
左手读红楼梦,右手写BUG,闲快活

想不出合适的标题,很喜欢关汉卿的这组元曲,就胡乱取了,顺便安利下。
适意行,安心坐,渴时饮饥时餐醉时歌,困来时就向莎茵卧。日月长,天地阔,闲快活!
旧酒投,新醅泼,老瓦盆边笑呵呵,共山僧野叟闲吟和。他出一对鸡,我出一个鹅,闲快活!
意马收,心猿锁,跳出红尘恶风波,槐阴午梦谁惊破?离了利名场,钻入安乐窝,闲快活!
南亩耕,东山卧,世态人情经历多,闲将往事思量过。贤的是他,愚的是我,争甚么?
——元·关汉卿《四块玉·闲适》
本文代码开源在:GitHub - DesertsX/gulius-projects
复杂
上一篇文章里安利了这个非常惊艳的关于红楼梦的可视化作品:InteractiveGraph/example1。


有不少人喜欢,也有人说如此复杂的图谱,反而会使人觉得头大。其实我也有此感受,对于红迷们来说,书中内容情节、人物关系都是很熟悉的,这样的关系图一点点看起来自然不会太费劲。

可整个作品还是蛮复杂的,即便人物、事件、地点、关系等以不同颜色区别开来并在节点上附有详情介绍,且右上角亦有可交互的选项,但毕竟成百上千的节点和边交织在一个网页里,对于不熟悉红楼梦的人来说,就更觉错综复杂了。
这里也想起之前接触的一个知识图谱API,其实同样也不知道这些实体与关系,对于个人而言能有什么切入点、可以怎么利用起来。下图展示了该知识图谱关于邓婕的所有信息。大家可自行更改最后的参数,就能看到其他所有实体的情况了,比如entity=胡歌等等。


两个缘由
言归正传,基于上文提到关系图谱的复杂面貌的缘故,以及最近接触了些依存句法分析、信息抽取、事件图谱等知识(后续会写写这方面内容),因而也对实际项目中如何从非结构化的文本内容中抽取出结构化的数据非常感兴趣。
比如本项目里,究竟是如何从1600余页、73万余字的《红楼梦》原著中提取出人物关系、情节事件的呢?想来应该不会人工手动实现的吧?如果能知晓实现的流程和技术,甚至有开源的代码,那么其他人也就能轻松迁移到不同小说、不同文本领域上去,并实现同样酷炫的关系图谱了。


数据集
幸运的是,这个项目代码都是开源的,GitHub上介绍了详细的实现流程。参见:InteractiveGraph/README_CN。

但数据集是别处提供的,并非从头开始构建的。简单搜索了下,目前只看到两个疑似相关的项目:GitHub - lzell/nickel、GitHub - iainbeeston/nickel,有待后续进一步验证。
honglou.json
honglou.json数据集来自于中国古典名著《红楼梦》(又名《石头记》,wikipedia / Dream_of_the_Red_Chamber)。 在这部小说中贾宝玉、林黛玉、薛宝钗是主要人物。这个数据集中定义了超过300个实体,其中包括书中的人物,地点和时间,以及超过500个这些实体之间的连接。
nickel2008@github 提供了数据集。此数据集中或有纰漏,但是对于一个图数据项目的示例来说已经足够好了。
虽然遇到了些阻碍,但所幸数据集还在,不如直接去分析统计下里面的人物、地点、事件和关系,在辅助理解复杂的关系图谱的同时,看看能否逆向的获取些构建数据集的灵感启示。
准备数据
红楼梦数据集在此文件里dist/examples/honglou.json。点击raw后,全选复制新页面里的所有数据,并粘贴到本地文件中,文件名取为InteractiveGraph_HongLouMeng.json。
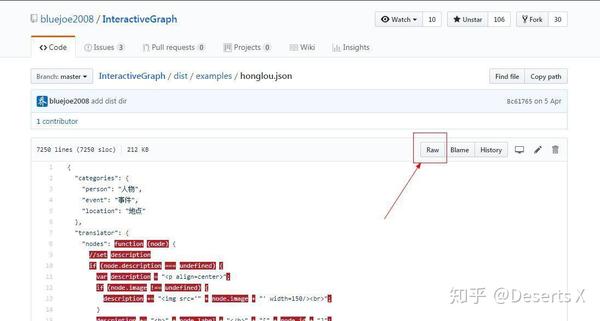

