
V8 将为 React hooks 改进数组解构的性能


要说最近前端的大事件,那无疑是 React hooks 了。而根据 Chrome 团队的一份文件显示,V8 正在改进数组解构的性能。
Dan Abramov 在 React Conf 2018 上首次介绍了 React hooks,通过这个新功能,可以让我们在不写 class 的情况下也能使用状态和其他 React 的特性。使用 Hooks 的代码大概如下所示:
const [count, setCount] = useState(0);
也可在同一个函数中使用多个 hooks:
const [age, setAge] = useState(42);
const [fruit, setFruit] = useState('banana');
const [todos, setTodos] = useState([{ text: 'Learn Hooks' }]);
可以看到,React hooks 使用 ES2015 的数组解构语法。
在今年的 JSConfEU 大会上,V8 团队的 Mathias Bynens 曾经和 Dan Abramov 讨论过数组解构的问题。Mathias 的建议是使用对象解构代替数组解构,这样会带来显著的性能提升。但是如果使用对象解构语法,那么对于开发者而言则不那么友好。因为当同一个函数使用多个 use 函数时,开发者需要对每个对象解构变量重新赋值:
function ExampleWithManyStates(props) {
const {val: age, set: setAge} = useState(42);
const {val: fruit, set: setFruit} = useState('banana');
const {val: todos, set: setTodos} = useState([{ text: 'Learn Hooks' }]);
// ...
}
作为和上面例子的对比,数组解构在可读性上会更高一些。
Dan 最终还是选择了对开发者更加好友的数组解构语法,Dan 觉得大部分 React 程序都不会直接发布 ES2015 版本,而是编译成了 es5。通过使用 Babel 数组解构最终被编译成了:
function ExampleWithManyStates(props) {
// Declare multiple state variables!
var _useState = useState(42),
age = _useState[0],
setAge = _useState[1];
var _useState2 = useState("banana"),
fruit = _useState2[0],
setFruit = _useState2[1];
var _useState3 = useState([{ text: "Learn Hooks" }]),
todos = _useState3[0],
setTodos = _useState3[1];
// ...
}
但是随着 web 的发展,随着浏览器的升级,我们不能总是希望开发者提供旧版本的 js 代码。
那么现阶段数组解构的性能具体如何呢?Mathias 从 V8 字节码和机器码的角度做了详细的分析。
如果你不知道什么是字节码,可以看我之前的文章:理解 V8 的字节码。
考虑如下使用数组解构的简单代码:
function useState(x) {
return [x, y => x = y];
}
function render() {
const [x, setX] = useState(0);
return "<div>" + x + "</div>";
}
当页面初次载入时,render 函数可能会使用 V8 的解释器(Ignition )来执行。
本文使用 V8 7.2 (发布与 2018/10/31) 来分析,输出内容:
0 : StackCheck
1 : LdaGlobal [0], [0]
4 : Star r11
6 : LdaZero
7 : Star r12
9 : CallUndefinedReceiver1 r11, r12, [2]
13 : Star r0
15 : LdaNamedProperty r0, [1], [4]
19 : Star r12
21 : CallProperty0 r12, r0, [6]
25 : Mov r0, r11
28 : JumpIfJSReceiver [7] (0x2206f882056d @ 35)
30 : CallRuntime [ThrowSymbolIteratorInvalid], r0-r0
35 : Star r1
37 : LdaNamedProperty r1, [2], [8]
41 : Star r2
43 : LdaFalse
44 : Star r3
46 : LdaZero
47 : Star r6
49 : Mov <context>, r13
...
...
中间省略几百行
...
...
