
Prompt-based Language Models:模版增强语言模型小结

本文首发于知乎专栏机器学不动了,禁止任何未经本人@Riroaki授权的转载。
4月老文重发,估计不少人已经看过了;
Prompt相关论文可以参考:
最近注意到NLP社区中兴起了一阵基于Prompt(模版)增强模型预测的潮流:
从苏剑林大佬近期的几篇文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》,《P-tuning:自动构建模版,释放语言模型潜能》,到智源社区在3月20日举办的《智源悟道1.0 AI研究成果发布会 暨大规模预训练模型交流论坛》中杨植麟大佬关于“预训练与微调新范式”的报告,都指出了Prompt在少样本学习等场景下对模型效果的巨大提升作用。
本文根据上述资料以及相关论文,尝试梳理一下Prompt这一系列方法的前世今生。


本文目录:
- 追本溯源:从GPT、MLM到Pattern-Exploiting Training
- Pattern-Exploiting Training
- 解放双手:自动构建Prompt
- LM Prompt And Query Archive
- AUTOPROMPT
- Better Few-shot Fine-tuning of Language Models
- 异想天开:构建连续Prompt
- P-tuning
- 小结
1 追本溯源:从GPT、MLM到Pattern-Exploiting Training
要说明Prompt是什么,一切还要从OpenAI推出的GPT模型说起。
GPT是一系列生成模型,在2020年5月推出了第三代即GPT-3。具有1750亿参数的它,可以不经微调(当然,几乎没有人可以轻易训练它)而生成各式各样的文本,从常规任务(如对话、摘要)到一些稀奇古怪的场景(生成UI、SQL代码?)等等。
在这里,我们关注到GPT模型在零样本场景下的运行方式——基于一定的任务描述(task description),按这一描述的指定生成文本:
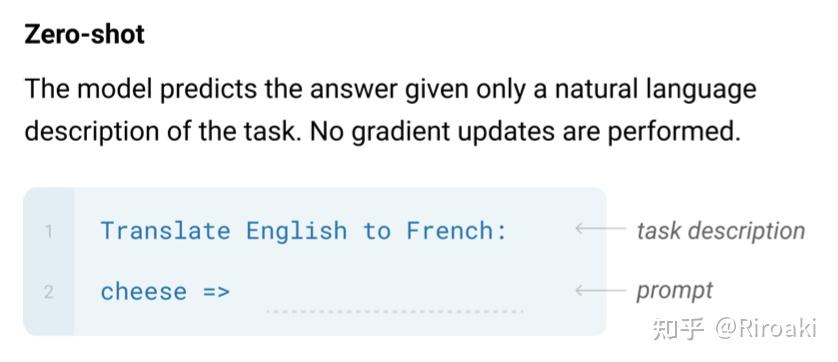

