
目标检测之非极大值抑制(NMS)各种变体

简介
最近比较忙,很长时间没分享了.本想着今天把这篇文章全部完成,结果下班回家时忘记车停在哪里,在单位地库找了20多分钟才找到,脑子闷闷的,今天这篇文章中还有点未完成,后期会补上.好了,进入正题.
NMS(Non Maximum Suppression),又名非极大值抑制,是目标检测框架中的后处理模块,主要用于删除高度冗余的bbox,先用图示直观看看NMS的工作机制:
从上述可视化的结果可以看出,在目标检测过程中,对于每个obj在检测的时候会产生多个bbox,NMS本质就是对每个obj的多个bbox去冗余,得到最终的检测结果.
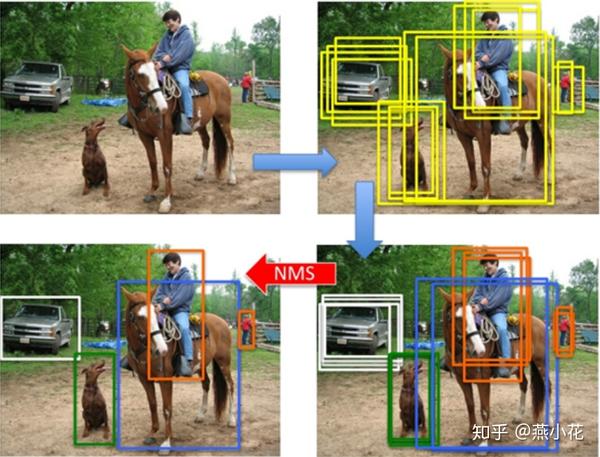

NMS各大变体
在这里,我主要是针对文本检测中的NMS进行详细阐述.文本检测是一种特殊的目标检测,但它与通用的目标检测又存在一定的区别:通用目标检测一般采用的水平矩形框,而文本检测中文本行存在方向不确定性(水平、垂直、倾斜、弯曲),针对多方向文本一般采用带方向矩形框、四边形及多边形.因为矩形框的表征方式不同,就衍生了不同版本的NMS,主要包括:标准NMS、locality-aware NMS(简称LNMS)、inclined NMS(简称INMS)、Mask NMS(简称MNMS)、polygonal NMS(简称PNMS).
标准NMS(SNMS)
- 基本步骤
1.将所有检出的output bbox按cls score划分(如文本检测仅包含文1类,即将output bbox按照其对应的cls score划分为2个集合,1个为bg类,bg类不需要做NMS而已)
2.在每个集合内根据各个bbox的cls score做降序排列,得到一个降序的list_k
3.从list_k中top1 cls score开始,计算该bbox_x与list中其他bbox_y的IoU,若IoU大于阈值T,则剔除该bbox_y,最终保留bbox_x,从list_k中取出
4.对剩余的bbox_x,重复step-3中的迭代操作,直至list_k中所有bbox都完成筛选;
5.对每个集合的list_k,重复step-3、4中的迭代操作,直至所有list_k都完成筛选; - 具体实现代码
实现代码来自于Fast-RCNN;如果想要更好地理解,可以查看胡孟的相关博文(https://zhuanlan.zhihu.com/p/49481833)
#coding=utf-8
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
# tl_x,tl_y,br_x,br_y及score
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#计算每个检测框的面积,并对目标检测得分进行降序排序
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = [] #保留框的结果集合
while order.size > 0:
i = order[0]
keep.append(i) #保留该类剩余box中得分最高的一个
# 计算最高得分矩形框与剩余矩形框的相交区域
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交的面积,不重叠时面积为0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算IoU:重叠面积 /(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#保留IoU小于阈值的box
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1] #注意这里索引加了1,因为ovr数组的长度比order数组的长度少一个
return keep
if __name__ == '__main__':
dets = np.array([[100,120,170,200,0.98],
[20,40,80,90,0.99],
[20,38,82,88,0.96],
[200,380,282,488,0.9],
[19,38,75,91, 0.8]])
py_cpu_nms(dets, 0.5)- 适用范围及可视化结果
适应范围:标准的NMS一般用于轴对齐的矩形框(即水平bbox)


