
理解零知识证明和协议

原始notebook地址,方便参考
零知识证明是非常容易引发误解的一个概念,不过最近因为互联网的飞速发展造成这种以前只存在学术界的概念逐渐引起人们的重视,所以我在这里写一篇东西简单介绍一下什么是零知识证明和一组简单的示例交互协议。在介绍零知识证明之前首先看一下传统机制存在的一些问题,这样两者对比起来能更好理解零知识系统的好处。
零知识证明最早是在1985由Shafi Goldwasser, Silvio Micali, and Charles Rackoff三人在一篇名为《The Knowledge Complexity of Interactive Proof-Systems》的论文中提出,最初此类研究基本上只在学术界进行,当时人们把主要精力都放在块加密、流加密和公钥体系的密码学研究上。但是因为最近随着互联网尤其是移动互联网的发展,互联网已经成为人们生活中和企业运营中不可缺少的基础设施,因此大量涉及隐私性的信息在联网设备上存储、交换和计算,不可避免的造成大量的隐私信息泄露和互联网诈骗盛行。传统的商业场景中如酒店、机票车票、网上购物等,都会将大量的涉及用户私人信息的数据存储在服务器中。本来如果这些信息仅仅是关联手机号,电子邮箱之类注册账号,其实敏感程度还不算很高。但是最近因为反恐法案的要求,各酒店、公共交通和网络平台都要求实名制,这样数据泄露之后和已有的数据进行关联会造成攻击者手中掌握的数据准确性和即时性大大提高。同时数据在非常不同的企业、机构等节点存储,每一处弱点都会造成大量的信息泄露,整体攻击截面非常巨大。可以在理论上这么认为,凡是今天存储的数据必然都会在未来泄露,这里面只是一个时间的问题。技术上能做的只是在这个数据泄露上增加一个难度,让其泄露时缺乏即时性和完整性,降低其利用价值。减小价值本身也能减少攻击的动机,毕竟攻击者也要消耗一定的资源并求取一定的利益。个人认为设计良好的零知识协议是一个非常有前景的方案,从理论上能保证数据是分布在一组节点集合中而且除非攻破这组集合的全部节点,只攻破一个子集只能让攻击者手中拿到一堆信息量为零或是信息量不多的随机数据,这样会极大降低攻击截面。
零知识证明系统
零知识证明系统一般由两方可以相互交互的对手组成,其中证明者为Peggy(prover),验证者为Victor(verifier)。证明者拥有一个私有信息S,他的目地是向验证者证明他确实拥有私有信息S同时又不泄露任何关于私有信息的具体内容,而验证者要想办法验证证明者确实拥有私人信息S而不能让任何没有私有信息S的对手欺骗他而使他误认为对手拥有私有信息S。显然这个私有信息S包含的信息量不为零,也就是说这个私有信息能外在表现出一些性质,证明者和验证者都要依赖这些私有信息的性质来完成交互验证过程,一个随机生成的字符串包含信息量为零,是没有办法构造一些零知识验证系统的。
从上面的分析可能得出一个正常工作的零知识系统必须包含三个方特性:
- 完备性 如果证明者确实拥有这个私有信息S,他一定可以说服验证者相信他拥有私有信息S
- 可靠性 如果证明者没有这个私有信息S,他没有办法通过欺诈的手段让验证者相信他拥有私有信息S
- 零知识性 当协议完成后验证者验证了证明者手中有私有信息S且验证者只能知道证明者确实拥有了私有信息S,验证者得不到关于私有信息S的其它信息。也就是说无论验证者怎么调整自己的验证步骤并把交互步骤和结果记录下来,他都没有办法向第三方证明他知道私信息的任何知识(其中包括原证明者拥有私有信息S这一事实本身,他都没有办法向第三方证明性的传递
示例1:阿里巴巴山洞问题
这个问题是说有阿里巴巴山洞内部存在一个环形的路线,但是在路线中间存在一个门将路线封住,这个门需要一个咒语才能打开并通过。Peggy要向Victor证明他知道这个咒语但是前提是不泄露咒语的内容。现在一个可行的交互过程是这样的:
- 首先Peggy从入口进入山洞并随机选择一边
- Victor进入山洞,自己随机选择一边让Peggy出现在这边
- Peggy根据Victor的选择出现在山洞一边(如果Victor和Peggy的选边相同,Peggy直接走出来。如果Victor和Peggy的选边不同,Peggy通过咒语开门从另一边出来)
Peggy随机选择一边进入山洞