仅仅几个单词组成的任务描述,就可以为语言模型的预测提供指导,这启发了一些少样本领域的工作——在缺少训练数据的场景下,利用任务描述能很好地提升模型的效果。
另一个灵感来自预训练语言模型的Masked Language Model/MLM任务:
在BERT的训练中,有15%的输入词被选中,其中的绝大部分又被替换为[MASK]标签或者随机的其他词,并在最终的hidden states中对被遮盖的词进行预测,通过还原遮盖词让模型学习单词级别的上下文信息。
将这两个灵感融合,就得到了以下将介绍的Pattern-Exploiting Training,或PET方法。
补充:从这里就可以提出一个问题,Mask和Prompt,具体而言是哪一部分对模型预测起了作用?
1.1 Pattern-Exploiting Training
PET来自2020年的论文(已发表在EACL2021)《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》,其中介绍了一种基于模版和词遮盖将文本分类任务转换为完形填空(cloze)任务的半监督训练方法,仅使用RoBERTa-base模型就在多个半监督场景下取得了SOTA:
- 首先,针对少量样本设计描述的模版(pattern),如下图中对“Best pizza ever!”的情感分类任务,生成一个“It was ___”的句子并拼接在原始输入后作为补充;
- 对模版中遮盖的词(即下划线部分),设计候选词对应不同的情感极性(图中great对应positive,bad对应negative),然后将模型预测“great”的概率作为原来预测“positive”的概率,从而将情感分类任务转换为完形填空任务。
- 当然,原文中对NLI任务也进行了模版构建,其操作有所不同,在此不展开;
- 注意,完形填空和MLM不是一个任务,虽然二者都是词分类任务,但是类别一个是候选词集,一个是模型中全部的词集;
- 对有标签样本集设计不同的模版,然后对每一个模版,分别训练模型;
- 因为有标签样本比较少,所以训练成本低于全量数据训练一个完整的模型;
- 这里的训练因为是有监督的,所以结合了完形填空的词分类loss和MLM Loss进行训练: L=(1-\alpha) \cdot L_{\mathrm{CE}}+\alpha \cdot L_{\mathrm{MLM}} ,其中MLM loss占较小比重(1e-4);
- 使用上面训练得到的一堆模型,在无标签数据上进行预测,按不同pattern的模型acc对应权重对所有的预测进行归一化,作为soft label蒸馏一个最终模型;
- 这里最终模型并不进行pattern的学习;
- 在这里的训练中,不涉及MLM loss。
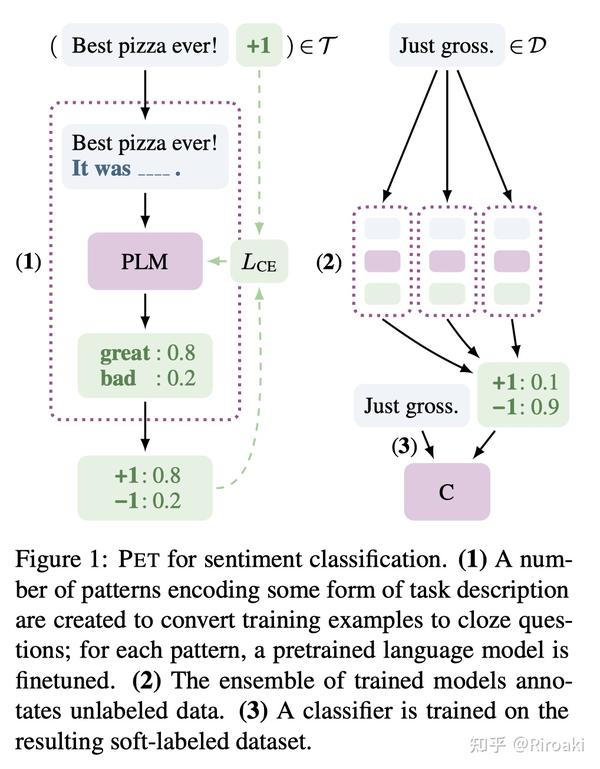

在PET的基础上,为了让不同模版训练出的模型互相学习,文中还提出了一种迭代式的PET训练(Iterative PET,iPET):
- 其实就是进行多代交叉的蒸馏,随机选取每一代的模型为无标签数据进行标记,并基于此进一步训练下一代模型;
- 最终和PET一样,用不同模型标注的无标签数据进行预测,蒸馏一个统一的模型。


说完了训练过程,我们看看这里的模版(pattern):
- 情感分类(Yelp):


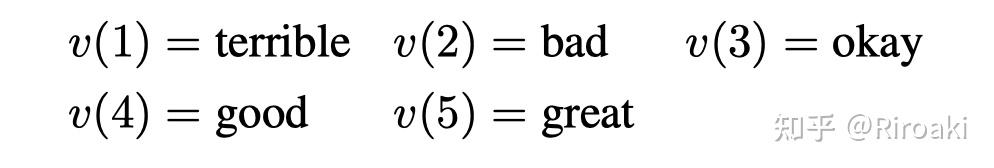

- 文本蕴含(MNLI):


可以看出,人工构建的模版比较简单,语义上也和任务具有较好的关联。
在这一半监督场景工作的基础上,本文作者进一步在NAACL2021上发表了《It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》,通过将“小模型”(ALBERT)和GPT-3这一巨无霸在SuperGLUE benchmark上进行对比,进一步挖掘PET训练在少样本场景下的潜力。
由于使用的基本是同一个方法(补充了实际训练中multi-token的mask预测),所以不再重复,在此贴出论文的实验结果:
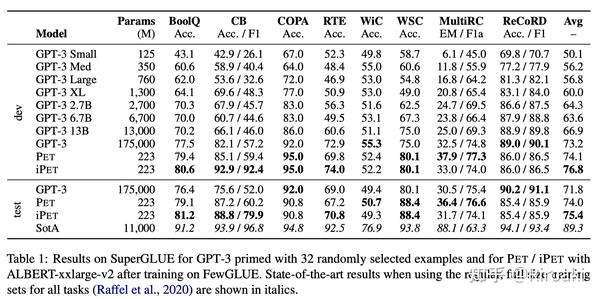

除了这一个震撼的结果以外,苏神的文章中也有一些中文的少样本实验(包括零样本、小样本、半监督等场景)证明了MLM预测在中文情感分析中的作用,参考:
2 解放双手:自动构建Prompt
有了PET,人们显然是不满足的——类比机器学习的不同时期的话,人工构建pattern/prompt就像在进行手工的特征工程,对输入特征进行人工的选择和组合,所谓“有多少人工,就有多少智能”,需要不断尝试和调整才能取得一个比较好的模版。
而依赖特征工程的方法,如今很大程度上被深度学习为主的自动选择特征的方法取代了——换言之,取代手工选取模版的方法自然会被自动选取特征的方法取代。