310 : LdaZero
311 : TestReferenceEqual r11
313 : JumpIfFalse [5] (0x2206f8820688 @ 318)
315 : Ldar r12
317 : ReThrow
318 : LdaConstant [8]
320 : Star r11
322 : Ldar r7
324 : Add r11, [22]
327 : Star r11
329 : LdaConstant [9]
331 : Add r11, [23]
334 : Return可以看到生成的字节码一共是 335 bytes,其中字节码和源码的对应关系:
function render() {
const [x, setX] = useState(0)
return "<div>" + x + "</div>"
}
useState(0)对应第 1 - 9 行(共 9 行)"<div>" + x + "</div>"对应第 318 - 331 行(共 14 行)- 函数定义和返回对应第一行和最后一行(共 2 行)
通过对比可以看到,仅仅是 const [x, setX] = state 这一句代码就一句占据了 305 bytes,其它剩余的代码则只有 30 bytes。如果仔细看生成的字节码可以找到一些原因,数组解构使用了迭代器(iteration protocol),BytecodeGenerator 为迭代器生成了完整的内联代码。
- 第 15 行 LOAD_IC,在
state上检索Symbol.iterator - 第 21 行 CALL_IC,初始化一个迭代器,返回
JSArrayIterator - 第 21 行 LOAD_IC,在迭代器上加载
next - 第 62 行 CALL_IC,调用
next函数,返回JSIterResultObject - 第 80 行 LOAD_IC,载入
done方法 - 第 91 行 LOAD_IC,载入
value方法 - 第 117 行 CALL_IC,第二次调用
next,返回一个新迭代器结果对象(JSIterResultObject ) - 第 135 行 LOAD_IC,第二次加载
done - 第 146 行 LOAD_IC,第二次加载
value
更加糟糕的事,所有的迭代器内部都是用了 try-finally 进行包裹。上面的代码一共执行了 9 次 IC 并产生了 3 个临时对象。
为了更容易理解到底发生了什么,可以考虑如下(伪)代码:
function render() {
var state = useState(0);
var x, setX;
var it = state[Symbol.iterator]();
var nextFn = it.next;
var done = true;
try {
var result = nextFn.call(it);
if (!(done = result.done)) {
x = result.value;
result = nextFn.call(it);
if (!(done = result.done)) {
setX = result.value;
}
}
} finally {
if (!done) {
var returnFn = it["return"];
if (typeof returnFn === "function") returnFn.call(it);
}
}
return "<div>" + x + "</div>";
}
其中的对应关系可以很明显的分析出来。上面代码只是一个示例,并不能成功运行,也不是 100% 等价。但是可以清楚的看到调用了 2 次 done 和 2 次 value,对应的字节码指令是 LdaNamedProperty。
我们再看一下 Babel 编译后的结果:
function render() {
var _useState = useState(0),
x = _useState[0],
setX = _useState[1];
return "<div>" + x + "</div>";
}
通过 Ignition 的 BytecodeGenerator 最终生成的字节码是:
0 : StackCheck
1 : LdaGlobal [0], [0]
4 : Star r3
6 : LdaZero
7 : Star r4
9 : CallUndefinedReceiver1 r3, r4, [2]
13 : Star r0
15 : LdaZero
16 : LdaKeyedProperty r0, [4] // x = _useState[0]
19 : Star r1
21 : LdaSmi [1]
23 : LdaKeyedProperty r0, [6] // setX = _useState[1]
26 : Star r2
28 : LdaConstant [1]
30 : Star r3
32 : Ldar r1
34 : Add r3, [8]
37 : Star r3
39 : LdaConstant [2]
41 : Add r3, [9]
44 : Return只有 45 bytes,和 ES2015 代码相比,只有 13% 的代码量。第 16 行和第 23 行是赋值语句。可以看到性能比 ES2015 的版本高很多,而且还不需要分配临时对象。
还有一个细节就是,_useState[0] 和 _useState[1] 使用了不同的反馈向量,一个是 [4] 而另一个是 [6]。对于经常运行的代码(热代码),V8 会使用 TurboFan 编译器将字节码实时编译为机器码,由于 js 是动态类型的,因此 V8 需要提供一个反馈向量,当 js 使用不同类型执行同一行代码时,V8 会进行去优化操作,也就是舍弃掉已经编译好的机器码,根据新类型重新编译或者直接运行字节码。
那如果我们使用对象解构呢?
function useState(x) {
return {val: x, set(y) { x = y; }}
}
function render() {
const {val: x, set: setX} = useState(0);
return "<div>" + x + "</div>";
}
生成的字节码:
0 : StackCheck
1 : LdaGlobal [0], [0]
4 : Star r3
6 : LdaZero
7 : Star r4
9 : CallUndefinedReceiver1 r3, r4, [2]
13 : Star r0
15 : JumpIfUndefined [6] (0x37efef72062f @ 21)
17 : Ldar r0
19 : JumpIfNotNull [16] (0x37efef72063d @ 35)
21 : LdaSmi [81]