局部感知NMS(LNMS)
LNMS是在EAST文本检测中提出的.主要原因:文本检测面临的是成千上万个几何体,如果用普通的NMS,其计算复杂度,n是几何体的个数,这是不可接受的.对上述时间复杂度问题,EAST提出了基于行合并几何体的方法,当然这是基于邻近几个几何体是高度相关的假设.注意:这里合并的四边形坐标是通过两个给定四边形的得分进行加权平均的,也就是说这里是“平均”而不是”选择”几何体*,目的是减少计算量.
- 基本步骤
1.先对所有的output box集合结合相应的阈值(大于阈值则进行合并,小于阈值则不和并),依次遍历进行加权合并,得到合并后的bbox集合;
2.对合并后的bbox集合进行标准的NMS操作 - 具体实现代码
import numpy as np
from shapely.geometry import Polygon
def intersection(g, p):
#取g,p中的几何体信息组成多边形
g = Polygon(g[:8].reshape((4, 2)))
p = Polygon(p[:8].reshape((4, 2)))
# 判断g,p是否为有效的多边形几何体
if not g.is_valid or not p.is_valid:
return 0
# 取两个几何体的交集和并集
inter = Polygon(g).intersection(Polygon(p)).area
union = g.area + p.area - inter
if union == 0:
return 0
else:
return inter/union
def weighted_merge(g, p):
# 取g,p两个几何体的加权(权重根据对应的检测得分计算得到)
g[:8] = (g[8] * g[:8] + p[8] * p[:8])/(g[8] + p[8])
#合并后的几何体的得分为两个几何体得分的总和
g[8] = (g[8] + p[8])
return g
def standard_nms(S, thres):
#标准NMS
order = np.argsort(S[:, 8])[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
ovr = np.array([intersection(S[i], S[t]) for t in order[1:]])
inds = np.where(ovr <= thres)[0]
order = order[inds+1]
return S[keep]
def nms_locality(polys, thres=0.3):
'''
locality aware nms of EAST
:param polys: a N*9 numpy array. first 8 coordinates, then prob
:return: boxes after nms
'''
S = [] #合并后的几何体集合
p = None #合并后的几何体
for g in polys:
if p is not None and intersection(g, p) > thres: #若两个几何体的相交面积大于指定的阈值,则进行合并
p = weighted_merge(g, p)
else: #反之,则保留当前的几何体
if p is not None:
S.append(p)
p = g
if p is not None:
S.append(p)
if len(S) == 0:
return np.array([])
return standard_nms(np.array(S), thres)
if __name__ == '__main__':
# 343,350,448,135,474,143,369,359
print(Polygon(np.array([[343, 350], [448, 135],
[474, 143], [369, 359]])).area)- 适用范围及可视化结果
适应范围:LNMS一般用于轴对齐的矩形框(即水平bbox),特别是离得很近的倾斜文本
当图像中有很多文本时候,就会产生大量的检测框(即下图中中间图中绿色的框,这里总共会产生1400多个绿色框,这里我图片压缩过了,比较模糊);经过LNMS后,得到最终的结果(即下述中的右图,即蓝色框)


