
大数据文件存储系统HDFS


一起遨游编程世界。
现在随着企业规模的发展,对于数据存储的要求越来越大,单机存储性能已经成为存储的瓶颈,在这里我们就需要引入分布式存储,通过水平扩展的方式进行容量的扩展,并且提高数据的一致性,安全性,可靠性等关系。
大数据也是发展的前景之一,越来越多的开发者开始进入大数据领域,并且很多企业开始关注,逐步发展自己的大数据业务,数据的重要性不言而喻,那么我们应该怎么进行数据保存,扩展呢?这正是分布式文件系统需要解决的问题。
我们今天所要说的重点是大数据存储的王者HDFS存储系统。
HDFS
什么是HDFS呢?官网是这样解答的,是一种分布式文件系统,设计用于在商用硬件上商用,管理数以千计的服务器,数以万计的磁盘,将大规模的服务器资源当做一个单一的出承诺函系统进行管理,操作大批量数据就像使用普通文件系统一样。
简单理解其架构
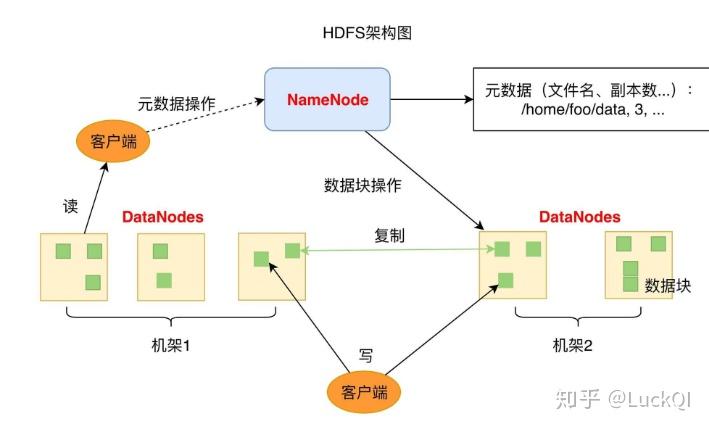

HDFS是经典的主从架构,当然为了保证高可用,HDFS也提供了高可用的方案,在3.0版本以上更加提供了多个主节点用来帮助提高系统的可用性。
在其设计理念上,有两个主要的关键组件NameNode与DataNode.简单来说NameNode负责保存一些元数据信息,DataNode负责数据的读取与写入,但是真的只是这么简单吗?
我们从Linux的文件系统就可以看出,文件系统是有目录项,索引节点,逻辑块,超级块四大元素构成。同样的HDFS文件系统也有类似的管理操作。
NameNode
NameNode 究竟负责什么呢?我们今天就来看一下。
在3.0版本以前,NameNode是只存在两个节点的,一个Active节点,一个Standby节点。在3.0以后就可以支持2个以上的NameNode节点了,高可用性得到了提高。
责任
NameNode(Active状态)
- 整个分布式文件系统的元数据(元数据)管理。元数据包括文件的名字,副本数,存储的block-id(HDFS中使用block作为存储单元,block-id包含了哪个DataNode节点)信息。
- 接受客户端的读写请求。告知客户端读取的信息去哪里读取,写入数据要写入到哪个机器
- 启动的时候加载元数据到内存中。内存中存储的是 fsimage(元数据镜像文件,类似于文件系统的目录树)+edits(元数据的操作日志,针对文件系统做的修改操作记录)。我们如果系统出现错误的格式化,当另外节点数据好保存着可以进行数据的恢复。
- 通过心跳的方式与DataNode进行存活的通信。
- 数据备份告知。
SecondryNameNode的工作
- 默认1小时定期合并Active NameNode 下的fsimage与edits,避免edit log过大。是通过创建检查点checkpoint来实现的。
- 合并完毕后,在发送给Active NameNode ,可以说不算是Active 的备份节点。
- HDFS的Federation 这个是用来扩展单机NameNode 水平扩展的问题的,管理多个命名空间,降低单机操作的读写的压力。
DataNode
DadaNode 主要是数据的读取,写入,存储,冗余等内容。
- 硬盘故障容错,检测到本地硬盘出现故障,会将其所存储的BlockID内容报告给NameNode,NameNode进行调度按照其他服务器进行备份处理。
- 存储数据块Block
- 启动线程与NameNode进行通信,汇报其存储的BlockID信息
- 保持3秒的心跳链接,超过一定时间认为数据节点丢失。
- Block的放置策略如下(机架的问题下次再说):
- 第一个副本,放置在本机上,如果是集群外提交的,随机选择不太忙的节点存储。有就近的原则
- 第二个副本,放置在与第一个副本不同机架上的节点上。
- 第三个副本,放置在与第二副本相同机架上的相邻节点上。
- 更多副本随机放置。
数据的读取与写入
读取文件流程


- 我们程序是作为客户端的存在,根据api进行操作
- 然后访问Namenode,传输给需要读取的文件
- Namenode 查看需要的元数据信息,包含路径所存在block-id信息,还有datanode信息。
- 根据返回的block-id进行(就近原则)读取,具有先后顺序。
- 每读取取完一个block后,会接着读取下一个block块
- 注意 4和5的流程是并行处理的。客户端刚开始就并行的读取多个block块的数据,单位是packet为单位接收,本地缓存。
- 下载完毕后,在进行组装,根据block追加成为文件,完整的数据就完成下载了。
写文件流程
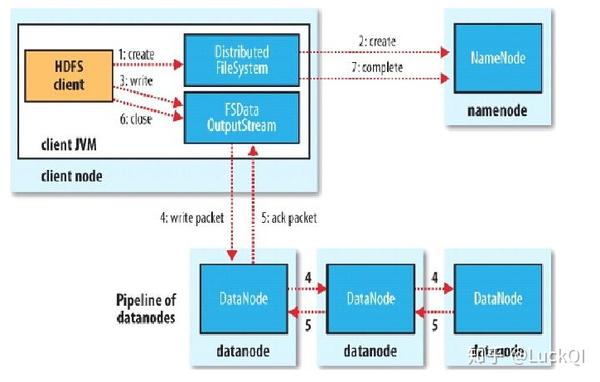

- 客户端 创建好需要的api操作。
- 打开与nameNode的链接,检查目标文件是否存在,目录内容是否存在等信息.
- namenode返回可以上传的信息包含要上传的位置datanode 节点信息等。
- 客户端请求就近的节点开始上传数据,按照packet为单位,后面备份的节点数据是通过异步调用的通道放大建立管道传输数据。本质上上传了一个节点,其他节点是通过复制传输完成的。
- 当第一个block写完之后,客户端再次请求namenode上传第二个block的服务器。重复以上步骤。
- 写入也是并发的写入。
发布于 2019-01-15 23:56