删除下面无用的代码,方可后续读取json数据时不出错。最后记得保存成utf-8编码格式。
"translator": {
"nodes": function (node) {
//set description
if (node.description === undefined) {
var description = "<p align=center>";
if (node.image !== undefined) {
description += "<img src='" + node.image + "' width=150/><br>";
}
description += "<b>" + node.label + "</b>" + "[" + node.id + "]";
description += "</p>";
if (node.info !== undefined) {
description += "<p align=left>" + node.info + "</p>";
} else {
if (node.title !== undefined)
description += "<p align=left>" + node.title + "</p>";
}
node.description = description;
}
},
},
简单展示下数据格式,其实和GitHub上的差不多:
{
"categories": {
"person": "人物",
"event": "事件",
"location": "地点"
},
"data": {
"nodes": [{
"label": "共读西厢",
"value": 2,
"id": 3779,
"categories": [
"event"
],
"info": "宝玉到沁芳桥边桃花底下看《西厢记》,正准备将落花送进池中,黛玉说她早已准备了一个花冢,正来葬花。黛玉发现《西厢记》,宝玉借书中词句,向黛玉表白。黛玉觉得冒犯了自己尊严,引起口角,宝玉赔礼讨饶,黛玉也借《西厢记》词句,嘲笑了宝玉。于是两人收拾落花,葬到花冢里去。"
},
......
],
"edges": [{
"id": 3776,
"label": "位于",
"from": 3838,
"to": 3851
},
...
]
读取数据
以上,完成了数据准备过程,接下来可以开始在jupyter notebook里进行分析挖掘。
import json
import codecs
with codecs.open('InteractiveGraph_HongLouMeng.json', 'r',encoding='utf-8') as json_str:
json_dict = json.load(json_str)
print(json_dict.keys())
print(json_dict["categories"].keys())
print(json_dict["categories"])
nodes = json_dict['data']['nodes']
edges = json_dict['data']['edges']
层级关系大致如此,categories和data同一级,节点nodes和边edges同一级,并且归属于data,也是本次要统计分析的所有数据,categories指明三种节点数据类型,即:'person': '人物', 'event': '事件', 'location': '地点。
dict_keys(['categories', 'data'])
dict_keys(['person', 'event', 'location'])
dict_keys(['nodes', 'edges'])
{'person': '人物', 'event': '事件', 'location': '地点'}
红楼多少事
首先来看看数据中都包含了哪些红楼梦中的事件,直接筛选出类型为event的节点,共拿到59条数据。
event_nodes = []
for num, node in enumerate(nodes):
if node['categories'][0] == 'event':
event_nodes.append(node)
print(len(event_nodes))
字典元素组成的列表直接用pandas转成表格格式:
import pandas as pd
df = pd.DataFrame(event_nodes)
df.head()
其中label就是事件名称,info是内容简介,value貌似是觉得节点大小的,未做细究,本次均不做探索。


