做法一:自己配置kohay_ss GUI训练环境
以下场景仅针对Windows系统
第一步,以管理者身份打开Windows Powershell terminal 窗口
第二步,输入 Set-ExecutionPolicy Unrestricted 然后回答 'A'
第三步,关闭窗口
第四步,输入以下命令即可
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv venv
.\venv\Scripts\activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config # 针对这条命令需要认真选, 根据0/1 切换选项(这里仅提供在本机训练与GPU 环境)
# This Machine
# No distributed training
# NO (有GPU 的话)
# No
# No
# ALL
# NO第五步,针对 30系和 40系显卡。接着上一步运行就好
.\venv\Scripts\activate
python .\tools\cudann_1.8_install.py
现在已经配好了,可以直接双击gui.bat打开里面web ui即可(和sd 一个道理)
做法二:仅针对不会自己打tag(即prompt)同学,将需要训练的图片丢进stable-diffusion UI里的train模块中的Preprocess images对批量的训练集图片进行打tag(为训练做准备)


部分参数介绍
Source directory:数据集目录文件
Destination directory:目标目录文件
Width/Heigh:建议512*512大了会爆显存
Create flipped copies: 创建镜像图片,对每个图像创建一个翻转的副本
Split oversized images: 把过大的图片裁切成多张
Auto focal point crop: 自动聚焦,就是自动截出过大的图片的重点部分
Use BLIP for caption: 略
Use deepbooru for caption:使用第1个步骤处理好的图片进行训练(一般都要勾选)

做法三:使用Kohya_ss开始训练
此处步骤比较复杂,后文会添加 B站介绍详细做法






做法四:拿out文件到stable-diffusion中插入Lora模型进行生成
注意:Preprocess 图片需要自己根据prompt 进行一定的修改才能更加准确
环境配置
https://www.bilibili.com/video/BV148411c7U2/
https://zhuanlan.zhihu.com/p/609632788
总结
好玩的工具,也需要大家往正道上用。后续会对stable-diffusion更新更多的实战技巧,更多种玩法
参考文章
https://zhuanlan.zhihu.com/p/606983243
https://zhuanlan.zhihu.com/p/612572004