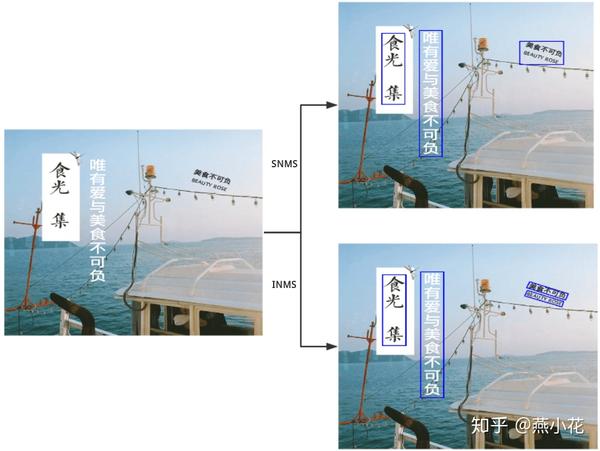
倾斜NMS(INMS)
INMS是在2018的文章中提出的,主要是解决倾斜的文本行检测.
- 基本步骤(rbox代表旋转矩形框)
1.对输出的检测框rbox按照得分进行降序排序rbox_lists;
2.依次遍历上述的rbox_lists.具体的做法是:将当前遍历的rbox与剩余的rbox进行交集运算得到相应的相交点集合,并根据判断相交点集合组成的凸边形的面积,计算每两个rbox的IOU;对于大于设定阈值的rbox进行滤除,保留小于设定阈值的rbox;
3.得到最终的检测框 - 代码实现
#coding=utf-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import cv2
import tensorflow as tf
def nms_rotate(decode_boxes, scores, iou_threshold, max_output_size,
use_angle_condition=False, angle_threshold=0, use_gpu=False, gpu_id=0):
"""
:param boxes: format [x_c, y_c, w, h, theta]
:param scores: scores of boxes
:param threshold: iou threshold (0.7 or 0.5)
:param max_output_size: max number of output
:return: the remaining index of boxes
"""
if use_gpu:
#采用gpu方式
keep = nms_rotate_gpu(boxes_list=decode_boxes,
scores=scores,
iou_threshold=iou_threshold,
angle_gap_threshold=angle_threshold,
use_angle_condition=use_angle_condition,
device_id=gpu_id)
keep = tf.cond(
tf.greater(tf.shape(keep)[0], max_output_size),
true_fn=lambda: tf.slice(keep, [0], [max_output_size]),
false_fn=lambda: keep)
else: #采用cpu方式
keep = tf.py_func(nms_rotate_cpu,
inp=[decode_boxes, scores, iou_threshold, max_output_size],
Tout=tf.int64)
return keep
def nms_rotate_cpu(boxes, scores, iou_threshold, max_output_size):
keep = [] #保留框的结果集合
order = scores.argsort()[::-1] #对检测结果得分进行降序排序
num = boxes.shape[0] #获取检测框的个数
suppressed = np.zeros((num), dtype=np.int)
for _i in range(num):
if len(keep) >= max_output_size: #若当前保留框集合中的个数大于max_output_size时,直接返回
break
i = order[_i]
if suppressed[i] == 1: #对于抑制的检测框直接跳过
continue
keep.append(i) #保留当前框的索引
r1 = ((boxes[i, 1], boxes[i, 0]), (boxes[i, 3], boxes[i, 2]), boxes[i, 4]) #根据box信息组合成opencv中的旋转bbox
print("r1:{}".format(r1))
area_r1 = boxes[i, 2] * boxes[i, 3] #计算当前检测框的面积
for _j in range(_i + 1, num): #对剩余的而进行遍历
j = order[_j]
if suppressed[i] == 1:
continue
r2 = ((boxes[j, 1], boxes[j, 0]), (boxes[j, 3], boxes[j, 2]), boxes[j, 4])
area_r2 = boxes[j, 2] * boxes[j, 3]
inter = 0.0
int_pts = cv2.rotatedRectangleIntersection(r1, r2)[1] #求两个旋转矩形的交集,并返回相交的点集合
if int_pts is not None:
order_pts = cv2.convexHull(int_pts, returnPoints=True) #求点集的凸边形
int_area = cv2.contourArea(order_pts) #计算当前点集合组成的凸边形的面积
inter = int_area * 1.0 / (area_r1 + area_r2 - int_area + 0.0000001)
if inter >= iou_threshold: #对大于设定阈值的检测框进行滤除
suppressed[j] = 1
return np.array(keep, np.int64)
# gpu的实现方式
def nms_rotate_gpu(boxes_list, scores, iou_threshold, use_angle_condition=False, angle_gap_threshold=0, device_id=0):
if use_angle_condition:
y_c, x_c, h, w, theta = tf.unstack(boxes_list, axis=1)
boxes_list = tf.transpose(tf.stack([x_c, y_c, w, h, theta]))
det_tensor = tf.concat([boxes_list, tf.expand_dims(scores, axis=1)], axis=1)
keep = tf.py_func(rotate_gpu_nms,
inp=[det_tensor, iou_threshold, device_id],
Tout=tf.int64)
return keep
else:
y_c, x_c, h, w, theta = tf.unstack(boxes_list, axis=1)
boxes_list = tf.transpose(tf.stack([x_c, y_c, w, h, theta]))
det_tensor = tf.concat([boxes_list, tf.expand_dims(scores, axis=1)], axis=1)
keep = tf.py_func(rotate_gpu_nms,
inp=[det_tensor, iou_threshold, device_id],
Tout=tf.int64)
keep = tf.reshape(keep, [-1])
return keep
if __name__ == '__main__':
boxes = np.array([[50, 40, 100, 100, 0],
[60, 50, 100, 100, 0],
[50, 30, 100, 100, -45.],
[200, 190, 100, 100, 0.]])
scores = np.array([0.99, 0.88, 0.66, 0.77])
keep = nms_rotate(tf.convert_to_tensor(boxes, dtype=tf.float32), tf.convert_to_tensor(scores, dtype=tf.float32),
0.7, 5)
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
with tf.Session() as sess:
print(sess.run(keep))- 适用范围及可视化结果
适用范围:一般适用于倾斜文本检测(即带方向的文本)