将事件全部提取出来:
events = df['label'].values.tolist()
events
存成列表格式,方便后续处理,注意,所有事件并非按照小说里情节发展的顺序排列的,所以看起来会较为混乱:
['共读西厢', '林如海捐馆扬州城', '海棠诗社', '紫鹃试玉',
'魇魔姊弟', '羞笼红麝串', '麒麟伏双星', '纳鸳鸯',
'撵晴雯', '偷娶尤二姐', '软语救贾琏', '大闹学堂',
'拐卖巧姐', '乱判葫芦案', '毒设相思局', '情赠茜香罗',
'勇救薛蟠', '倪二轻财尚义', '神游太虚幻境', '借剑杀人',
'平儿失镯', '平儿行权', '司棋被捉', '巧结梅花络',
'亲尝莲叶羹', '宝玉挨打', '大闹厨房', '香菱学诗',
'凤姐托孤', '旺儿妇霸成亲', '弄权铁槛寺', '智能偷情',
'勾引薛蝌', '贾政借钱', '探春远嫁', '刘姥姥一进荣国府',
'黛玉葬花', '宝钗扑蝶', '金钏投井', '大观园试才',
'秦可卿淫丧天香楼', '迎春误嫁中山狼', '金玉良缘', '王熙凤协理宁国府',
'元妃省亲', '甄士隐梦幻识通灵', '晴雯撕扇', '凤姐泼醋',
'探春理家', '湘云醉眠芍药裀', '尤三姐殉情', '抄检大观园',
'黛玉焚稿', '黛玉之死', '晴雯补裘', '元宵丢英莲',
'冷子兴演说荣国府', '木石前盟', '贤袭人娇嗔箴宝玉']
拿到这些事件后下一步该怎么办?让我们再明确下本文的目的之一,即看看能否逆向找出数据构造的规则与逻辑。那么自然而然的就有一个问题:这些事件都是如何从原著中抽取出来或者总结出来的呢?


作为中国古典四大名著之首的《红楼梦》,有1600余页、73万余字(人民文学出版社版本),涉及的人物和事件繁多,若是单纯靠人工去总结,显然并不可取,而且也无法迁移到其他文本上去。当然,《红楼梦》本身广受读者喜爱,历来研究的人也多,且妇孺皆知、耳熟能详,网上现成的人物名单、事件罗列,想来或多或少都是有的,此处暂且不表。
考虑到《红楼梦》本身是章回体小说,各章回的名字高度总结概括了本章的内容,一个合理的猜想就是从章回中直接抽取出事件内容。那么就来看看这59条数据里有多少是完全和章回名重合的呢?


获取章节名
首先从《红楼梦》小说章节目录网站获取各章回名称,简单写个爬虫就行。
import requests
from lxml import etree
url = 'https://www.555zw.com/book/39/39480/'
r = requests.get(url)
r.encoding = r.apparent_encoding
selector = etree.HTML(r.content)
contents = selector.xpath('//tr//a/@title')
print(len(contents))
contents
注意需要设置编码格式,否则会乱码。展示部分数据
120
['第一回 甄士隐梦幻识通灵 贾雨村风尘怀闺秀',
'第二回 贾夫人仙逝扬州城 冷子兴演说荣国府',
'第三回 贾雨村夤缘复旧职 林黛玉抛父进京都',
'第四回 薄命女偏逢薄命郎 葫芦僧乱判葫芦案',
'第五回 游幻境指迷十二钗 饮仙醪曲演红楼梦',
'第六回 贾宝玉初试云雨情 刘姥姥一进荣国府',
...]
经过一些简单处理后(具体可见代码:GitHub - DesertsX/gulius-projects,本文略过),拿到章回与事件对应关系
chapter_df = pd.DataFrame({"chapter":chapters, "title":contents})
def is_event(title):
for event in event_chaps:
if event in title:
return event
return ''
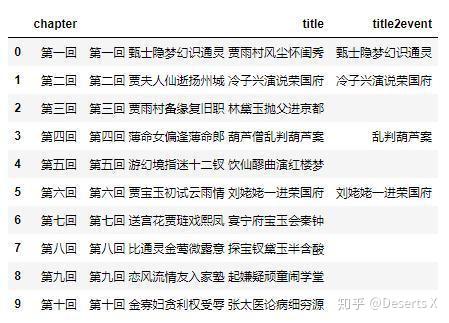
chapter_df['title2event'] = chapter_df['title'].apply(is_event)
chapter_df.head(10)
title2event列可以看成能直接从章回名中提前出事件名。