2.1 LM Prompt And Query Archive
最早提出自动构建模版的工作应该是发表在TACL2020的《How Can We Know What Language Models Know?》,其中提出了一个LPAQA(LM Prompt And Query Archive)方法以进行模版的自动搜索。
不过,这篇文章并不应用在前述的少样本场景,而是针对一个检测语言模型是否具有某些知识的探针任务(Language Models as Knowledge,LAMA Probe)——而这一任务的形式也是完形填空。
LPAQA旨在改进LAMA的模版(换言之,让语言模型在这些新的queries上具有更好的预测表现),以为检测LM中的知识提供一个更严格的下界:
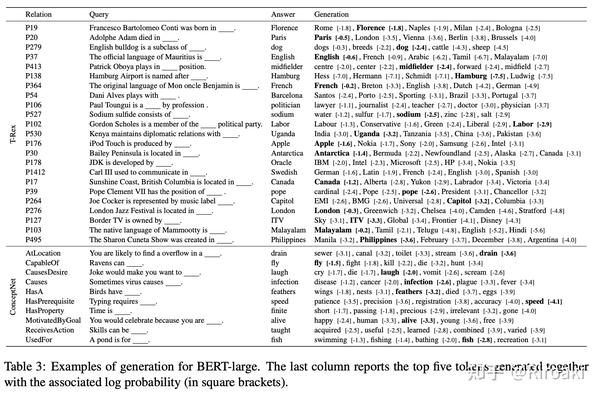

可以看到,LAMA数据集中包含的句子用于描述两个实体之间的关系,而其中一个实体被遮盖,需要语言模型来预测,如果预测正确则说明模型学会了这一关系。然而,很多时候其实从这些query中是看不出这种关系的,或者说,即便模型没有回答正确,也不能说明模型不懂这个关系(比如存在一对多的情形,或者模型未见过的实体等……)。
具体而言,LPAQA包含两部分生成方法:
- Mining-based Generation:基于远程监督的假设(即,出现相同实体对的句子表达相同的关系),在Wikipedia sentence中寻找包含头尾实体h、t的句子,然后进一步提出了两种prompt抽取方法:
- Middle-word Prompts:对于h、t中间包含文本的句子形式,将h、t中间的文本当作prompt;
- Dependency-based Prompts:对于其他句子,使用句法依赖解析来提取h和t最短的路径,并将路径上的词作为prompt;
- Paraphrasing-based Generation:类似查询拓展技术,在保持原prompt语义同时增加词汇的多样性。这种方法依赖反向翻译(back-translation),即翻译到另一种语言再翻译回来,构成多个样本后根据往返概率(round-trip probability)筛选prompt。
显然,第一种方法会引入噪音,而第二种也具有不稳定性。
因此,需要进一步筛选高质量的生成语句,为此本文提出了selection和ensemble的方法:
- Top-1 Prompt Selection:就是用LM测一测看看效果,取acc最高的prompt;
- Rank-based Ensemble:除了Top-1方案,有时候需要保持多个模版来增强效果,即选取前K个模版;
- Optimized Ensemble:通过LM的预测为不同的prompt赋权。
这篇文章看起来很复杂,实际上提出了一个比较basic的方案。
简单、可控,没有什么fancy操作,不需要调整什么模型参数(几乎是parameter-free的),实际操作和落地都很有价值,这大概就是LPAQA的优点……
2.2 AUTOPROMPT
这是来自EMNLP2020的文章《AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts》,提出了一种基于梯度的模版搜索方案,如下图:
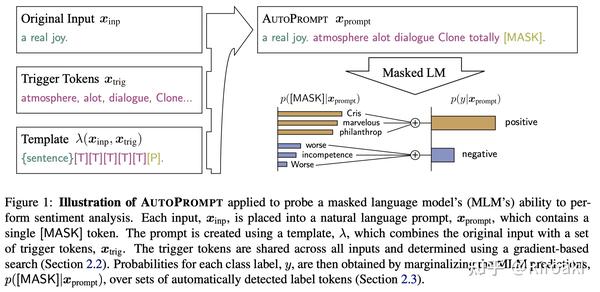

方法很直观,将通过梯度找出的trigger word和mask拼接在文本中,形成一个语义上不通顺、但是对模型而言却具有合理提示的样本,并且将label预测转换为masked token的预测(即完形填空问题)。
方法的核心在于选取trigger word,这一方法基于本文作者之一的Wallace在EMNLP2019发表的对抗攻击文章《Universal Adversarial Triggers for Attacking and Analyzing NLP》:
- 将所有trigger token初始化为mask token;
- 对某个trigger进行替换,找出前k个最大化输入与其梯度乘积的词: \mathcal{V}_{\text {cand }}=\operatorname{top}_{w \in \mathcal{V}} k\left[\boldsymbol{w}_{\text {in }}^{T} \nabla \log p\left(y \mid \boldsymbol{x}_{\text {prompt }}\right)\right] ;
- 对每个候选词,评估其加入prompt后的模型预测概率: p\left(y \mid \boldsymbol{x}_{\text {prompt }}\right)=\sum_{w \in \mathcal{V}_{y}} p\left([\mathrm{MASK}]=w \mid \boldsymbol{x}_{\text {prompt }}\right) ;
- 通过形如 \{sentence\}[T][T][T][T][T][P] 的模版,加入上面选出的词构造prompt。
补充:这里的步骤说的不是很清楚,不过大致应该就是梯度粗筛+代入模版精筛。具体参考:http://ucinlp.github.io/autoprompt 而且这里用5个词的template,估计也是效果试出来的……
此外,这里标签词也是自动化的方式选出来的:
- 将mask token的hidden states过一个线性层,用这一输出对应真实label的预测,进行训练得到线性层的权重;
- 将MLM的输出word embedding过上面这个线性层(这里应该是说,将候选词代替mask token后输出的hidden states)并预测label,这个分数越高说明候选词与label的关联越强,那么就取分数最高的候选词作为label对应的token: \mathcal{V}_{y}=\operatorname{top}_{w \in \mathcal{V}}[s(y, w)] 。
这一工作不但在SST-2和SICK-E(一个NLI数据集,不知道为什么不用MNLI呢?)上进行实验,还在LAMA与LPAQA进行了比较。
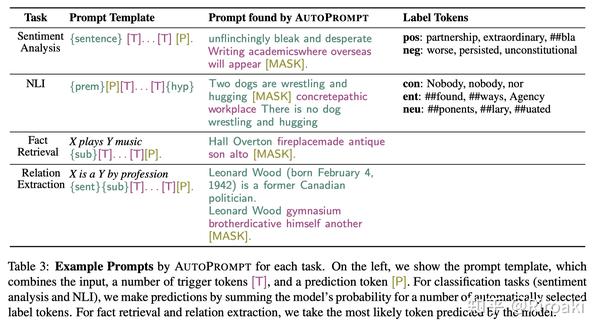
以下是不同任务找出的trigger token和label token:

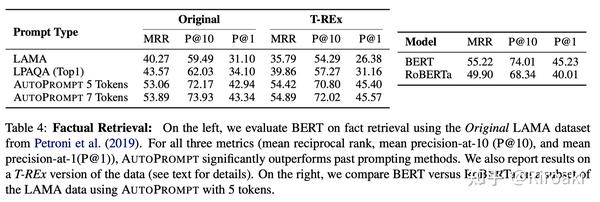
在LAMA数据集上,和LPAQA相比,AUTOPROMPT生成的prompt对LM效果提升更明显:
- 即便每个关系只用一个prompt,也比LPAQA集成了30句prompt的提升效果要好……

