
Attention机制详解(一)——Seq2Seq中的Attention

Attention模型在机器学习领域越来越得到广泛的应用,准备写一个关于Attention模型的专题,主要分为三个部分:(一)在Seq2Seq 问题中RNN与Attention的结合。 (二)抛除RNN的Self-Attention模型以及谷歌的Transformer架构。 (三)Attention及Transformer在自然语言处理及图像处理等方面的应用。主要参考资料是Yoshua Bengio组的论文、谷歌研究组的论文及Tensor2Tensor的官方文档、斯坦福自然语言处理相关部分讲义等。
这一篇先来介绍早期的在Machine Translation(机器翻译)中Attention机制与RNN的结合。
RNN结构的局限
机器翻译解决的是输入是一串在某种语言中的一句话,输出是目标语言相对应的话的问题,如将德语中的一段话翻译成合适的英语。之前的Neural Machine Translation(一下简称NMT)模型中,通常的配置是encoder-decoder结构,即encoder读取输入的句子将其转换为定长的一个向量,然后decoder再将这个向量翻译成对应的目标语言的文字。通常encoder及decoder均采用RNN结构如LSTM或GRU等(RNN基础知识可参考循环神经网络RNN——深度学习第十章),如下图所示,我们利用encoder RNN将输入语句信息总结到最后一个hidden vector中,并将其作为decoder初始的hidden vector,利用decoder解码成对应的其他语言中的文字。
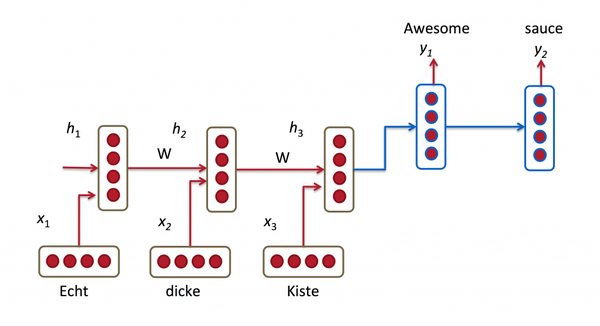

但是这个结构有些问题,尤其是RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
Attention机制的引入
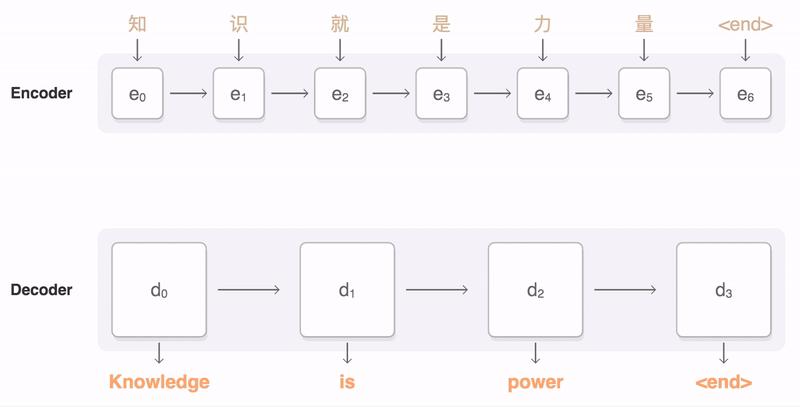
为了解决这一由长序列到定长向量转化而造成的信息损失的瓶颈,Attention注意力机制被引入了。Attention机制跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文。同样的,Attention模型中,当我们翻译当前词语时,我们会寻找源语句中相对应的几个词语,并结合之前的已经翻译的部分作出相应的翻译,如下图所示,当我们翻译“knowledge”时,只需将注意力放在源句中“知识”的部分,当翻译“power”时,只需将注意力集中在"力量“。这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。