接着将title2event列非空的所有行都标上颜色,由于在整个表格里只标出特定的行的代码写不出来(太菜),只能将非空的行选出来后再设置颜色。
chapter_df[chapter_df.title2event != '']
.style.set_properties(**{'background-color': '#ccff99', 'color': '#B452CD'})
因为很少看到有人像在excel一样,用不同颜色显示jupyter notebook里的表格数据,于是搜了下,还真有实现的方式:pandas-docs/style。
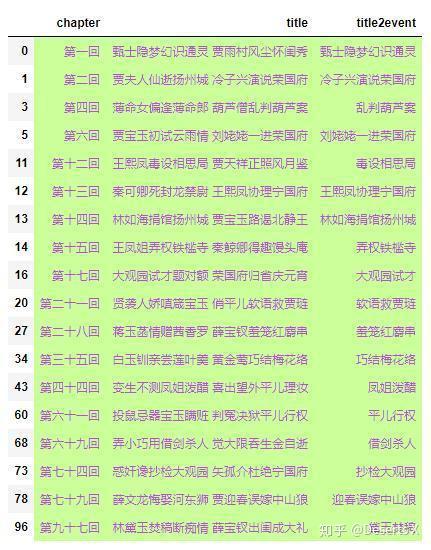

由上图可知,共有18条(18/59=30%)事件是一字不差包含在章回名里的。不过感觉非红迷的朋友,可能不熟悉这些事件到底是什么情节(是这样吗?)
非章节名的事件
接着看看其他41条事件,这里按人物角色和小说情节出现的前后顺序进行简单整理,比较耳熟能详的有:'木石前盟', '金玉良缘', '共读西厢', '宝钗扑蝶','黛玉葬花','晴雯撕扇', '湘云醉眠芍药裀', '香菱学诗'等等。
'元宵丢英莲', '木石前盟', '金玉良缘', '麒麟伏双星', '神游太虚幻境', '秦可卿淫丧天香楼',
'倪二轻财尚义', '智能偷情', '旺儿妇霸成亲',
'大闹学堂', '宝玉挨打', '元妃省亲', '共读西厢', '宝钗扑蝶', '海棠诗社', '湘云醉眠芍药裀', '香菱学诗',
'魇魔姊弟', '金钏投井', '紫鹃试玉', '大闹厨房', '司棋被捉',
'晴雯撕扇', '晴雯补裘', '撵晴雯',
'平儿失镯', '凤姐托孤', '拐卖巧姐',
'探春理家', '探春远嫁', '黛玉葬花', '黛玉之死',
'纳鸳鸯', '偷娶尤二姐', '尤三姐殉情',
'贾政借钱', '勇救薛蟠', '勾引薛蝌',}
其中,'宝钗扑蝶'和'黛玉葬花'均对应第二十七回 滴翠亭杨妃戏彩蝶 埋香冢飞燕泣残红。可见还是可以转换成从章节名里提取事件的。


以上就是对数据集中事件这一维度的分析,借助章回名和耳熟能详的桥段,可以拿到大多数事件。而有了事件后,如何提取事件中涉及的主要人物,这又是需要解决的,并且如何对其他不含章回名的、不那么熟悉的文本进行实体关系抽取、事件图谱构建等等都是需要进一步研究的。
location 地点
接下来,看看location地点数据。格式如下:
{
"label": "太虚幻境",
"value": 1,
"id": 3860,
"categories": [
"location"
],
"info": "太虚幻境,《红楼梦》中的女儿仙境,警幻仙子司主。它位于离恨天之上、灌愁海之中的放春山遣香洞,以梦境的形式向甄士隐、贾宝玉二位有缘人显现。"
},
代码很简单,和上面event事件差不多:
loc_nodes = []
for num, node in enumerate(nodes):
if node['categories'][0] == 'location':
loc_nodes.append(node)
print(len(loc_nodes))
loc_df = pd.DataFrame(loc_nodes)
loc_df.head(10)