实验中发现一些有趣的结论:
- AUTOPROMPT中,更容易用语言表达的label对应的prompt提升比其他label的明显(例如NLI的contradiction > entailment / neutral);
- 在LAMA中,越容易具体说明的关系对应的prompt对模型提升越大,这个和上一点相似;
- 在LAMA中,RoBERTa比BERT表现差,因为它在prompt中加入了一些无关的token,然而这一点依然有待未来工作探究(当然,LAMA仅仅表明了语言模型能力的下界)。
进一步,本文中进行了RE实验,看看AUTOPROMPT在RE任务(T-Rex数据集)上的效果。实验发现LM比常规RE大幅度胜出,在对尾实体进行随机替换实验后依然如此——后一实验用于探究LM是否因为记忆了实体才具有更好的效果。
补充:值得注意的是,这里的实验忽略NA即无关系标签,使用precision作为指标,和常规的F1指标有较大区别;这里的设置我不是很理解(也许单纯为了效果更好)
总体而言,AUTOPROMPT虽然效果不错,但相对而言具有更差的解释性,其搜索方式也比较简单——这一点是否是缺点则见仁见智。
2.3 Better Few-shot Fine-tuning of Language Models
这一工作来自Danqi Chen大佬的小组:《Making Pre-trained Language Models Better Few-shot Learners》,探究少样本场景下Prompt的作用,基于谷歌的T5模型构建了一个自动化的pipeline:
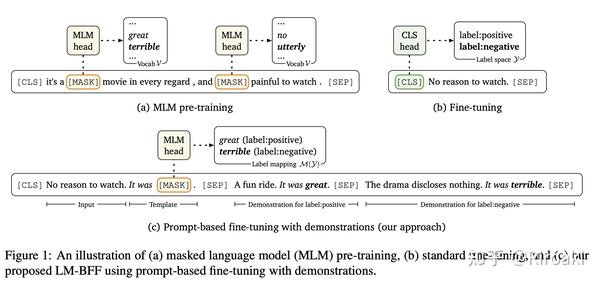
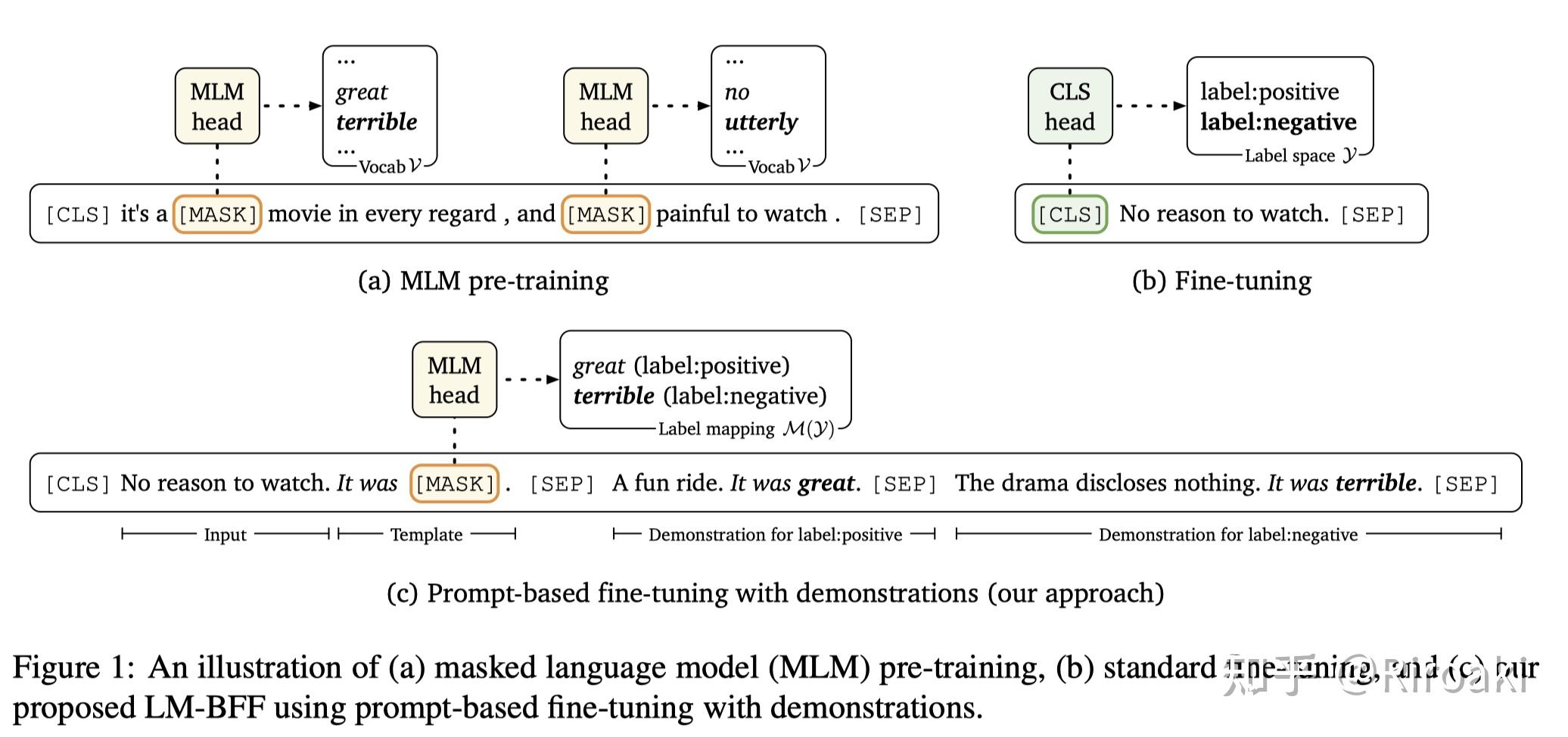
同样注意到PET方法的低效,这一工作提出了一种名为LM-BFF的架构,引入了T5(Text-to-Text Transfer Transformer)生成模型用于自动化生成Prompt,同时也指出LPAQA只能应用在有限场景(表达relation等),而AUTOPROMPT需要大量样本进行基于梯度搜索,总而言之目前的方案都不完美……
补充:LM-BFF也可以是language models’ best friends forever
本文探究的是少样本场景,包括single-sentence tasks和sentence-pair tasks。此前的工作局限于分类,本文还涉及STS-B这一回归任务。
此外还加入了demonstrations(示例)与prompt一并输入以为预测提供指导。这一灵感来自于GPT在少样本场景的工作方式,即将示例样本与任务描述一并输入模型:


具体方案包括标签词的自动搜索、模版的搜索和样本实例的搜索,以下分别介绍:
- 标签词搜索。用预训练模型为每个label找到预测最高的k个词,综合每个类的词进行训练找到效果最好的n个组合(嘿,这里我也没弄明白怎么找的,不会是暴力试一遍吧),再在dev微调找出最佳的一组;
- 模版搜索。用T5进行不指定token数量的生成,这一点比普通的固定数量mask要自然;
- 实例搜索。考虑到GPT-3方案对样本长度的限制和不同样本不好训练,使用Sentence-BERT为输入样本在每一个类别寻找相似的样本作为demonstration。
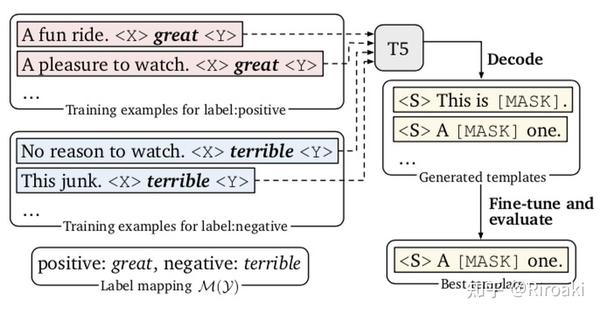
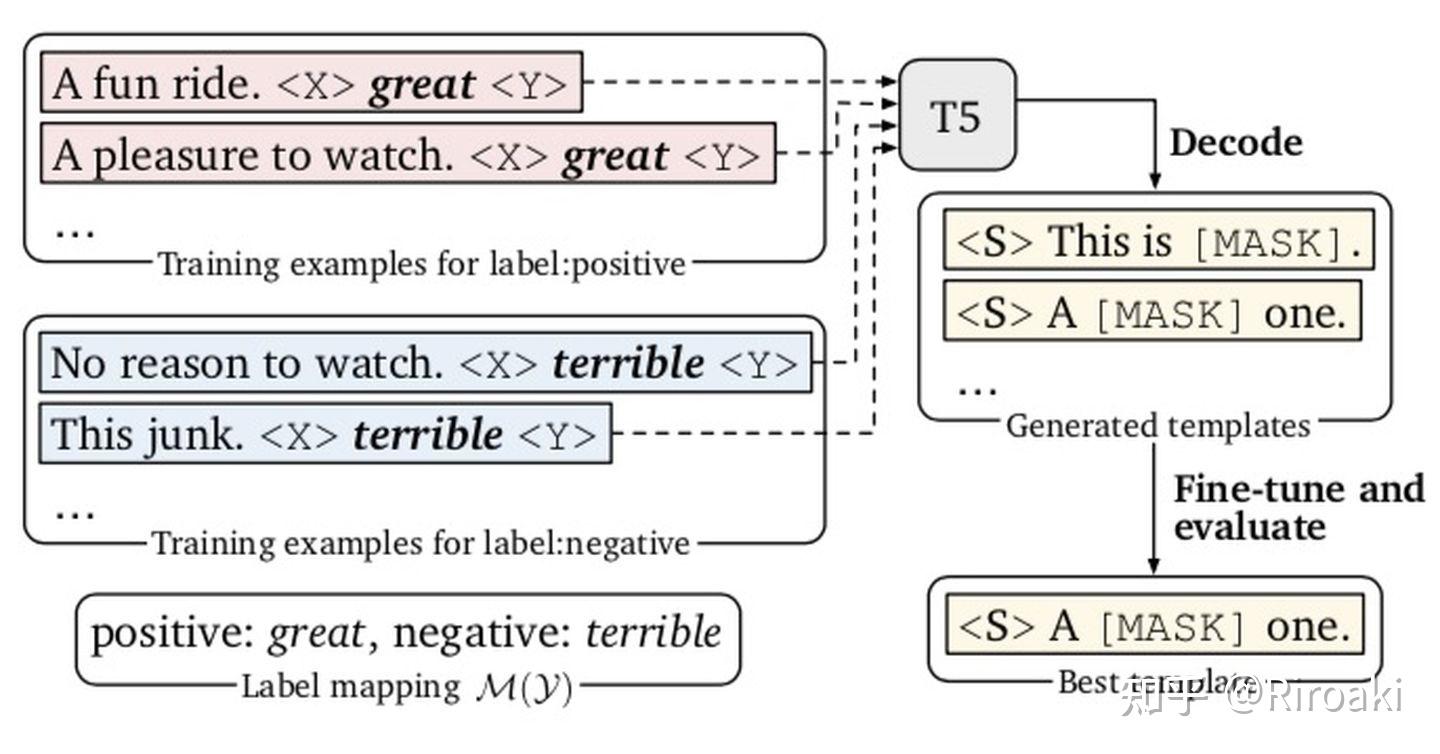
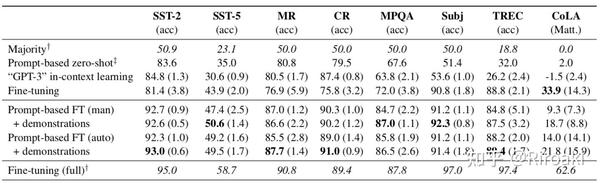
实验结果如下:
- 可以看出prompt FT(auto) + demonstrations > prompt FT(auto) > prompt FT(man) > FT;
- 但是全量数据FT还是比不过(差别不算大?也有超过的,不过CoLA低的不行),这也合情合理。

