如何理解混合线性模型?

前面我们介绍了如何将方差分析通过模型来解读,也就是方差分析模型。例如单因素方差分析的模型解读:假设单个因素为不同职业;因变量为工资收入,那么单因素方差分析模型可以表示为:

由此可见,方差分析的模型解读是更为精准的办法,回顾该部分内容可以点击链接:SPSS分析技术:单因素方差分析结果的模型解读。
前面介绍方差分析时,我们逐步介绍了许多种方差分析类型,单因素方差分析,多因素方差分析、包括随机因素和协变量的方差分析等。如果以上情况都出现在一个分析环境中,应该如何分析呢?今天我们介绍混合效应模型中最基础的一种----混合线性模型,它就是解决这类情况的基础模型之一。
混合线性模型
混合线性模型要比前面介绍的方差分析模型更加复杂,为了通俗解释。我们引入例子进行说明。假设现在有来自100所学校的5000名学生的数据,该分数据包括以下变量:


现在假设分析的目的是想以入学成绩为自变量建立针对中考成绩的回归方程,则按照方差分析模型的标准思路:入学成绩(定距数据)为协变量。学校(100所学校)、学校类别(男校、女校和军事化管理学校)、性别(男和女)为因素,这些因素有的是固定因素,有的是随机因素。
如果我们只考虑学校因素(school)和入学成绩(Rscores),建立中考成绩的回归模型。如果将学校看成是固定因素(100所学校),则建立的模型如下:

将上式改写成回归模型的形式如下:

上面的回归方程看起来没什么问题,但若换个角度思考,就会发现它忽略了许多深层次的信息。可以看下面的两幅图:
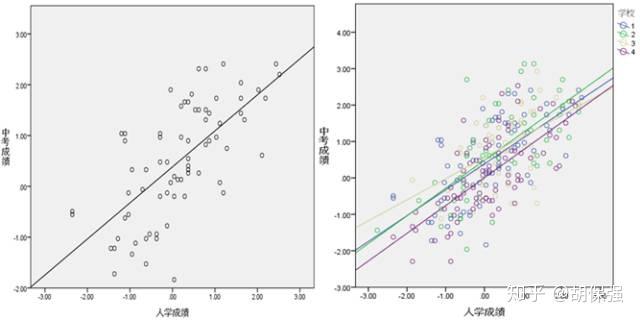

左边的散点图是只有1所学校数据的散点图,右边的散点图包括了4所学校的数据。从两幅图的趋势线可以发现,由学校因素引起的学生中考成绩(因变量)的差异既包括了截距的差异,也包括了斜率的差异。
如果只考虑一所学校的差异引起的学生中考成绩的不同,那么方差回归模型可以表示为:

其中下标i代表第i个学生。在单独考虑这一所学校时,上面的模型是非常完善的,但同时考虑多所学校时问题就出现了。从上图(右)可以发现,各个学校的教学水平是有差异的,也就是说同一所学校学生的成绩之间实际并不独立,好学校的学生成绩会普遍好一些,差学校学生的成绩会普遍差一些。
上图(右)是包含四所学校的数据,可以发现四条回归线的截距不同,这种差异实际上反映了学校间教学水平的差异,即入学成绩相同的学生,在不同学校中学习后,最后的中考成绩的平均估计值可能是不同的。若考虑到截距的变异,则刚才的模型应扩展为:

从上图(右)可以看出除了截距以外,各回归线的斜率也不相同。即成绩在学校间的聚集性除了表现为成绩的平均水平不同外,还表现在不同学校中成绩的离散度,即对中考层级的影响程度上。斜率高的学校对中考成绩影响程度较高,斜率低的则影响程度较低。根据以上推断,模型需要继续扩展:

对上面的式子进行整理,整理成下面的形式:

上式由两部分组成,分别被称为固定部分和随机部分,可见和普通线型模型相比,混合线性模型主要是对原先的随机误差进行了更加精细的分解。
案例分析
由于这部分的理论需要深入理解,因此案例分析我们将放在明天介绍。明天的案例分析将以经典的介绍混合效应模型的《学校项目》数据为例进行。