本数据集给出的地点不算多,仅26条,主要是城市、贾府、大观园、各主要人物的住处等等。这部分可以用命名实体识别、或手动创建地点词典、或网上找现成的汇总等,应该能比较方便的实现,所以不展开了。至于人物与地点关系的抽取,同样不清楚有什么自动化的方式可以实现嘛?
['荣国府', '宁国府', '大观园', '太虚幻境',
'苏州', '京郊', '扬州', '金陵', '京城', '胡州', '大同府', '阊门', '应天府',
'怡红院', '潇湘馆', '蘅芜苑', '秋爽斋', '暖香坞', '缀锦楼', '稻香村', '凤藻宫', '栊翠庵', '梨香院',
'玄真观', '葫芦庙', '南海']
看到这些熟悉地名,也是想起自己曾去过北京和上海青浦南北两处大观园,网上盗张图,怀念一下:


person 人物
再来看看person人物数据详情。格式如下:
{
"label": "林黛玉",
"value": 21,
"image": "./images/photo/林黛玉.jpg",
"id": 4037,
"categories": [
"person"
],
"info": "金陵十二钗之冠(与宝钗并列)。林如海与贾敏之女,宝玉的姑表妹,寄居荣国府 。她生性孤傲,多愁善感,才思敏捷。她与宝玉真心相爱,是宝玉反抗封建礼教的同盟,是自由恋爱的坚定追求者。"
},
转成表格格式:
person_nodes = []
for num, node in enumerate(nodes):
if node['categories'][0] == 'person':
person = node['label']
person_nodes.append(node)
print(len(person_nodes))
person_df = pd.DataFrame(person_nodes)
person_df.head(10)
共242条人物数据,其中有112人附带了1987版《红楼梦》电视剧的角色剧照,照片统一存放在:dist\examples\images\photo。


陈晓旭版的林黛玉了解一下:


用百年百图の中国(1900-1999):另类python爬虫和PIL拼图一文里的代码将所有图片拼到一起看看。里面混入了一个奇怪的东西(黑白的那张)。
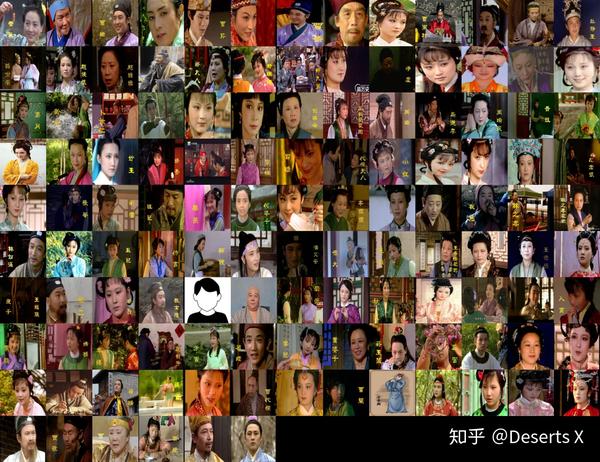

另外,尤三姐的照片搞错成了尤二姐,于是有两张尤二姐的,即第四行倒数第三四张(一位“红迷”的自我修养,后面还发现了其他BUG,稍后再谈)。
edges 边
最后再来看看人物与人物、人物与地点、人物与事件的关系。数据格式:
"edges": [{
"id": 3776,
"label": "位于",
"from": 3838,
"to": 3851
},
{
"id": 3777,
"label": "位于",
"from": 3839,
"to": 3851
},
转成表格形式:
edges_df = pd.DataFrame(edges)
edges_df.head()
共25类694条数据。
['参与', '仆人', '居住地', '父亲', '原籍',
'母亲', '丈夫', '妻子', '哥哥', '交好',
'位于', '同宗', '姐姐', '私通', '老师',
'姬妾', '喜欢', '跟班', '干娘', '奶妈',
'知己', '陪房', '前世', '连宗', '有恩']
用pyecharts绘制各类关系及其数量的柱形图。
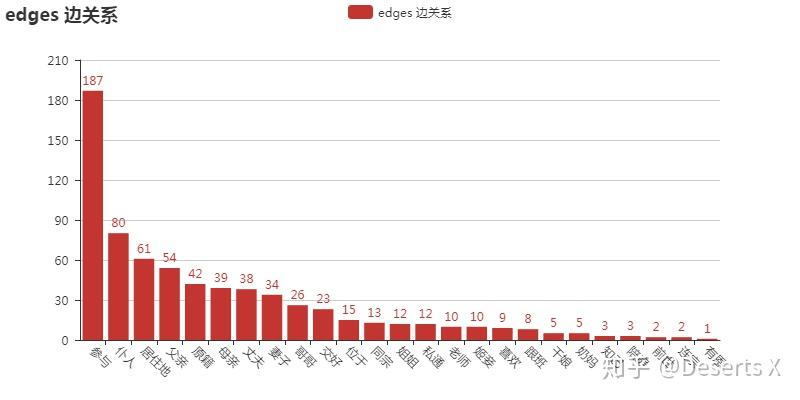

最近python交友娱乐会所群(QQ:613176398)里看到很多人都也在用这个库,不过我又想重新用ECharts来“美颜”图表了,以往整理过的代码和示例可见:图表太丑怎么破,ECharts神器带你飞!。这里也用一下,颜值碾压。
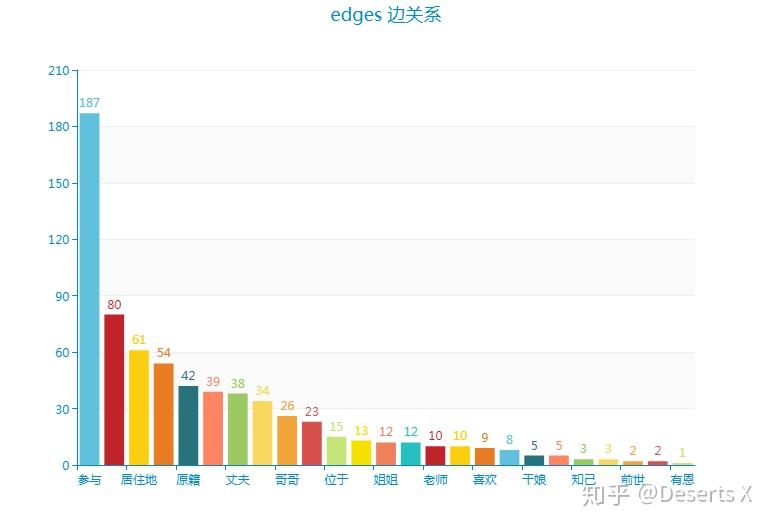

在这些关系中,首先看到了“私通”二字,那么就来看下都是谁和谁私通吧。写成函数方便复用。这里edges只包含相关节点的id,需要从person里拿到对应的人物名称。
def word2id(word):
df = edges_df[edges_df.label== word]
from_id = df['from'].values.tolist()
to_id = df['to'].values.tolist()
return from_id, to_id
def id2label(ids):
tables = []
for ID in ids:
tables.append(person_df[person_df['id']==ID])
labels = pd.concat(tables)['label'].values.tolist()
return labels
def get_relation(from_id,to_id):
for from_label, to_label in zip(id2label(from_id), id2label(to_id)):
print(from_label, '--> {} -->'.format(word), to_label)
word = "私通"
from_id,to_id = word2id(word)
get_relation(from_id,to_id)
以下就是私通名单!《红楼梦》里蛮出名的一句话是焦大说的:“爬灰的爬灰,养小叔子的养小叔子”,不明真相的吃瓜群众可以自行搜索。
贾蔷 --> 私通 --> 龄官
贾珍 --> 私通 --> 秦可卿
贾琏 --> 私通 --> 多姑娘
薛蟠 --> 私通 --> 宝蟾
王熙凤 --> 私通 --> 贾蓉
秦可卿 --> 私通 --> 贾蔷
司棋 --> 私通 --> 潘又安
宝蟾 --> 私通 --> 薛蟠
尤三姐 --> 私通 --> 贾珍
鲍二家的 --> 私通 --> 贾琏
智能儿 --> 私通 --> 秦钟
万儿 --> 私通 --> 茗烟
其中,贾琏也就是王熙凤凤姐的丈夫,分别和多姑娘、鲍二家的有私情。这里不得不开个车,其实《红楼梦》里也有几个黄段子的,下面两则均出自第二十一回 《贤袭人娇嗔箴宝玉 俏平儿软语救贾琏》:
贾琏见她娇俏动情,便搂着求欢,被平儿夺手跑了,急的贾琏弯着腰恨道:“死促狭小滢妇!一定浪上人的火来,他又跑了。”平儿在窗外笑道:“我浪我的,谁叫你动火了?难道图你受用一回,叫他知道了,又不待见我。”
下面这个更好笑,因为新版红楼梦电视剧把这部分拍成了拔火罐,也是佩服导演的“神来之笔”,为18岁以下青少年的心理健康出了一份力。可见:为什么网上对于旧版《红楼梦》的评价比新版《红楼梦》好那么多,旧版红楼是否被过度神话?
那个贾琏,只离了凤姐便要寻事,独寝了两夜,便十分难熬,便暂将小厮们内有清俊的选来出火。


