
LightGBM原理分析

1. Abstract
在之前我介绍过XGB模型,这次想跟大家分享一下LightGBM这个模型。LightGBM论文的标题为A Highly Efficient Gradient Boosting Decision Tree。这说明LightGBM它是对于XGB提升性能的版本。而LightGBM相对于其他GBM来说具有相近的准确率而且是其训练速度20倍。
2. Comparse with XGB
LightGBM主要的对比对象就是XGB,所以我们先说一下XGB有什么优缺点先。
优点 (详情可以看看我之前的blog)
- XGB利用了二阶梯度来对节点进行划分,相对其他GBM来说,精度更加高。
- 利用局部近似算法对分裂节点的贪心算法优化,取适当的eps时,可以保持算法的性能且提高算法的运算速度。
- 在损失函数中加入了L1/L2项,控制模型的复杂度,提高模型的鲁棒性。
- 提供并行计算能力,主要是在树节点求不同的候选的分裂点的Gain Infomation(分裂后,损失函数的差值)
- Tree Shrinkage,column subsampling等不同的处理细节。
缺点
- 需要pre-sorted,这个会耗掉很多的内存空间(2 * #data * # features)
- 数据分割点上,由于XGB对不同的数据特征使用pre-sorted算法而不同特征其排序顺序是不同的,所以分裂时需要对每个特征单独做依次分割,遍历次数为#data * #features来将数据分裂到左右子节点上。
- 尽管使用了局部近似计算,但是处理粒度还是太细了
- 由于pre-sorted处理数据,在寻找特征分裂点时(level-wise),会产生大量的cache随机访问。
因此LightGBM针对这些缺点进行了相应的改进。
- LightGBM基于histogram算法代替pre-sorted所构建的数据结构,利用histogram后,会有很多有用的tricks。例如histogram做差,提高了cache命中率(主要是因为使用了leaf-wise)。
- 在机器学习当中,我们面对大数据量时候都会使用采样的方式(根据样本权值)来提高训练速度。又或者在训练的时候赋予样本权值来关于于某一类样本(如Adaboost)。LightGBM利用了GOSS来做采样算法。
- 由于histogram算法对稀疏数据的处理时间复杂度没有pre-sorted好。因为histogram并不管特征值是否为0。因此我们采用了EFB来预处理稀疏数据。
下来我们针对这些改进来说明一下。
3. Histogram Algorithm(直方图)
相对于pre-sorted算法,它的内存空间需要相对小很多。因为pre-sorted算法需要保存起来每一个特征的排序结构,所以其需要的内存大小是2 * #data * #feature * 4Bytes(起始我认为保存排序后的数据可以用row_id来代替)而histogram只需保存离散值bin value(EFB会谈到bin)而且我们不需要原始的feature value,所以占用的内存大小为:#data * # feature * 1Byte,因为离散值bin value使用uint8_t已经足够了。另外对于求子节点相应的feature histogram时,我们只需构造一个子节点的feature histogram,另外一个子节点的feature histogram我们用父节点的histogram减去刚构造出来的子节点的histogram便可,时间复杂度就压缩到O(k),k为histogram的桶数。这是一个很巧妙的做差法。
4. Gradient-based One-Side Sampling(GOSS)
其中文为梯度单边采样。大致的意思是根据样本某一特征上的单梯度作为样本的权值进行训练。其采样的方式有点巧妙:
这里感谢网友提醒,我看回了算法流程。发现Alg 2的randN = b * len(I),也就是算法中小梯度的样本数量为b% * #samples。
1. 选取前a%个较大梯度的值作为大梯度值的训练样本
2. 从剩余的1 - a%个较小梯度的值中,我们随机选取其中的b%个作为小梯度值的训练样本
3. 对于较小梯度的样本,也就是b% * #samples,我们在计算信息增益时将其放大(1 - a) / b倍
总的来说就是a% * #samples + b% * #samples个样本作为训练样本。 而这样的构造是为了尽可能保持与总的数据分布一致,并且保证小梯度值的样本得到训练。