23 : Star r3
25 : LdaConstant [1]
27 : Star r4
29 : CallRuntime [NewTypeError], r3-r4
34 : Throw
35 : LdaNamedProperty r0, [1], [4] // 这里是 val
39 : Star r1
41 : LdaNamedProperty r0, [2], [6] // 这里是 set
45 : Star r2
47 : LdaConstant [3]
49 : Star r3
51 : Ldar r1
53 : Add r3, [8]
56 : Star r3
58 : LdaConstant [4]
60 : Add r3, [9]
63 : Return一共 64 bytes。和 Babel 编译完的数组解构差不多。
在 JS 中,数组也是对象
let arr = []
arr instanceof Object // true
因此我们可以对数组使用对象解构语法:
function render() {
const {0: x, 1: setX} = useState(0);
return "<div>" + x + "</div>";
}
根据基准测试的性能分析,对象解构要比 Babel 编译完的数组解构性能还要高
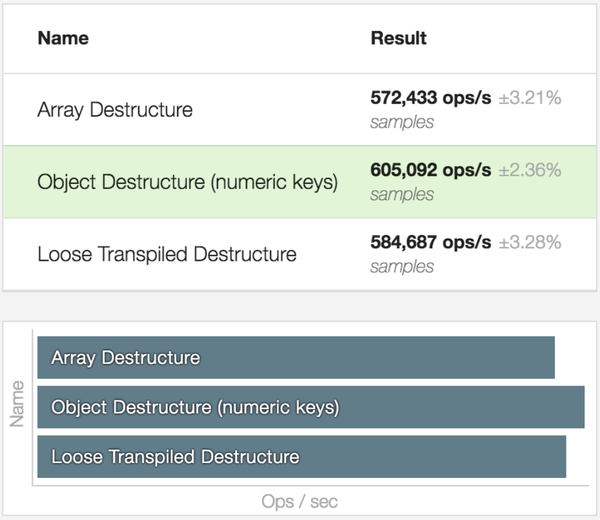

关于对象解构的性能,我之前在知乎也回答过类似问题:ES6的解构赋值前会真的创建一个传值对象,以加重GC的负担吗?。
对应的字节码:
0 : StackCheck
1 : LdaGlobal [0], [0]
4 : Star r3
6 : LdaZero
7 : Star r4
9 : CallUndefinedReceiver1 r3, r4, [2]
13 : Star r0
15 : JumpIfUndefined [6] (0xe6cf78a0627 @ 21)
17 : Ldar r0
19 : JumpIfNotNull [16] (0xe6cf78a0635 @ 35)
21 : LdaSmi [80]
23 : Star r3
25 : LdaConstant [1]
27 : Star r4
29 : CallRuntime [NewTypeError], r3-r4
34 : Throw
35 : LdaZero
36 : LdaKeyedProperty r0, [4]
39 : Star r1
41 : LdaSmi [1]
43 : LdaKeyedProperty r0, [6]
46 : Star r2
48 : LdaConstant [2]
50 : Star r3
52 : Ldar r1
54 : Add r3, [8]
57 : Star r3
59 : LdaConstant [3]
61 : Add r3, [9]
64 : Return一共 65 bytes,只比 Babel 编译完的数组解构多 1 个字节。
但是这种写法和对象解构有同样的问题,就是对开发者不够友好。
当我们多次调用 render 函数时,TurboFan 会进一步优化,将字节码编译为机器码。关于不同语法的机器码的对比在此就不列举了。
不论是直接执行字节码,还是执行机器码,数组解构的性能都比对象解构要低不少。在页面加载(也就是初始渲染)的过程中,大多数代码将在解释器中运行,那么优化数组解构的字节码比较有意义。根据对 TurboFan 引擎内部的 Array.prototype[Symbol.iterator] 和 %ArrayIteratorPrototype%.next() 分析,我们可以在特殊情况中去掉迭代协议。所以我们可以识别简单的数组解构:
const [a, b] = iterable;
我们可以不必把整个迭代协议内联到生成的字节码中,取而代之的是使用单一的字节码指令:
DestructureArray iterable, ra-rb这样我们甚至可以使用寄存器来存储迭代器的值,此代码还可以为 TurboFan 收集关于迭代器的信息反馈。因为当 JSArray 实例是一个快速元素并且 Array.prototype 原型链没有元素时,可以直接生成高效的机器码。如果 JSArray 是其他类型时,则进行去优化操作。
当数组元素少于 2 个时,我们甚至可以进一步优化,伪代码如下:
CheckHeapObject(iterable)
CheckMaps[array map](iterable)
length = LoadField[length](iterable)
CheckBounds(1, length)
elements = LoadField[elements](iterable)
ra = LoadElement(iterable, 0)
rb = LoadElement(iterable, 1)
优化完后的代码甚至比 Babel 生成的代码还要高效。
不仅是为了提升 React Hooks 的性能,V8 团队还打算使用一种更加廉价的迭代协议来处理特殊的数组。伪代码大概如下:
[iterator, next_method] = GetIterator(iterable)
loop {
iter_result = IteratorNext(iterator, next_method)
if (IteratorComplete(iterator, iter_result)) break;
value = IteratorValue(iterator, iter_result);
// …
}
当数组是快速元素并且 Array.prototype 原型链没有元素时,这个迭代协议可以用于 for..in 和 for..of。
不少开发者还会使用一种奇技淫巧来交换两个变量的值,而不需要借助第三个变量。一个最简单的方式就是使用数组解构赋值:
[a, b] = [b, a];
而这个代码也有严重的性能问题,同样会多次调用迭代对象的方法并在引擎内部生成了多个临时对象。而最好的方式就是,V8 引擎直接识别这种模式,从而生成专用的字节码:
Swap ra-rb目前还没有相关的数据来说明以上提案到底有多重要,或许最后 V8 只是实现了一个优化版本的迭代协议来为特殊数组提升性能,或许 V8 会为特殊场景增加新的字节码。
推荐阅读:
- Array destructuring for multi-value returns (in light of React hooks)
- ES6的解构赋值前会真的创建一个传值对象,以加重GC的负担吗?
- JavaScript 引擎基础:Shapes 和 Inline Caches
- JavaScript 在 V8 中的元素种类及性能优化
最后做个小广告,我正在翻译 V8 官网的文章,如果你对 V8 感兴趣,可以加入一起翻译:
