
Python爬虫基础练习(三) 豆瓣电影《头号玩家》短评爬取

一个朋友正在学习数据分析方面的知识,知道我在学习爬虫后,抱着考考我的想法让我帮她爬取豆瓣上的影评,这么一来,肯定不能说我不会呀,所以今天我们要爬取的是豆瓣电影《头号玩家》的短评。
运行平台:Windows
Python版本:Python3.6
IDE: Sublime Text Python自带IDLE
其他:Chrome浏览器
简述流程为:
步骤1:通过Chrome浏览器检查元素
步骤2:获取单个页面HTML文本
步骤3:用正则表达式解析出所需要的信息并存入列表
步骤4:将列表中的信息存成csv文件
步骤5:利用start参数爬取其他页的短评
首先,我们打开豆瓣电影,找到之前很火的一部电影《头号玩家》的短评网页,然后同样的套路,右键检查


找到我们要爬取的信息,一般分析这些数据需要的应该也就是评论了吧,不过知道是谁评论的以及什么时候评论的就更好了。通过检查。我们可以看到这三个要素在哪个块中,其中时间那栏可以看到,属性里面还有时刻出现,而文本中只有日期,既然都要爬取了,详细点的好,所以等会我们提取时提取的是属性中的时间。
然后就又是用requests访问这个网页了,这里没有用到之前提及的通用代码框架,而是通过返回的状态码是否为200来决定是否返回HTML文本,用try/except异常处理防止访问出错。
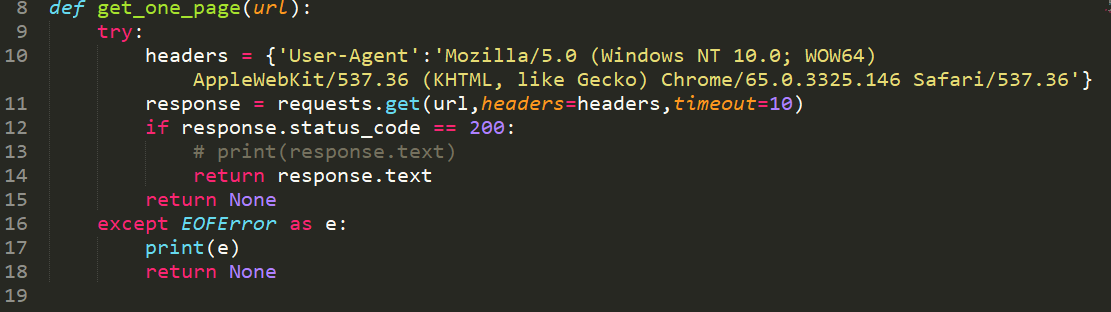

这里提到了requests中get方法的一个参数headers,这个参数是什么呢?用浏览器打开网址。然后按下F12+F5,选中左侧栏中其中一个响应,然后点击右侧栏上方的headers,就可以在Request Headers中找到这里体提及的User-Agent(简称UA),这个参数表示的服务器识别客户使用的操作系统及版本,浏览器及版本等信息,使用headers,可以伪装为浏览器,防止被识别为爬虫。当然其他位于Request Headers的请求头信息也都可以写入参数中。
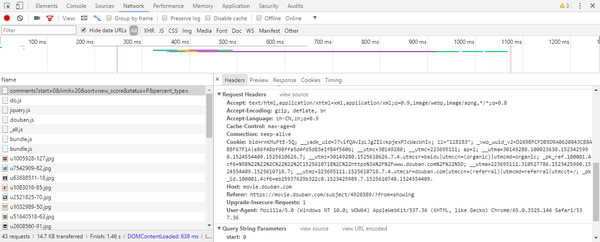

这里我们可以用测试网站来看看添加UA前后的区别。测试网站链接为http://httpbin.org/get,对这个网站发起Get请求后,它会返回相应的请求信息,如图所示:


