Shift and stitch理解

在看论文 Fully Convolutional Networks for Semantic Segmentation. Evan Shelhamer, Jonathan Long et. al 时,遇到shift and stitch这个方法,觉得理解起来不那么直观,遂记录一下。
在Semantic Segmentation中,由于CNN网络的下采样,使得输出是coarse的,要想得到 pixel级别的dense prediction,其中一种方法是shift and stitch,介绍如下。
假设降采样因子为s,那么output map(这里为了简单起见,仅考虑二维)的spatial size则是 input的 1/s, 平移 input map, 向左或向上(向右向下情况一样),偏移量为(x,y), 其中,
x,y \in \{0,1,...,s-1\}
这样就得到 s^2 个 inputs,通过网络前向传播自然得到 s^2 个outputs,将outputs 交织成与origin input 大小相同的output map,就实现了pixel级别的dense prediction。
参考博客[1]中的例子说明,为了省事,以下相关内容和图片均引用原文:
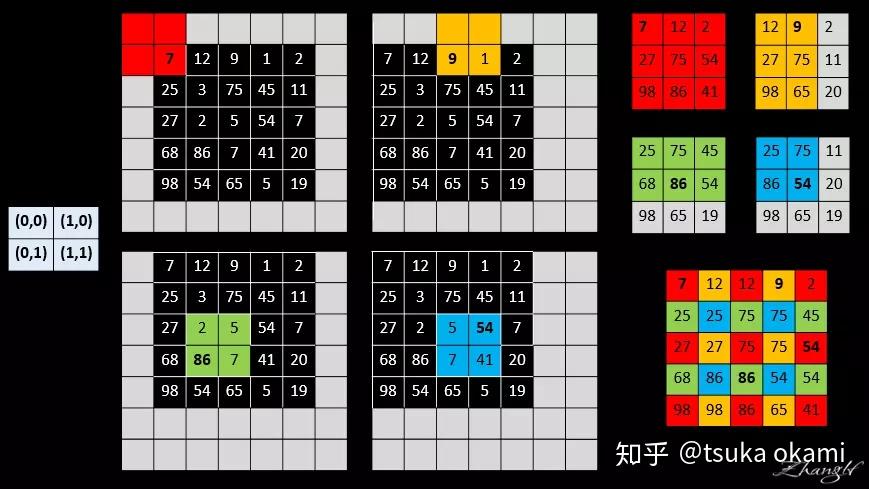
设网络只有一层 2x2 的maxpooling 层且 stride = 2,所以下采样因子 为2, 我们需要对input image 的 pixels 平移 (x,y)个单位,即将 image 向左平移 x 个pixels , 再向上平移y个单位,整幅图像表现向左上方向平移,空出来的右下角就以0 padding 。我们当然可以采取 FCN论文中的做法,将图像向右下角平移,空出来的左上角用 0 padding ,这两种做法产生的结果是一致的,没有本质区别。(x,y) 取(0,0), (0,1),(1,0),(1,1) 后,就产生了 s^2=4 个input,不妨记为: shifted input (0,0)、shifted input (0,1),shifted input (1,0),shifted input (1,1)(图中的数字表示像素值,不是索引值 )


4个input分别进行 2x2 的maxpooling操作后,共产生了4个output,

最后,stitch the 4 different output获得dense prediction,

具体stitch的操作步骤为,
output中的每个pixel都对应original image的
不同receptive field,将receptive field的中心c填上这个来自output的pixel值,就是网络对original image中像素c的prediction。
为表述简洁,我用 “ 像素 i ” 表示“ 值为 i 的像素 ”。
- 红色
output中的像素1对应shifted input(0,0)的红色部分, 而对应original image的部分,也即receptive field仅仅为像素[1],所以receptive field的中心为像素[1], 该位置填上红色output中像素1的值。 - 黄色
output中的像素4对应shifted input(1,0)的黄色部分, 而对应original image的部分,也即receptive field为像素[3,4], 所以receptive field的中心为像素[4], 该位置填上黄色output中像素4的值。 - 以此类推..
- 注意: 我们注意到黄色
output中的像素5与红色output中的像素5对应的receptive field中心是重叠的,所以将黄色output中的像素5标为灰色,表示不予考虑。同理其他ouput中的灰色区域也代表receptive field中心重叠的像素。
由于上面的像素值很像索引值,为了避免混淆,原文又给出了一个例子,这里也照搬过来 :-)