Victor随机选择山洞一边


Peggy从Victor选择的一边出现
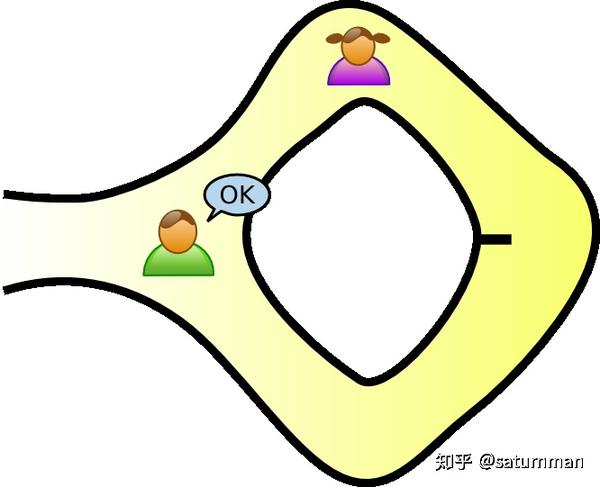

通过一次交互过程Victor可能碰巧肯Peggy选边相同,Peggy存在不知道咒语也能完成Victor的挑战的可能,但是这种可能性只有1/2。因此可以继续这个交互过程很多次,经过n次这样的交互过程,如果Peggy总是能完全Victor的挑战,那么Peggy确实知道咒语的可能性是 1-(1/2)^n ,如果进行的次数足够多,那么Victor可以确信Peggy是知道咒语的。
示例2:基站频率选择问题
假设电信运营商有一组基站,如下图所示:


简化后蜂窝网络的特点是对于两个不在干扰范围内的基站可以随意选择通讯频率,对于处在干扰范围内的基站要选择不同的频率进行通讯。上图上的圈代表不同编号的蜂窝基站,连线代表不同的基站处在干扰范围。现在假设我们只有三个频率可以使用,那么给不同的基站选择不同的频率就成了一个问题。可以选择不同的颜色代表不同的频率,上图一个可行的选择如下:


这个问题抽象出来就是图论中的顶点三着色问题,对于非常复杂图这个问题属于NP完全问题,一个启发式的算法需要的计算量都是非常惊人的,比如电信运营商本身没有足够的计算资源运行算法求解这样的问题,因此他们求助于谷歌这样的互联网公司来利用他们强大的计算资源运行算法求解这个问题。现在的问题是谷歌宣称找到了这个问题的一组解,而电信运营商不知道谷歌是不是真的找到了一组解,他们要求谷歌先出示解方案再付费,而谷歌则强调先付费再给出解方案。现在设计一个零知识交互验证过程在不透露解方案的情况下向运营商证明确实找到了解。
首先设计的交互过程如下(这是一个连计算机都不用的方法):
* 首先找一个大的屋子,在地上铺上纸并绘制上相应的基站和编号
* 谷歌的员工进入屋子并给基站涂色(三中颜色是对称的,他们随机选择一种涂法),并用一样的帽子把所有绘制的基站全部覆盖住
* 运营商的人进入屋子并向谷歌的员工提出一个挑战,他随机选择一对连接的基站
* 谷歌的员工揭开选择的基站上面的帽子,让运营商检查涂色
* 谷歌的员工重新随机选择颜色顺序,再给方案涂色,等待下一次挑战
这个过程反复进行下去,如果谷歌不知道解方案,那么他们不可能每次都能经受住运营商员工的考验,毕竟如果他们没有正确的方案,必然存在者两个连接的顶点选择的颜色是相同的,在非常多的挑战下这个缺陷必然会被发现。只要谷歌的员工经经受住非常多次的挑战之后,运营商就有理由确信他们确实找到了一个解方案。
在实际系统中肯定要需要非常多次的交互,这种验证方式明显效率太差需要在计算机中建立交互验证机制,这里就要利用到不可逆的HASH函数,这里简单描述这种方法。假设谷歌的算法为P,运营商的算法为V。
* 首先谷歌随机给每个基站临时生成一个字符串名字并将有连接的基站之间的四元组(名字A,名字B,A的涂色,B的涂色)生成一个HASH值,这样就生成了一个和变数相同的表
* 将这个表传送给运营商的V
* V随机选择一对连接的基站a,b
* P给出这个四元组(a,b,Color(a),Color(b))
* V验证 Color(a) \neq Color(b) 并且这个四元组HASH值与先前表中一致,本次验证通过
* P重新随机生成每个基站的临时名字,并且把颜色随机洗牌,等待下一轮V的挑战
在经过足够多轮交互之后,解方案的持有性得到验证
示例3:离散对数私钥
假设Peggy持有某给定群G上生成元为g值y=g^x 的离散对数x,在不泄露关于离散对数x的信息的情况下Peggy需要向Victor证明他确实持有此离散对数x。我们假设此群为针对某大素数p的的模运算乘法群。
* 首先Peggy随机生成一个数r并计算它的指数,C=g^r 并将其公布给Victor
* Victor随机让Peggy公布值r,或是值t=(x+r) mod (p-1)
* 当选择让Peggy公布值r时,Victor验证C=g^r ,当选择公布 t=(x+r) mod (p-1)时,Victor验证 (C \ast y) mod p = g^t mod p
如果Peggy没有私钥x,那么他将无法每次都过Victor的挑战,而Victor每次得到的都是随机量,其中不包含关于私钥x的有效信息。
零知识证明和协议的特点
零知识关于私有信息持有性的证明和协议有如下特点:
- 首先Peggy需要传递一个不可抵赖的某信息,这个信息本身对私有信息蕴含的信息量为零,所以这个信息通常是在所有的信息可选集中随机选择一个。
- Victor知道一个不可抵赖的信息已经传送完成(Victor并不一定知道这个信息的内容是什么,他可能只知道信息已经完成,比如Peggy已经进入山洞,已经布置好基站的涂色等)
- Victor在设计好的挑战集合中随机选择一个挑战,等待Peggy的反馈
- Victor验证Peggy的反馈,并根据反馈选择是否进入下一轮挑战
反复经过足够多次挑战Peggy都能应付,那么认为Peggy持有私有信息S
总结
零知识协议可以在不泄露私有信息的前提下只对一方验证对私有信息的持有性,并且理论上证明零知识协议可以在多项式时间内验证所在的NP完全问题的解的持有性,其实这就从理论让证明了零知识验证协议的适用问题范围可以非常广泛。个人觉得为了从技术上做到禁止私人信息泄露又能做到实名制验证与反恐需要,可以设计零知识验证协议,基本的协议框架如下:
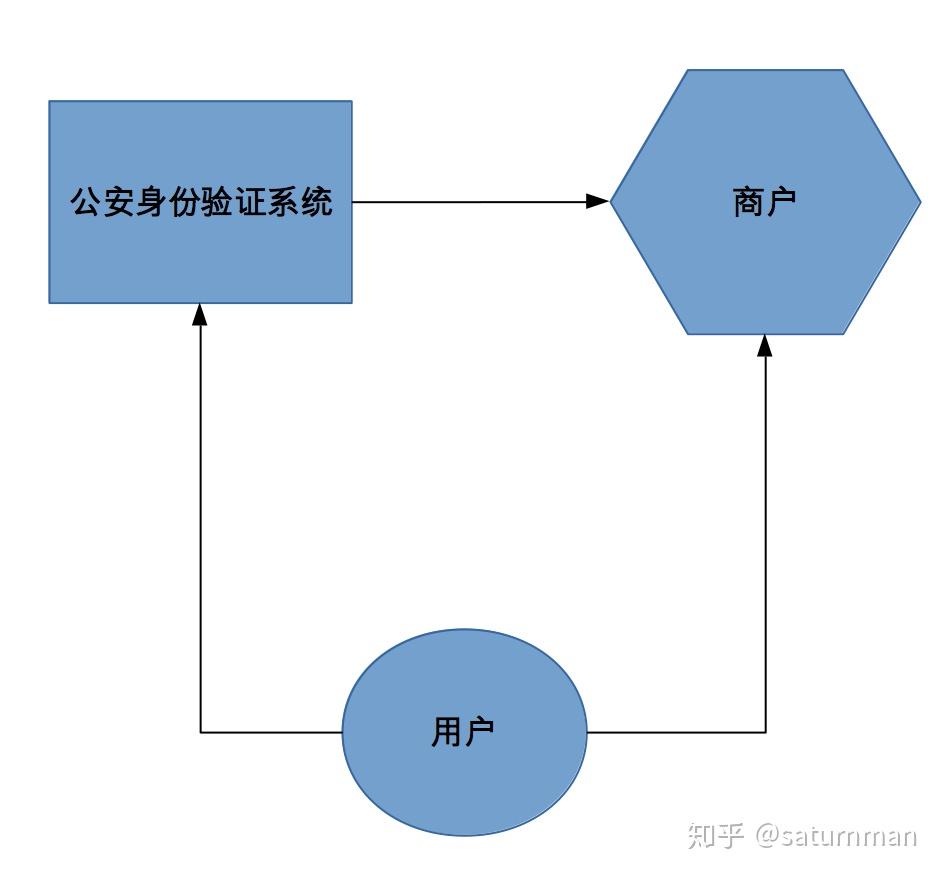

首先商户正常使用自身的会员订单系统,这些系统本身可能不包含与身份信息的绑定信息。当用户出示身份证件时,商户的系统根据证件信息向公安的身份验证平台申请到一个随机生成的临时公钥和私钥,对这个私钥的持有性就表明商户按照规定完成了实名验证,商户根据这个私钥签名服务信息将指纹传送回公安系统与公钥信息一同存储。如此设计商户那里将不再存储实名信息,仅仅保存订单服务相关信息,而公安系统可以验证商户没有篡改服务信息,也可以根据商户那里的信息匹配到实名用户的真实信息。只有当公安的系统和商户的系统同时攻破才可能根据配对信息匹配出实名信息与服务信息的对照表,这其实极大降低了大量数据泄露的风险并降低了数据价值,降低泄露数据后带来的安全隐患。这里当然仅仅是一个举例,实用的协议建立是需要多方验证在实用性和安全性方面取一个平衡,不过从特性上考虑零知识系统在未来有巨大的应用前景。
参考资料:
[1]Zero Knowledge Proofs: An illustrated primer(https://blog.cryptographyengineering.com/2014/11/27/zero-knowledge-proofs-illustrated-primer/)
[2]Zero-knowledge proof(https://en.wikipedia.org/wiki/Zero-knowledge_proof)