以上是直观理解,我们来详细的解释一下数学上对应哪些运算。
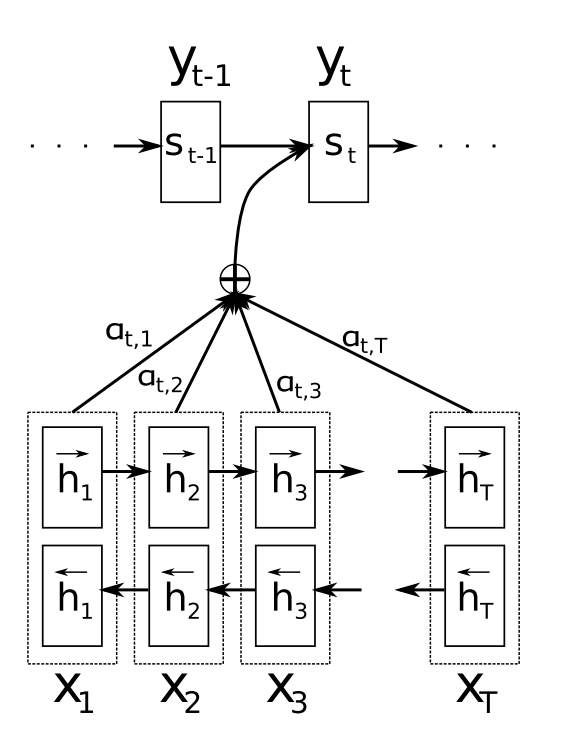
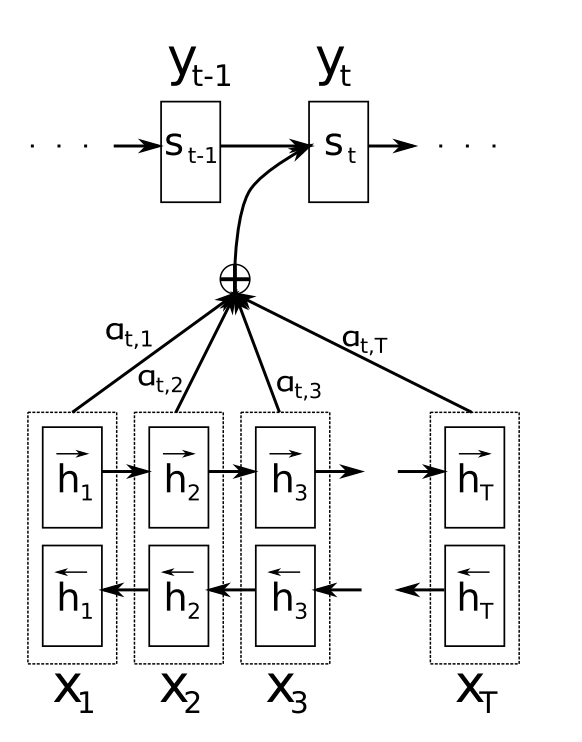
- 首先我们利用RNN结构得到encoder中的hidden state (h_1, h_2, ..., h_T) ,
- 假设当前decoder的hidden state 是 s_{t-1} ,我们可以计算每一个输入位置j与当前输出位置的关联性, e_{tj}=a(s_{t-1}, h_j) ,写成相应的向量形式即为 \vec{e_t}=(a(s_{t-1},h_1),...,a(s_{t-1},h_T)) ,其中 a 是一种相关性的算符,例如常见的有点乘形式 \vec{e_t}=\vec{s_{t-1}}^T\vec{h} ,加权点乘 \vec{e_t}=\vec{s_{t-1}}^TW\vec{h} ,加和 \vec{e_t}=\vec{v}^Ttanh(W_1\vec{h}+W_2\vec{s_{t-1}}) 等等。
- 对于 \vec{e_t} 进行softmax操作将其normalize得到attention的分布, \vec{\alpha_t}=softmax(\vec{e_t}) ,展开形式为 \alpha_{tj}=\frac{exp(e_{tj})}{\sum_{k=1}^Texp(e_{tk})}
- 利用 \vec{\alpha_t} 我们可以进行加权求和得到相应的context vector \vec{c_t} = \sum_{j=1}^T\alpha_{tj}h_j
- 由此,我们可以计算decoder的下一个hidden state s_t = f(s_{t-1},y_{t-1},c_t) 以及该位置的输出 p(y_t|y_1,...,y_{t-1}, \vec{x}) = g(y_{i-1}, s_i, c_i) 。
这里关键的操作是计算encoder与decoder state之间的关联性的权重,得到Attention分布,从而对于当前输出位置得到比较重要的输入位置的权重,在预测输出时相应的会占较大的比重。
通过Attention机制的引入,我们打破了只能利用encoder最终单一向量结果的限制,从而使模型可以集中在所有对于下一个目标单词重要的输入信息上,使模型效果得到极大的改善。还有一个优点是,我们通过观察attention 权重矩阵的变化,可以更好地知道哪部分翻译对应哪部分源文字,有助于更好的理解模型工作机制,如下图所示。


当然,一个自然的疑问是,Attention机制如此有效,那么我们可不可以去掉模型中的RNN部分,仅仅利用Attention呢?下一篇会详细解释谷歌在Attention is All you need中提出的self-attention机制及Transformer架构
。
参考资料:
[1] CS224n: Natural Language Processing with Deep Learning 斯坦福自然语言处理教程。
[2]Neural Machine Translation by jointly learning to align and translate. D Bahdanau, etc。
[3]Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) 可视化NMT的博客。
[4]Overview - seq2seq TF seq2seq文档。