5. Exclusive Feature Bundling
EFB中文名叫独立特征合并,顾名思义它就是将若干个特征合并在一起。使用这个算法的原因是因为我们要解决数据稀疏的问题。在很多时候,数据通常都是几千万维的稀疏数据。因此我们对不同维度的数据合并一齐使得一个稀疏矩阵变成一个稠密矩阵。这里就有两个问题:1. 如何确定哪些特征用于融合且效果为较好。2. 如何将这些特征合并到一齐。
1. 对于第一个问题,这是一个NP-hard问题。我们把feature看作是图中的点(V),feature之间的总冲突看作是图中的边(E)。而寻找寻找合并特征且使得合并的bundles个数最小,这是一个图着色问题。所以这个找出合并的特征且使得bundles个数最小的问题需要使用近似的贪心算法来完成。


它将问题一换成图着色算法去解决。构建一个以feature为图中的点(V),以feature之间的总冲突为图中的边(E)这里说的冲突值应该是feature之间cos夹角值,因为我们是尽可能保证feature之间非0元素不在同一个row上。首先按照度来对每个点(feature)做降序排序(度数越大与其他点的冲突越大),然后将特征合并到冲突数小于K的bundle或者新建另外一个bundle。算法的时间复杂度为O(#feature^2)。
2. 第二问题是将这些bundles中的特征合并起来。


由于每一个bundle当中,features的range都是不一样,所以我们需要重新构建合并后bundle feature的range。在第一个for循环当中,我们记录每个feature与之前features累积totalRange。在第二个for循环当中,根据之前的binRanges重新计算出新的bin value(F[j]bin[i] + binRanges[j])保证feature之间的值不会冲突。这是针对于稀疏矩阵进行优化。由于之前Greedy Bundling算法对features进行冲突检查确保bundle内特征冲突尽可能少,所以特征之间的非零元素不会有太多的冲突。
如此一来,数据的shape就变成了#samples * #bundles,且#bundles << #features。EFB降低了数据特征规模提高了模型的训练速度。
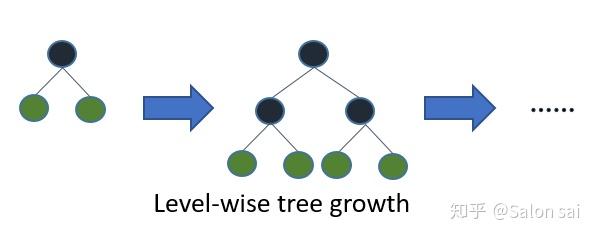
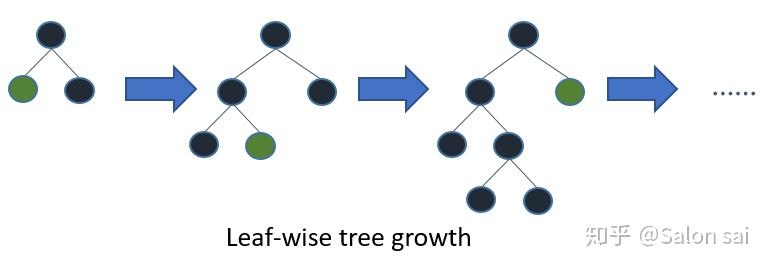
6 Leaf-wise (Best-first) Tree Growth
LightGBM对于树的生长使用的是Leaf-wise,而不是Level-wise。这样的做法主要是因为LightGBM认为Level-wise的做法会产生一些低信息增益的节点,浪费运算资源。其实通常来说,Level-wise对于防止过拟合还是很有作用的,所以大家都比较青睐与它相比与Leaf-wise。作者认为Leaf-wise能够追求更好的精度,让产生更好精度的节点做分裂。但这样带来过拟合的问题,所以作者使用的max_depth来控制它的最大高度。还有原因是因为LightGBM在做数据合并,Histogram Algorithm和GOSS等各个操作,其实都有天然正则化的作用,所以使用Leaf-wise来提高精度是一个很不错的选择。


7. References
- https://www.zhihu.com/question/51644470
- https://zhuanlan.zhihu.com/p/34698733
- https://baike.baidu.com/item/%E5%9B%BE%E7%9D%80%E8%89%B2%E9%97%AE%E9%A2%98
- https://lightgbm.readthedocs.io/en/latest/Features.html
- https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
- https://huangzhanpeng.github.io/2018/01/04/A-Highly-Ef%EF%AC%81cient-Gradient-Boosting-Decision-Tree/
- https://www.msra.cn/zh-cn/news/features/lightgbm-20170105