关于详细解读,可以参考这篇文章:
3 异想天开:构建连续Prompt
看到这idea,我脑海里第一个念头就是:
你的下一句prompt,何必是自然语言?


好吧,这一块是关于唐杰老师的《GPT Understands, Too》,首次提出了用连续空间搜索的embedding做prompt。
这拓展倒是合情合理,毕竟自然语言是给人看的,而模型只会看到一堆向量……
3.1 P-tuning
和之前的工作不太一样,这篇文章用的是GPT这个生成模型而不是BERT这些MLM模型。
同样注意到离散化表达的搜索困难,但是这一工作接着自动搜索还提出了连续空间的搜索。
这一操作可就相当于去掉了镣铐,但是也带来了搜索空间过大的问题(同时,也模糊了prompt原本的含义)。
那么p-tuning是怎么搜索prompt的呢?请看:
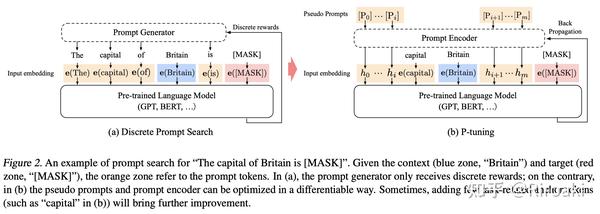
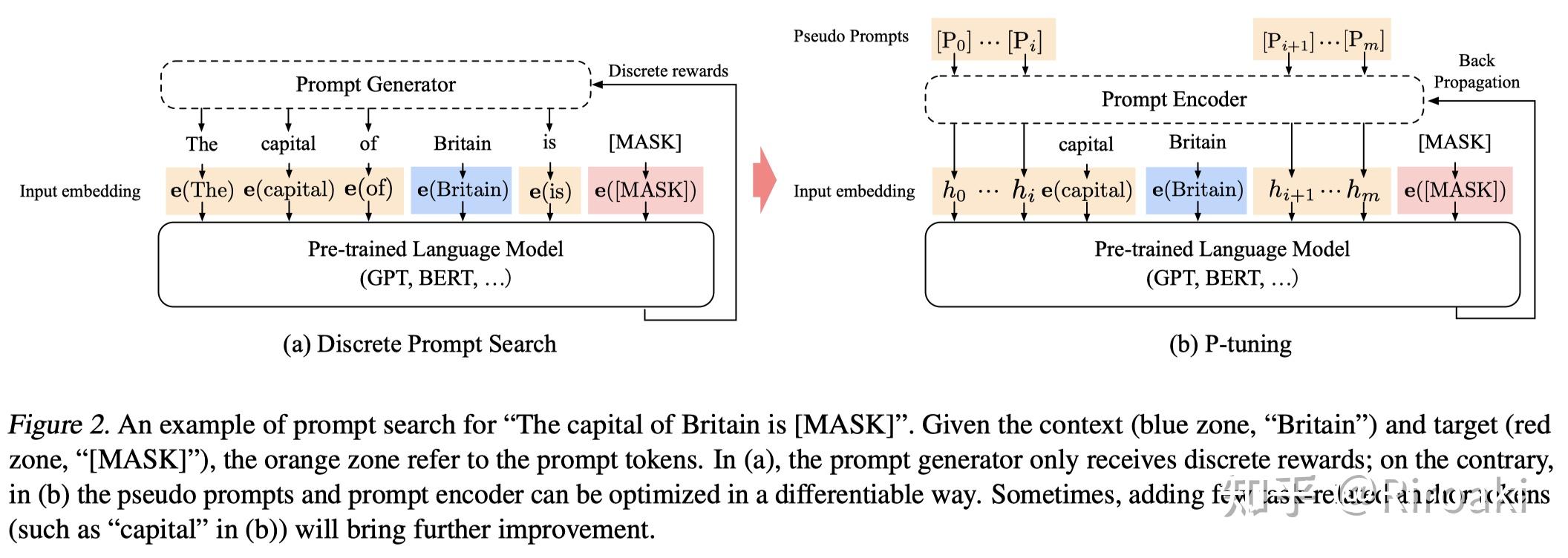
为了(1)保持语义的关联、(2)保持token间的上下文依赖关系,作者使用一个可训练LSTM模型——即上图(b)中的Prompt Encoder——生成的embedding替换模版中的词。
- 在这一基础上,对某些和任务相关的token进行保留(task-related anchors),比将它们也随机训练带来的效果更好。——anchors是怎么选的?好像论文没说……
- 然后在少样本场景,只训练LSTM(即只进行寻找prompt);
- 在全量数据场景,全部参数进行fine-tuning(即寻找prompt和fine-tuning共同进行)。
在LAMA和SuperGLUE上进行测试:
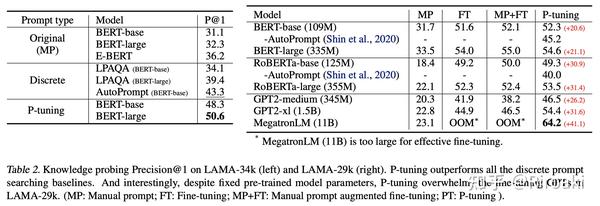