到此,引用博客内容结束。
filter dilation
FCN论文作者说了,shift and stitch这个方法会以 s^2 倍增加cost,因为input数量从1变成 s^2 ,有一个trick可以解决这个问题,那就是filter dilation。在介绍这个方法之前,我们先观察,图4中最后的output 其实是跟 2x2 max pooling, stride=1 的操作结果一样,这个不是巧合,因为在这个情况下,shift and stitch 与 2x2 max pooling, stride=1 两种操作本质是一样的,这是显然的,shift and stitch中stride 为s,实际上平移input (x,y) 其中 x,y \in \{0,1,...,s-1\} 可以等效于 分别滑动 filter 0,1,...,s-1的距离,也就是说,可以看作 filter 是按 stride=1 滑动的。所以,我们可以直接设置 stride=1 ,就完成了 shift and stitch这个操作。
但是别忘了,上面那个例子有个条件“网络只有一个layer:pooling”,对于只有一个subsampling 层(无论conv还是pooling)的网络(除此之外没有别的layer了),shift and stitch可以通过设置stride=1来获得相同的结果。 然而网络通常是由多个conv,pooling,ReLU 等多种layer stack 起来的CNN,这种情况下,通过简单地对subsampling layer设置stride=1则无法得到相同的结果。
考虑某个layer(conv或者pooling,此layer就是上文一直说的subsampling layer),其stride=s,其后续是一个conv 层,这个conv 层的filter 权重记为 f_{ij} (方便起见,仅考虑二维情况),记input 大小为 wxh,考虑两种策略:
- shift and stitch。过程为,shift input,得到 s^2 个inputs,然后分别经过subsampling layer得到 s^2 个outputs,这些outputs 又分别通过后续的conv层,得到 s^2 个outputs,最后stitch这 s^2 个outputs得到最终大小为
wxh的output。 - 将subsampling 的stride设置为
1,并按如下方法dilate 后续conv层的filter, f'_{ij}=\begin{cases} f_{i/s,j/s} & i/s, j/s \in \Bbb I \\ 0 & \text{otherwise} \end{cases} ,然后 input 经过这两个layer,由于没有subsampling,所以最终output大小为wxh。
显然,第1种策略计算量大,第2种策略与第1种策略结果相同,且计算量大大减少,所以选用第2种策略。为何这两种策略结果相同?
我们看图4 top-right 部分的图,4个3x3的outputs就是 第1种策略中 subsampling层的输出, 对其分别使用后续conv 层filter进行卷积,以第一个output为例(红色),其余3个output情况类似,

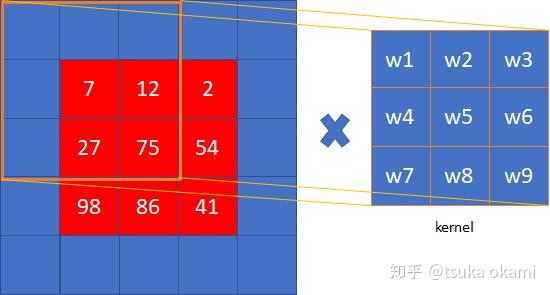
对应第二种策略,则是图4 bottom-right 的子图,即stride=1的maxpooling的输出,对后续conv 层的filter进行dilate,如图6中右图,就是dilated 之后的kernel,


对比图5和图6,可以发现结果一样。图6向右移动stride=1的卷积(图7 top部分),对应图4中top-right黄色output图的卷积(图7 bottom 部分),

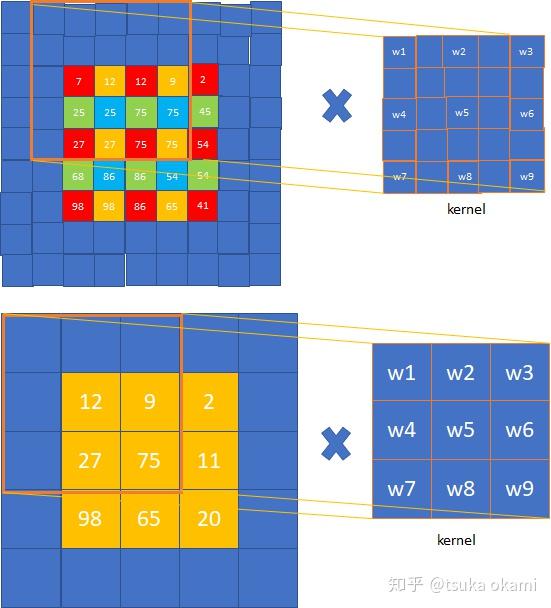
其余颜色的卷积依次类推,可见,这两种策略得到的结果是一样的。
我们继续考虑一种情况,如下:
记某个subsampling layer为 l_1 ,其stride = s,后跟两个conv 层,分别记为 l_2, l_3 ,根据上面的讨论,我们已经知道 l_2 的filter需要dilation,那 l_3 的filter是否需要dilation呢?
显然答案是:需要, l_3 的filter 需要进行与 l_2 相同的dilation,因为可以将图4中右半部分的output看作是 l_2 的输出,这说明,subsampling之后的每个conv层都需要dilation,以使得每个conv层的filters所看到的input范围更大,因为将subsampling层的stride降低到1之后,higher layer的RF变小了,要维持与stride降低之前的水平,自然需要将higher layer的filters膨胀(当然,这只是定性说明,便于理解)。
对于膨胀系数,不难得知,将subsampling层stride由 s降为1时,膨胀系数则由1升至 s。
进一步地,如果到达某个conv层时已经经过两个subsampling层,stride分别为 s_1, s_2 ,那么将 这两个subsampling 层的stride 均降为 1后,这个conv 层的filter膨胀系数则为 s_1 \cdot s_2 。
(由于时间仓促,最后这几段的结论未经详细思考,仅供参考)
2019-1-30 18:55
REF:
