
用PyOD工具库进行「异常检测」

异常检测(又称outlier detection、anomaly detection,离群值检测)是一种重要的数据挖掘方法,可以找到与“主要数据分布”不同的异常值(deviant from the general data distribution),比如从信用卡交易中找出诈骗案例,从正常的网络数据流中找出入侵,有非常广泛的商业应用价值。同时它可以被用于机器学习任务中的预处理(preprocessing),防止因为少量异常点存在而导致的训练或预测失败。
今天要介绍的工具库,Python Outlier Detection(PyOD)是当下最流行的Python异常检测工具库,其主要亮点包括:
- 包括近20种常见的异常检测算法,比如经典的LOF/LOCI/ABOD以及最新的深度学习如对抗生成模型(GAN)和集成异常检测(outlier ensemble)
- 支持不同版本的Python:包括2.7和3.5+;支持多种操作系统:windows,macOS和Linux
- 简单易用且一致的API,只需要几行代码就可以完成异常检测,方便评估大量算法
- 使用JIT和并行化(parallelization)进行优化,加速算法运行及扩展性(scalability),可以处理大量数据
从2018年5月正式发布以来,PyOD已经获得了超过300,000次下载与2,500个GitHub Star,在所有GitHub数据挖掘(data mining)工具库[1]排名8 。PyOD论文也已经在 Journal of Machine Learning Research (JMLR)上发表。同时它也被运用于多项学术研究中[2][3][4][5][6],我也曾在回答中使用过PyOD:「数据挖掘中常见的「异常检测」算法有哪些?」。
因为现阶段所有文档与实例全部为英文,为了方便大家使用,特别创作了这篇中文使用指南,欢迎转载(无需授权)。
1. 背景概览(package overview)
PyOD提供了约20种异常检测算法(详见图1),部分算法介绍可以参考「数据挖掘中常见的「异常检测」算法有哪些?」或异常检测领域的经典教科书[7]。同时该工具库也包含了一系列辅助功能,包括数据可视化及结果评估等:

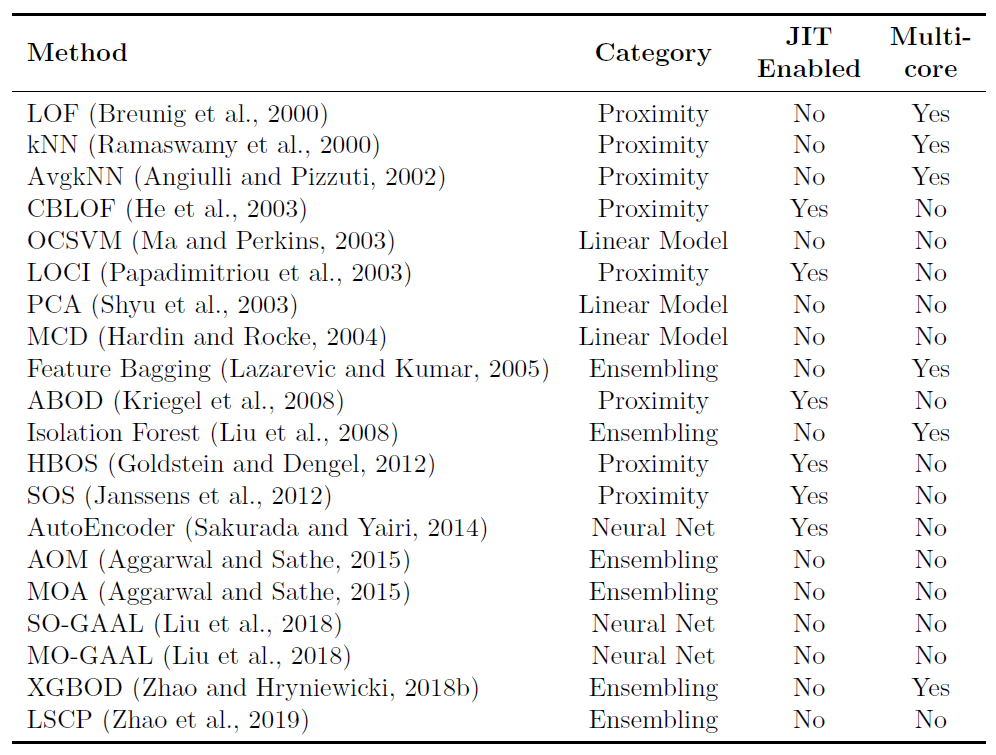
工具库相关的重要信息汇总如下:
- Github地址: pyod
- PyPI下载地址: pyod
- 文档与API介绍(英文): Welcome to PyOD documentation!
- Jupyter Notebook示例(notebooks文件夹): Binder (beta)
- JMLR论文: PyOD: A Python Toolbox for Scalable Outlier Detection
PyOD提供两种非常简单的安装方法。我个人推荐使用pip进行安装:
pip install pyod
使用其包含的算法也很简单:每个算法均有相对应的例子,方便使用者学习了解API(示例文件夹),比如LOF算法的对应例子就叫做lof_example.py,非常容易找到。除此之外,作者还提供了可互动的Jupyter Notebook示例,无需安装,直接从浏览器打开notebook就可以尝试PyOD工具库。
2. API介绍与实例(API References & Examples)
特别需要注意的是,异常检测算法基本都是无监督学习,所以只需要X(输入数据),而不需要y(标签)。PyOD的使用方法和Sklearn中聚类分析很像,它的检测器(detector)均有统一的API。所有的PyOD检测器clf均有统一的API以便使用,完整的API使用参考可以查阅(API CheatSheet - pyod 0.6.8 documentation):
- fit(X): 用数据X来“训练/拟合”检测器clf。即在初始化检测器clf后,用X来“训练”它。
- fit_predict_score(X, y): 用数据X来训练检测器clf,并预测X的预测值,并在真实标签y上进行评估。此处的y只是用于评估,而非训练
- decision_function(X): 在检测器clf被fit后,可以通过该函数来预测未知数据的异常程度,返回值为原始分数,并非0和1。返回分数越高,则该数据点的异常程度越高
- predict(X): 在检测器clf被fit后,可以通过该函数来预测未知数据的异常标签,返回值为二分类标签(0为正常点,1为异常点)
- predict_proba(X): 在检测器clf被fit后,预测未知数据的异常概率,返回该点是异常点概率
当检测器clf被初始化且fit(X)函数被执行后,clf就会生成两个重要的属性:
- decision_scores: 数据X上的异常打分,分数越高,则该数据点的异常程度越高
- labels_: 数据X上的异常标签,返回值为二分类标签(0为正常点,1为异常点)
不难看出,当我们初始化一个检测器clf后,可以直接用数据X来“训练”clf,之后我们便可以得到X的异常分值(clf.decision_scores)以及异常标签(clf.labels_)。当clf被训练后(当fit函数被执行后),我们可以使用decision_function()和predict()函数来对未知数据进行训练。
在有了背景知识后,我们可以使用PyOD来实现一个简单的异常检测实例:
from pyod.models.knn import KNN # imprt kNN分类器
# 训练一个kNN检测器
clf_name = 'kNN'
clf = KNN() # 初始化检测器clf
clf.fit(X_train) # 使用X_train训练检测器clf
# 返回训练数据X_train上的异常标签和异常分值
y_train_pred = clf.labels_ # 返回训练数据上的分类标签 (0: 正常值, 1: 异常值)
y_train_scores = clf.decision_scores_ # 返回训练数据上的异常值 (分值越大越异常)
# 用训练好的clf来预测未知数据中的异常值
y_test_pred = clf.predict(X_test) # 返回未知数据上的分类标签 (0: 正常值, 1: 异常值)
y_test_scores = clf.decision_function(X_test) # 返回未知数据上的异常值 (分值越大越异常)不难看出,PyOD的API和scikit-learn非常相似,只需要几行就可以得到数据的异常值。当检测器得到输出后,我们可以用以下代码评估其表现,或者直接可视化分类结果(图2)。
# 评估预测结果
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
# 可视化
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)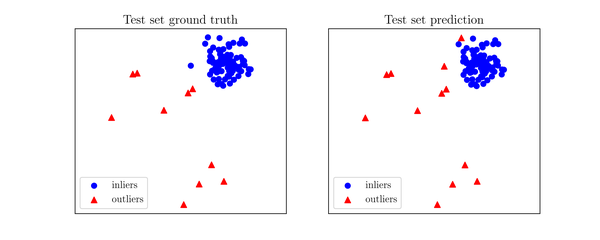