LAMA上的结果表明:
- PT > MP + FT > FT > MP
- PT > AUTOPROMPT > LPAQA > MP
然后是SuperGLUE,对比BERT-large和GPT2-medium(和base结果类似,这里只贴一个):
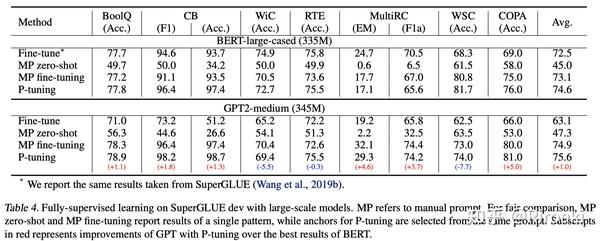

- 除了和LAMA类似的结论,GPT2虽然还是有一些任务比不过BERT,但是还是很不错的。
然后,这里又拿出前辈PET进行比较:
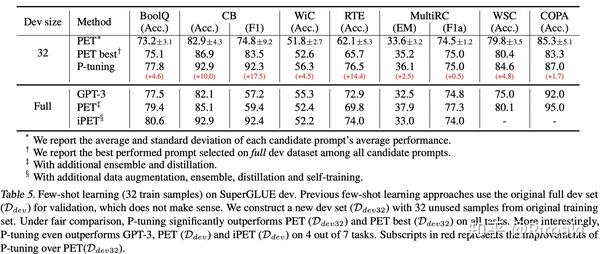

- 相比起来,iPET使用了数据增强、模型集成、蒸馏技术,然而还是比不过P-Tuning(读出了作者的小骄傲哈哈);
- 这张表上半部分除了使用32个train以外,还用挑选的32个dev进行验证,大部分任务的效果依然超过了GPT-3和PET,说明了P-Tuning的有效性。
补充1:那么问题来了,连续的prompt和离散的有多接近呢?文章中没有提及…… 补充2:用LSTM这一操作多少有点迷惑和不自然……可以参考苏神的版本,不加LSTM直接训练的讨论:
补充:又看到一篇NLG上的Prefix-Tuning方法《Prefix-Tuning: Optimizing Continuous Prompts for Generation》,有兴趣的读者可以去了解一下~
4 小结
- 在低资源场景(半监督、少样本以至于零样本)下,Prompt对LM的直接预测以及fine-tuning具有明显的增益(甚至,是否可以考虑不做tune只加prompt的方法);
- 目前而言,不确定prompt对LM的增益主要来源于完形填空这一任务设置与其预训练MLM流程保持了形式的一致性,还是搜索到的提示词为预测带来的帮助;
- 现在有这么多种prompt(或者叫额外输入):GPT-3的task description、完形填空的prompt、甚至连续的prompt以及额外样本demonstration,从本质上是不一样的,对模型效果的提升的相同之处和不同方面还有待研究——为什么这个prompt效果好,为什么那个不好,是否有一种统一的最优方案,也是值得探索的问题;
- 目前来看prompt的优化搜索空间很大,但是它主要提升的少样本场景本身就缺少训练数据,自然需要人工的先验来帮助模型,这人工先验又不一定有效,是一个矛盾的点。