言归正传,本以为这里出现了个BUG:秦可卿 --> 私通 --> 贾蔷 应该是秦可卿 --> 私通 --> 贾珍,但一搜真有这些猜想,也就随它去吧。
另外在原著里秦可卿,乳名兼美,暗含兼有钗黛之美的意思,在宝玉梦游太虚幻境时,写到“其鲜艳妩媚,有似乎宝钗,风流袅娜,则又如黛玉”。也是金陵十二钗中最先去世的女子。

再来看看其他关系:“喜欢”
林黛玉 --> 喜欢 --> 贾宝玉
薛宝钗 --> 喜欢 --> 贾宝玉
妙玉 --> 喜欢 --> 贾宝玉
秦可卿 --> 喜欢 --> 贾宝玉
彩云 --> 喜欢 --> 贾环
尤三姐 --> 喜欢 --> 柳湘莲
藕官 --> 喜欢 --> 菂官
彩霞 --> 喜欢 --> 贾环
龄官 --> 喜欢 --> 贾蔷
“知己”
林黛玉 --> 知己 --> 紫鹃
妙玉 --> 知己 --> 邢岫烟
史湘云 --> 知己 --> 林黛玉
“交好”
贾宝玉 --> 交好 --> 秦钟
贾宝玉 --> 交好 --> 柳湘莲
贾宝玉 --> 交好 --> 蒋玉菡
贾宝玉 --> 交好 --> 北静王
贾蓉 --> 交好 --> 贾琏
贾蔷 --> 交好 --> 秦钟
秦钟 --> 交好 --> 香怜
薛蟠 --> 交好 --> 柳湘莲
薛蟠 --> 交好 --> 冯紫英
薛蟠 --> 交好 --> 金荣
柳湘莲 --> 交好 --> 秦钟
贾雨村 --> 交好 --> 冷子兴
蒋玉菡 --> 交好 --> 北静王
贾芸 --> 交好 --> 贾蔷
贾菌 --> 交好 --> 贾蓝
赖尚荣 --> 交好 --> 柳湘莲
癞头和尚 --> 交好 --> 跛足道人
晴雯 --> 交好 --> 麝月
袭人 --> 交好 --> 平儿
小红 --> 交好 --> 坠儿
瑞珠 --> 交好 --> 宝珠
柳嫂子 --> 交好 --> 芳官
马道婆 --> 交好 --> 赵姨娘
感觉挺多和自己想的不一样的。但也懒得管了。逃……


小结
以上算是“简单”完成了对该数据集的探索和分析,代码开源在:GitHub - DesertsX/gulius-projects,其实到底该如何在新的文本上构造可用的、靠谱的数据集依旧不得而知,后续会写写句法依存分析、信息抽取、事件图谱等等的文章,敬请期待。(马卡龙伏笔)