3. 相关教程、资源与未来计划
除此之外,不少网站都曾提供过如何使用PyOD的教程,比较权威的有:
- Analytics Vidhya: An Awesome Tutorial to Learn Outlier Detection in Python using PyOD Library
- KDnuggets: Intuitive Visualization of Outlier Detection Methods
- awesome-machine-learning: General-Purpose Machine Learning
根据开发团队的计划(Todo & Contribution Guidance),很多后续功能会被逐步添加:
- 支持GPU运算
- 支持conda安装
- 增加中文文档
除此之外,开发团队也整理异常检测相关的资源汇总(课程、论文、数据等),非常值得关注:anomaly-detection-resources
总结来看,PyOD是当下最为流行的异常检测工具库,且处于持续更新中。建议大家尝试、关注并参与到PyOD的开发当中。有鉴于功能可能会不断更新,请以GitHub版本为准。
引用PyOD非常方便,可参考如下:
Zhao, Y., Nasrullah, Z. and Li, Z., 2019. PyOD: A Python Toolbox for Scalable Outlier Detection. Journal of machine learning research (JMLR), 20(96), pp.1-7.或者
@article{zhao2019pyod,
author = {Zhao, Yue and Nasrullah, Zain and Li, Zheng},
title = {PyOD: A Python Toolbox for Scalable Outlier Detection},
journal = {Journal of Machine Learning Research},
year = {2019},
volume = {20},
number = {96},
pages = {1-7},
url = {http://jmlr.org/papers/v20/19-011.html}
}参考
- ^https://github.com/topics/data-mining
- ^Ramakrishnan, J., Shaabani, E., Li, C. and Sustik, M.A., 2019. Anomaly Detection for an E-commerce Pricing System. arXiv preprint arXiv:1902.09566.
- ^Zhao, Y., Nasrullah, Z., Hryniewicki, M.K. and Li, Z., 2019, May. LSCP: Locally selective combination in parallel outlier ensembles. In Proceedings of the 2019 SIAM International Conference on Data Mining (pp. 585-593). Society for Industrial and Applied Mathematics.
- ^Ishii, Y. and Takanashi, M., 2019. Low-cost Unsupervised Outlier Detection by Autoencoders with Robust Estimation. Journal of Information Processing, 27, pp.335-339.
- ^Klaeger, T., Schult, A. and Oehm, L., 2019. Using anomaly detection to support classification of fast running (packaging) processes. arXiv preprint arXiv:1906.02473.
- ^Krishnan, S. and Wu, E., 2019. AlphaClean: Automatic Generation of Data Cleaning Pipelines. arXiv preprint arXiv:1904.11827.
- ^Aggarwal, C.C., 2015. Outlier analysis. In Data mining (pp. 237-263). Springer, Cham.

