【模型解读】resnet中的残差连接,你确定真的看懂了?

这是深度学习模型解读第6篇,本篇我们将介绍深度学习模型中的残差连接。
1 残差连接
想必做深度学习的都知道skip connect,也就是残差连接,那什么是skip connect呢?如下图


上面是来自于resnet【1】的skip block的示意图。我们可以使用一个非线性变化函数来描述一个网络的输入输出,即输入为X,输出为F(x),F通常包括了卷积,激活等操作。
当我们强行将一个输入添加到函数的输出的时候,虽然我们仍然可以用G(x)来描述输入输出的关系,但是这个G(x)却可以明确的拆分为F(x)和X的线性叠加。
这就是skip connect的思想,将输出表述为输入和输入的一个非线性变换的线性叠加,没用新的公式,没有新的理论,只是换了一种新的表达。
它解决了深层网络的训练问题,作者的原论文中达到了上千层。
残差连接是何的首创吗?当然不是,传统的神经网络中早就有这个概念,文【2】中则明确提出了残差的结构,这是来自于LSTM的控制门的思想。
y = H(x,WH)•T(x,WT) + X•(1- T(x,WT))
可以看出,当T(x,WT) = 0,y=x,当T(x,WT) = 1,y= H(x,WH) 。关于LSTM相关的知识,大家可以去其他地方补。
在该文章中,研究者没有使用特殊的初始化方法等,也能够训练上千层的网络。但为什么这篇文章没有resnet火呢?原因自然有很多了,何的文章做了更多的实验论证,简化了上面的式子,得了cvpr best paper,以及何的名气更大等等因素。
总之,为我们所知道的就是下面的式子
y = H(x,WH) + X,此所谓残差连接,skip connection。
2 为什么要skip connect
那为什么要这么做呢?首先大家已经形成了一个通识,在一定程度上,网络越深表达能力越强,性能越好。
不过,好是好了,随着网络深度的增加,带来了许多问题,梯度消散,梯度爆炸;在resnet出来之前大家没想办法去解决吗?当然不是。更好的优化方法,更好的初始化策略,BN层,Relu等各种激活函数,都被用过了,但是仍然不够,改善问题的能力有限,直到残差连接被广泛使用。
大家都知道深度学习依靠误差的链式反向传播来进行参数更新,假如我们有这样一个函数:


其中的f,g,k大家可以自行脑补为卷积,激活,分类器。
cost对f的导数为:
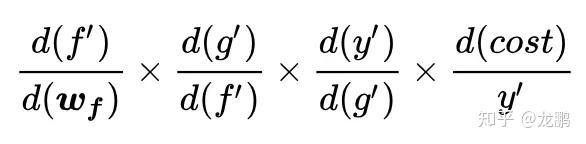

它有隐患,一旦其中某一个导数很小,多次连乘后梯度可能越来越小,这就是常说的梯度消散,对于深层网络,传到浅层几乎就没了。但是如果使用了残差,每一个导数就加上了一个恒等项1,dh/dx=d(f+x)/dx=1+df/dx。此时就算原来的导数df/dx很小,这时候误差仍然能够有效的反向传播,这就是核心思想。
我们举个例子直观理解一下:
假如有一个网络,输入x=1,非残差网络为G,残差网络为H,其中H=F(x)+x
有这样的一个输入输出关系:
在t时刻:
非残差网络G(1)=1.1,
残差网络H(1)=1.1, H(1)=F(1)+1, F(1)=0.1
在t+1时刻:
非残差网络G’(1)=1.2,
残差网络H’(1)=1.2, H’(1)=F’(1)+1, F’(1)=0.2
这时候我们看看:
非残差网络G的梯度 = (1.2-1.1)/1.1
而残差网络F的梯度 = (0.2-0.1)/0.1
因为两者各自是对G的参数和F的参数进行更新,可以看出这一点变化对F的影响远远大于G,说明引入残差后的映射对输出的变化更敏感,输出是什么?不就是反应了与真值的误差吗?
所以,这么一想想,残差就应该是有效的,各方实验结果也证明了。
3 skip connect就只是这样吗
上面我们解释了skip connect改善了反向传播过程中的梯度消散问题,因此可以使得训练深层网络变得容易,但研究者们表示NoNoNo,没这么简单。
文【3】的研究直接表明训练深度神经网络失败的原因并不是梯度消失,而是权重矩阵的退化,所以这是直接从源头上挖了根?
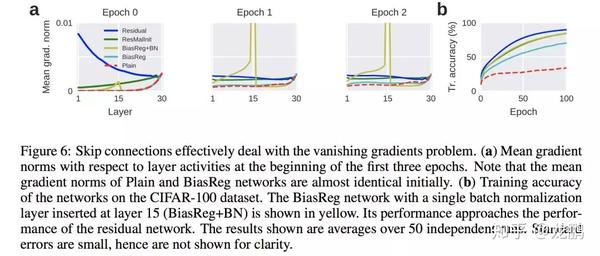
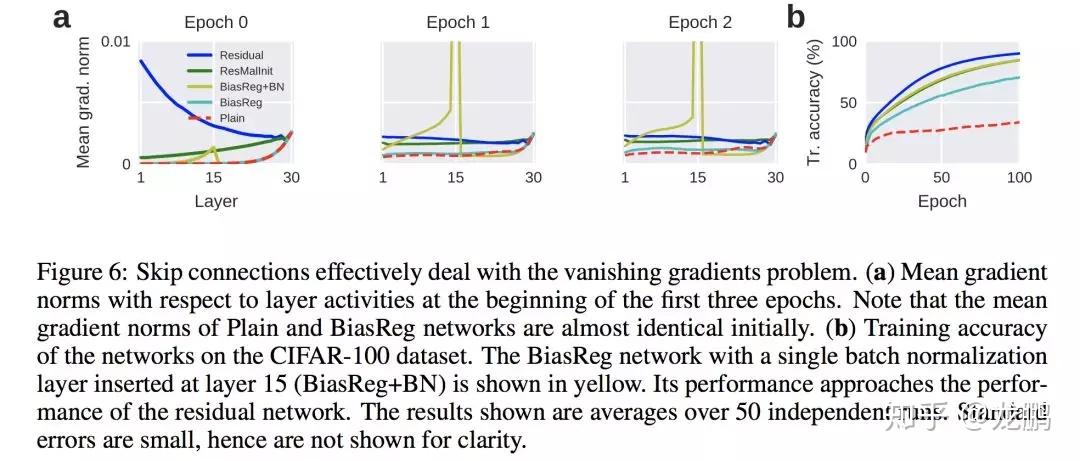
当然,resnet有改善梯度消失的作用,文中也做了实验对比如上:但不仅仅不如此,下图是一个采用残差连接(蓝色曲线)和随机稠密的正交连接矩阵的比对,看得出来残差连接并不有效。
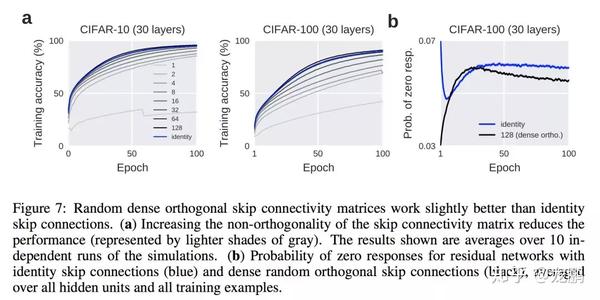

结合上面的实验,作者们认为神经网络的退化才是难以训练深层网络根本原因所在,而不是梯度消散。虽然梯度范数大,但是如果网络的可用自由度对这些范数的贡献非常不均衡,也就是每个层中只有少量的隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同的输入都是相同的反应,此时整个权重矩阵的秩不高。并且随着网络层数的增加,连乘后使得整个秩变的更低。
这也是我们常说的网络退化问题,虽然是一个很高维的矩阵,但是大部分维度却没有信息,表达能力没有看起来那么强大。
残差连接正是强制打破了网络的对称性。
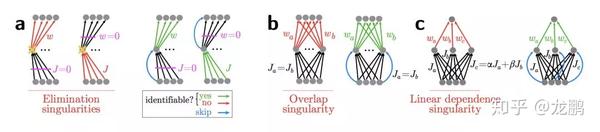

第1种(图a),输入权重矩阵(灰色部分)完全退化为0,则输出W已经失去鉴别能力,此时加上残差连接(蓝色部分),网络又恢复了表达能力。第2种(图b),输入对称的权重矩阵,那输出W一样不具备这两部分的鉴别能力,添加残差连接(蓝色部分)可打破对称性。第3种(图c)是图b的变种,不再说明。
总的来说一句话,打破了网络的对称性,提升了网络的表征能力,关于对称性引发的特征退化问题,大家还可以去参考更多的资料【4】。
对于skip连接的有效性的研究【5-6】,始终并未停止,至于究竟能到什么地步,大家还是多多关注吧学术研究,也可以多关注我们呀!
参考文献
[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[2] Srivastava R K, Greff K, Schmidhuber J. Highway networks[J]. arXiv preprint arXiv:1505.00387, 2015.
[3] Orhan A E, Pitkow X. Skip connections eliminate singularities[J]. arXiv preprint arXiv:1701.09175, 2017.
[4] Shang W, Sohn K, Almeida D, et al. Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units[J]. 2016:2217-2225.
[5] Greff K, Srivastava R K, Schmidhuber J. Highway and Residual Networks learn Unrolled Iterative Estimation[J]. 2017.
[6] Jastrzebski S, Arpit D, Ballas N, et al. Residual connections encourage iterative inference[J]. arXiv preprint arXiv:1710.04773, 2017.
----------------------------更多相关内容,请阅读以下资料----------------------------模型解读系列目录:
【模型解读】从LeNet到VGG,看卷积+池化串联的网络结构
【模型解读】network in network中的1*1卷积,你懂了吗
【模型解读】GoogLeNet中的inception结构,你看懂了吗
阿里天池模型结构设计与优化直播:

有三AI知识星球中网络结构1000变,每日更新





有三AI秋季划模型优化组