Attention机制简单总结

本来是想接CMU的NLP公开课的坑的,但是发现讲attention这块内容的公开课程质量着实不高,教授说话声音模糊。(说实话这门公开课的质量都不太好,对萌新不太友好,不过它比斯坦福的cs224n内容多一点,建议学完cs224n再来看这门课会好一点。)再加上最近做一个headline generation的比赛,要用到的attention的地方很多,因此把之前比赛中以及课程中的attention知识简单总结一下,会参考到著名的论文:Attention is all you need。感兴趣的可以去读这篇论文,真的是一篇有划时代意义的论文。
备注:由于attention自被广泛运用以来,涌现出了很多attention的变体,各种奇技淫巧层出不穷,本文篇幅有限,只会讲几个最基本的attention方法。
What is attention?
先简单描述一下attention机制是什么。相信做NLP的同学对这个机制不会很陌生,它在Attention is all you need可以说是大放异彩,在machine translation任务中,帮助深度模型在性能上有了很大的提升,输出了当时最好的state-of-art model。当然该模型除了attention机制外,还用了很多有用的trick,以帮助提升模型性能。但是不能否认的时,这个模型的核心就是attention。
attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
Why attention?
照例讲一下为什么要引入attention机制。在之前总结过的seq2seq模型以及之前做NLP的比赛中,对于一段文本序列,我们通常要使用某种机制对该序列进行编码,通过降维等方式将其encode成一个固定长度的向量,用于输入到后面的全连接层。

一般我们会使用CNN或者RNN(包括GRU或者LSTM)等模型来对序列数据进行编码,然后采用各种pooling或者对RNN直接取最后一个t时刻的hidden state作为句子的向量输出。这里会有一个问题:
常规的编码方法,无法体现对一个句子序列中不同语素的关注程度,在自然语言中,一个句子中的不同部分是有不同含义和重要性的,比如上面的例子中:I hate this movie.如果做情感分析,明显对hate这个词语应当关注更多。当然是用CNN和RNN能够编码这种信息。但是如果序列长度很长的情况下,这种方法会有一定的瓶颈。拿CNN举例,具体如下图:图来自“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统


CNN的核心就是卷积核能够变相学习n-gram的信息,如果是用hierarchical的卷积核,那么越上层的卷积核越能编码原始距离较远的词组的信息。但是这种编码能力也是有上限的,对于较长的文本,模型效果不会再提升太多。RNN也是同理。
基于参加达观文本分类的经历,对于这种长文本处理,使用RNN+attention的效果比使用单纯的RNN+pooling的效果要好不少。
How to use attention?
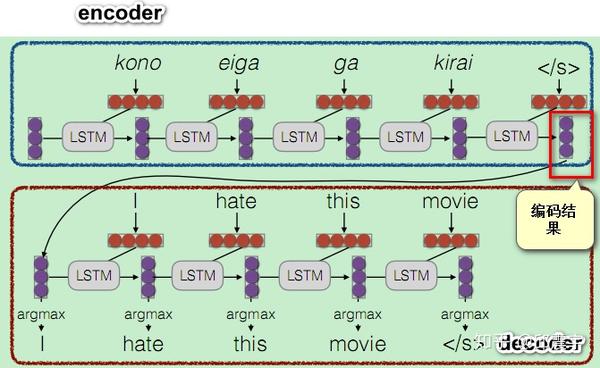
首先讲一下attention最基本最抽象的流程。以seq2seq模型为例。
基本流程:对于一个句子序列S,其由单词序列[w1,w2,w3,...,wn]构成。
1、应用某种方法S的每个单词 w_i 编码为一个单独向量 v_i 。
2、解码时,使用学习到的注意力权重 a_i 对1中得到的所有单词向量做加权线性组合\sum_{i}^{}{a_iv_i}.
3、在decoder进行下一个词的预测时,使用2中得到的线性组合。
具体构成如下:
我们的最终目标是要能够帮助decoder在生成词语时,有一个不同词语的权重的参考。在训练时,对于decoder我们是有训练目标的,此时将decoder中的信息定义为一个Query。而encoder中包含了所有可能出现的词语,我们将其作为一个字典,该字典的key为所有encoder的序列信息。n个单词相当于当前字典中有n条记录,而字典的value通常也是所有encoder的序列信息。
上面对应于第一步,然后是第二部计算注意力权重,由于我们要让模型自己去学习该对哪些语素重点关注,因此要用我们的学习目标Query来参与这个过程,因此对于Query的每个向量,通过一个函数 a_i = F(Q_i,K) ,计算预测i时刻词时,需要学习的注意力权重,由于包含n个单词,因此, a_i 应当是一个n维的向量,为了后续计算方便,需要将该向量进行softmax归一化,让向量的每一维元素都是一个概率值。

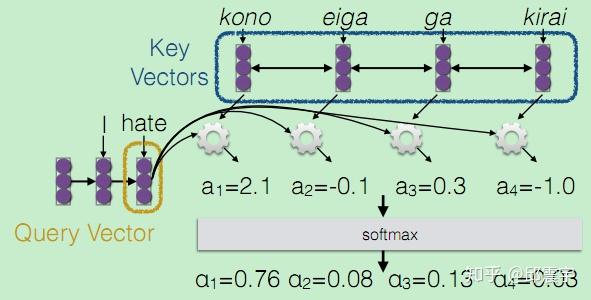
最后对Value vectors进行加权线性组合,得到带权重参考的“字典”输出:


