TVM如何帮助部署隐私保护和安全的AI应用

导论:保护数据隐私的需求
一直以来,机器学习模型尤其是深度学习模型的成功往往建立在大规模数据的基础之上。然而在现实生活中,并不是所有的数据都适合被直接被拿来训练。比方说医疗与金融这类敏感应用,相当一部分数据是个人的隐私数据,这意味着在这样的数据集上进行训练存在着泄露患者隐私或者商业机密的风险。迄今为止,已经有相当多的工作关注在如何在这类私密数据上进行机器学习模型的训练同时保证数据的隐私。比如说安全和隐私保护计算领域最新进展里的TEE(可信执行环境, Trusted Execution Environments),以及差分隐私(Differential Privacy)等工作,这些工作为互不信任的各方提供了一种有效地训练机器学习模型而不泄露训练数据的方法。
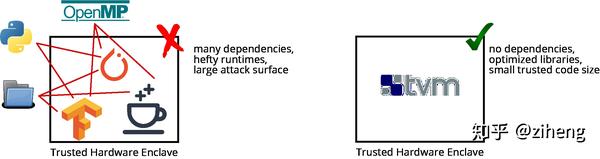

来自UC Berkeley的Nick Hynes同学在进行隐私保护方向的研究时,发现相比于其它的机器学习框架,TVM完美适合了在资源有限的TEE环境中部署机器学习模型这一场景。本文则希望向大家分享这一发现。
需求场景
事实上,希望保护训练数据隐私这样的场景不在少数:

- 区块链上的机器学习。目前已有一些区块链项目尝试去发起用户来训练链上的机器学习模型,然而需要解决的一个问题是,当用户使用自己的隐私数据去训练链上模型时,如何保证隐私数据不会被泄露。
- 保证隐私的MLaaS。云提供商在用户的数据上运行他们的机器学习模型。 用户得到模型输出且保证自己的数据保持私密,而云提供商则需要确保用户无法窃取模型。
- 可信的机器学习比赛。参赛者在比赛数据上训练模型。 比赛组织者将私密的测试数据发送到参赛者的模型并获得可验证的准确性结果。 在组织者决定采用参赛者的模型之前,参赛者的模型需要保证安全。 并且参赛者也无法获得测试数据的信息从而在测试数据上进行训练来作弊。
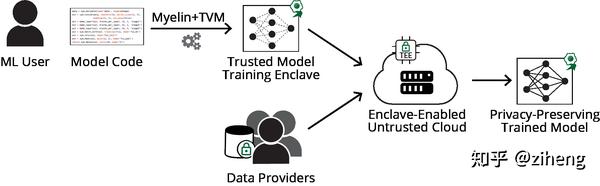
- 在一些隐私数据上训练。假设研究人员希望在医院的数据上训练模型,然而医院的数据往往无法被直接授予使用,所以需要有一个“受信任的第三方”来训练一个隐私保护的模型。
TEE是什么

TEE(可信执行环境, Trusted Execution Environment)本质上允许远程用户可以在另一个用户的机器上运行代码而不向硬件提供者透露计算的内容。
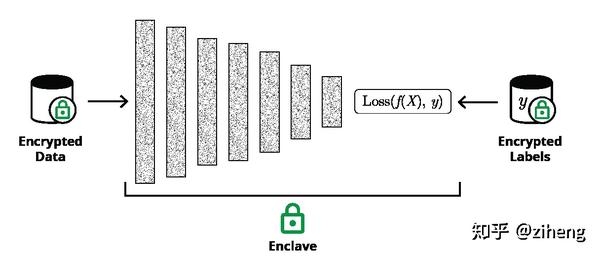
技术上来讲,TEE提供了一块包含隔离或加密的存储器和CPU寄存器的安全区域——enclave,以及可信的随机来源。TEE还可以发送已加载代码的签名,以便远程用户可以验证代码已正确加载进安全区域enclave中。该过程称为远程证明,可用于建立进入enclave的安全信道。在这之后,远程用户可以确保安全的为应用配置私钥,模型参数和训练数据。
与诸如安全多奇偶校验计算(MPC)和完全同态加密(FHE)的纯加密方法相比,TEE快几个数量级并且支持通用计算。唯一的缺点也许是硬件信任根(烧入处理器的密钥)和加载软件过程中所需要的额外信任假设。
事实上,TEE技术正变得越来越普遍,并且在实际隐私保护方面发挥着重要作用。事实上,通用的TEE技术已经应用在Intel SGX和ARM TrustZone等商用硬件中。此外,完全开源的Keystone Enclave正在开发中。
TVM如何帮助在TEE上部署模型
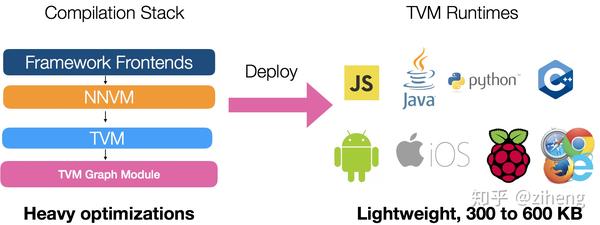
使用TEE的主要挑战之一是在TEE内部运行的代码无法访问不受信任的操作系统。这意味着可信软件无法创建线程或者执行IO操作。因而导致了像OpenBLAS这样的代数库不能直接在enclave上运行,更不用说其它的深度学习框架如PyTorch和TensorFlow。而相比于其它的机器学习框架,TVM能够将机器学习模型编译成非常轻量化,高度优化,且没有外部依赖的库,因而完美适合了在资源有限的enclave上部署机器学习模型这样一类的场景。
TEE实际上有着与资源受限的硬件加速器相类似的编程模型,而这恰恰是TVM被创造的原因!在整个工作流程中,用户首先使用高层的图表示语言来表示整张训练的计算图。 TVM随后编译模型并输出一个包含高度优化算子的静态库,这可以很容易地加载到TEE中。由于算子是自动生成的并且具有严格的边界检查,这充分减小了攻击面。并且它们被轻量且内存安全的Rust runtime来装载运行,也同样可以轻松检查其安全性和正确性。

当然,效率也是实际应用时需要考量的另一个维度。通过使用runtime来协调线程,单个TVM enclave可以充分利用其主机的资源。这使得enclave中的TVM模块具有与基于CPU的本机训练相当的性能。同时,TVM还提供了对算法进行更细粒度优化的机会。在差分隐私算法中,需要裁剪每个训练sample的梯度并添加一定的噪声。TVM的调度原语使得实现优化变得简单与高效,同时,得益于Operator Fusion等内置优化,TVM能将裁剪与噪声操作进行融合并原地(in-place)计算从而进一步减少延迟与内存消耗。这使得我们能够应用差分隐私算法且不会引入过高的开销。
小结
下一代机器学习系统很有可能迎来隐私保护的话题。 随着TEE技术变得更易于理解和更加广泛的应用,尝试使用它去部署隐私保护机器学习模型十分有意义,而TVM则很有可能有助于该方向的研究与开发。欢迎大家尝试探索以及加入TVM社区。
资源链接
- 英文博客: https://tvm.ai/2018/10/09/ml-in-tees.html
- 技术报告: https://arxiv.org/abs/1807.06689
- TVM in Intel SGX示例: https://github.com/dmlc/tvm/tree/master/apps/sgx