多边形NMS(PNMS)
Polygon NMS是在2017年Detecting Curve Text in the Wild: New Dataset and New Solution文章提出的,主要是针对曲线文本提出的.
- 基本步骤
其思路和标准NMS一致,将标准NMS中的矩形替换成多边形即可,这里就就不展开详细说明了 - 代码实现
#coding=utf-8
import numpy as np
from shapely.geometry import *
def py_cpu_pnms(dets, thresh):
# 获取检测坐标点及对应的得分
bbox = dets[:, :4]
scores = dets[:, 4]
#这里文本的标注采用14个点,这里获取的是这14个点的偏移
info_bbox = dets[:, 5:33]
#保存最终点坐标
pts = []
for i in xrange(dets.shape[0]):
pts.append([[int(bbox[i, 0]) + info_bbox[i, j], int(bbox[i, 1]) + info_bbox[i, j+1]] for j in xrange(0,28,2)])
areas = np.zeros(scores.shape)
#得分降序
order = scores.argsort()[::-1]
inter_areas = np.zeros((scores.shape[0], scores.shape[0]))
for il in xrange(len(pts)):
#当前点集组成多边形,并计算该多边形的面积
poly = Polygon(pts[il])
areas[il] = poly.area
#多剩余的进行遍历
for jl in xrange(il, len(pts)):
polyj = Polygon(pts[jl])
#计算两个多边形的交集,并计算对应的面积
inS = poly.intersection(polyj)
inter_areas[il][jl] = inS.area
inter_areas[jl][il] = inS.area
#下面做法和nms一样
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
ovr = inter_areas[i][order[1:]] / (areas[i] + areas[order[1:]] - inter_areas[i][order[1:]])
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep- 适用范围及可视化结果
适用范围:一般适用于不规则形状文本的检测(如曲线文本)


掩膜NMS(MNMS)
MNMS是在FTSN文本检测文章中提出的,基于分割掩膜图的基础上进行IOU计算.如果文本检测采用的是基于分割的方法来的话,个人建议采用该方法:1).它可以很好地区分相近实例文本;2)它可以处理任意形状的文本实例
- 具体步骤
1.先将所有的检测按照得分进行降序排序box_lists;
2.对box_lists进行遍历,每次遍历当前box与剩余box的IOU(它是在掩膜的基础上进行计算的,具体计算公式为 MMI=max(\frac{I}{I_A},\frac{I}{I_B}) - ),对于大于设定阈值的box进行滤除;
3.得到最终的检测框 - 实现代码
#coding=utf-8
#############################################
# mask nms 实现
# 2018.11.23 add
#############################################
import cv2
import numpy as np
import imutils
import copy
EPS=0.00001
def get_mask(box,mask):
"""根据box获取对应的掩膜"""
tmp_mask=np.zeros(mask.shape,dtype="uint8")
tmp=np.array(box.tolist(),dtype=np.int32).reshape(-1,2)
cv2.fillPoly(tmp_mask, [tmp], (255))
tmp_mask=cv2.bitwise_and(tmp_mask,mask)
return tmp_mask,cv2.countNonZero(tmp_mask)
def comput_mmi(area_a,area_b,intersect):
"""
计算MMI,2018.11.23 add
:param mask_a: 实例文本a的mask的面积
:param mask_b: 实例文本b的mask的面积
:param intersect: 实例文本a和实例文本b的相交面积
:return:
"""
if area_a==0 or area_b==0:
area_a+=EPS
area_b+=EPS
print("the area of text is 0")
return max(float(intersect)/area_a,float(intersect)/area_b)
def mask_nms(dets, mask, thres=0.3):
"""
mask nms 实现函数
:param dets: 检测结果,是一个N*9的numpy,
:param mask: 当前检测的mask
:param thres: 检测的阈值
"""
# 获取bbox及对应的score
bbox_infos=dets[:,:8]
scores=dets[:,8]
keep=[]
order=scores.argsort()[::-1]
print("order:{}".format(order))
nums=len(bbox_infos)
suppressed=np.zeros((nums), dtype=np.int)
print("lens:{}".format(nums))
# 循环遍历
for i in range(nums):
idx=order[i]
if suppressed[idx]==1:
continue
keep.append(idx)
mask_a,area_a=get_mask(bbox_infos[idx],mask)
for j in range(i,nums):
idx_j=order[j]
if suppressed[idx_j]==1:
continue
mask_b, area_b =get_mask(bbox_infos[idx_j],mask)
# 获取两个文本的相交面积
merge_mask=cv2.bitwise_and(mask_a,mask_b)
area_intersect=cv2.countNonZero(merge_mask)
#计算MMI
mmi=comput_mmi(area_a,area_b,area_intersect)
# print("area_a:{},area_b:{},inte:{},mmi:{}".format(area_a,area_b,area_intersect,mmi))
if mmi >= thres:
suppressed[idx_j] = 1
return dets[keep]- 适用范围及可视化结果
适用范围:采用分割路线的文本检测,都可以适用该方法
下图摘自论文:


总结
在文本检测中,考虑到文本方向的多样化.
- 针对水平文本检测:标准的NMS就可以
- 针对基于分割方法的多方向文本检测,优先推荐Mask NMS,当然也可以采用Polygon NMS和Inclined NMS
- 针对基于检测方法的多方向文本检测,优先推荐Polygon NMS和Inclined NMS
Mask NMS我是按照自己的思路写的,若有理解错误的地方欢迎指正.