权重计算函数
眼尖的同学肯定发现这个attention机制比较核心的地方就是如何对Query和key计算注意力权重。下面简单总结几个常用的方法:
1、多层感知机方法
a(q,k) = w_2^Ttanh(W_1[q;k])\\
主要是先将query和key进行拼接,然后接一个激活函数为tanh的全连接层,然后再与一个网络定义的权重矩阵做乘积。
这种方法据说对于大规模的数据特别有效。
2、Bilinear方法
a(q,k)=q^TWk\\
通过一个权重矩阵直接建立q和k的关系映射,比较直接,且计算速度较快。
3、Dot Product
a(q,k)=q^Tk\\
这个方法更直接,连权重矩阵都省了,直接建立q和k的关系映射,优点是计算速度更快了,且不需要参数,降低了模型的复杂度。但是需要q和k的维度要相同。
4、scaled-dot Product
上面的点积方法有一个问题,就是随着向量维度的增加,最后得到的权重也会增加,为了提升计算效率,防止数据上溢,对其进行scaling。
a(q,k)=\frac{q^Tk}{\sqrt{|k|}}\\
我个人通常会使用2和3,4。因为硬件机器性能的限制,1的方法计算比较复杂,训练成本比较高。
self-attention
关于attention有很多应用,在非seq2seq任务中,比如文本分类,或者其他分类问题,会通过self attention来使用attention。这个方法思想很简单,而且计算成本相对来说不高,强烈推荐。具体来说就是:
Query和Key,value都是相同的,即输入的句子序列信息(可以是词向量lookup后的序列信息,也可以先用cnn或者rnn进行一次序列编码后得到的处理过的序列信息。)后面的步骤与上述的都是一样的:
1、首先建立句子序列中的每个词 q_i 与句子其他词k的注意力权重 a_i
2、然后将注意力权重向量进行softmax归一化,并与句子序列的所有时刻的信息(词向量或者rnn hidden state)进行线性加权。


这种方法中,句子中的每个词都能与句子中任意距离的其他词建立一个敏感的关系,可以说在一定程度上提升了之前所说的CNN和RNN对于长距离语义依赖建模能力的上限。下图同样来自:“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统


Multi-head attention
下面介绍另一种很有效的attention使用方法,叫multi-head attention。这个是在Attention is all you need这篇论文中被使用。图例如下:

公式化表示如下:
multihead(Q,K,V)=concat(head_1,head_2,...,head_h)W^o\\ head_i=attention(QW^Q,KW^K,VW^V)
解释一下,与原来的self-attention的核心原理其实是差不多的,但是由于self attention只从一个角度去学习关注点,可能会有点偏颇。所以,设计h种不同的 (W_i^Q,W_i^K,W_i^V) 权重矩阵对,然后做基本的attention操作前,将query,key和value分别用上述权重对做线性变换,然后再计算得到h个不同角度的attention权重 head_i ,将这些 head_i 按列拼接后,再与一个新的权重矩阵 W^o 做线性变换,得到最终的attention输出。
这里要重点说一个问题,就是关于multihead的每个权重矩阵的维度。做self attention时,若使用Bilineard方式,也有一个权重矩阵W,这个权重矩阵维度一般是与Q、K、V的维度是一样的(通常做法,也有不一样的,但是维度不会低)。但是做multihead时,如果对每个权重矩阵的维度还是设为原始维度,那么计算的成本将会蹭蹭得往上涨。如果硬件性能不太行,极有可能会报OOM问题。(不要问我怎么知道的,惨痛的经历。。。)所以通常的做法是:设三种权重矩阵 (W_i^Q,W_i^K,W_i^V) 的维度分别为 (d^q,d^k,d^v) ,原始维度为d,那么 d^q=d^k=d^v=d/h\\
only attention without RNN?
看到有些文章或者博客对attention is all you need中的transformer模型的解读,可能不太完整,似乎只要用attention,就能秒杀其他任何模型。有些同学可能觉得以前的RNN,CNN都不需要了。其实个人感觉,将RNN与attention结合是能拿到好的结果的。为什么transformer没有使用RNN也能对序列数据有很好的建模效果?因为它用了很多其他的trick,首先就是使用了positional embedding,即将词语在句子中的位置关系也做了embedding,它的目的就是通过与原始词向量和attention结合,构建词序上的关系信息,这样就省去了rnn的网络结构,使得训练成本大大降低。但是它的embedding的初始化是一种带正弦函数和余弦函数的数学先验很强的一个方法,可能对其他任务不是太适用,且调这个参数也是比较难的。因此对于个人学习或者研究来说,可以尝试,但是使用RNN还是一个比较稳定的方法,虽然它的训练还是很比较慢的。。。
后记
本文只是简单讲了几个最基础的attention方法,还有很多有效复杂的方法未涉及,比如global attention,local attention,hard attention等等,还有之前做文本分类时了解过的HAN(hierarchical attention network,是先对一个句子里面的词做attention,然后对文章中的句子做attention,相当于做了一个二层结果的层次attention)有兴趣的同学可以直接看论文了解。
引用:
cmu nlp公开课