可以看到没有添加UA的时候,UA的值为“python-requests/2.18.4”,在cmd中输入命令pip list可以查到这个就是电脑里安装的requests库的版本号,所以这个很容易被识别为爬虫。
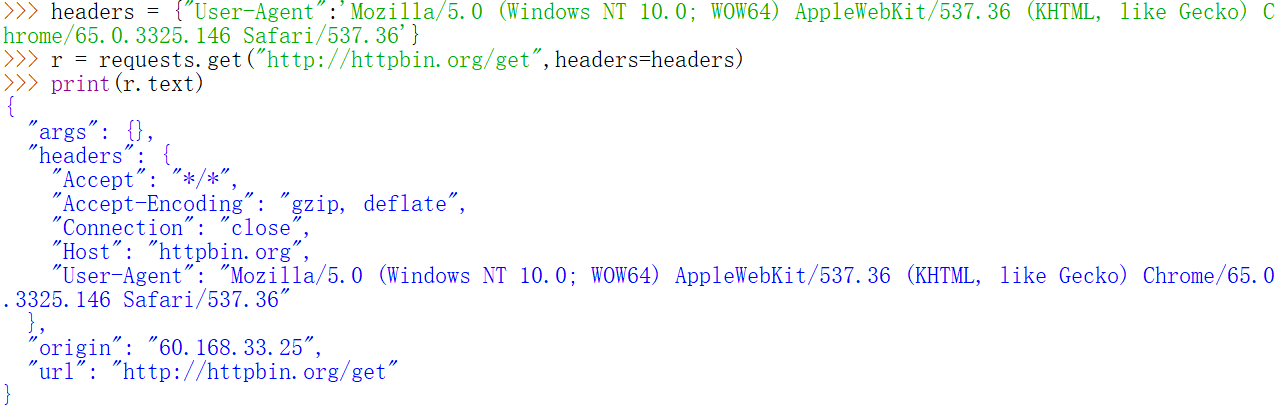

修改了UA之后,请求头中的返回信息将会改变为我们添加的UA,而这个UA也是直接从浏览器审查元素时复制过来的。
接下来就是提取信息了。
今天我没有用BeautifulSoup解析HTML文本,而是直接用正则表达式提取HTML文本中的信息。正则表达式看起来是很繁琐的,但它在提取一些显而易见的信息时还是比较好用的,并且提取的速度也快于BeautifulSoup。回到今天提取信息的这个函数。
首先我们重新看一下元素位置,可以使用浏览器看,也可以使用刚才的访问网页的函数print文本查看,这里我们使用浏览器查看。
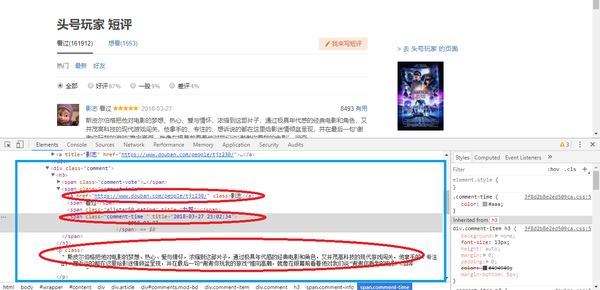

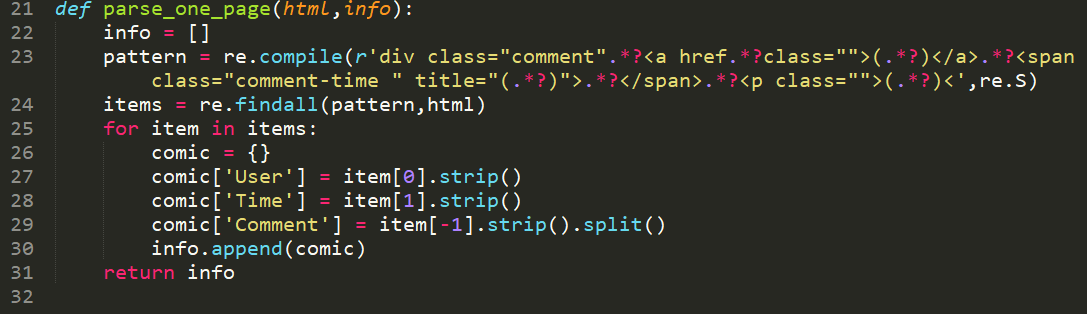

可以看到,蓝色框中则是我们要提取信息的一个块,红色椭圆中则是我们要提取的三条信息。首先我们用compile()方法将正则字符串编译成正则表达式对象,而在这个正则字符串(r'div class="comment".*?<a href.*?class="">(.*?)</a>.*?<span class="comment-time " title="(.*?)">.*?</span>.*?<p class="">(.*?)<',re.S)中,r是前缀,表示非转义的原始字符串,随后的就是HTML文本的匹配,其中(.*?)括号中的分组即为我们想要匹配的信息,.* 表示匹配除换行符之外的任意字符,加个?表示非贪婪模式,也就是匹配符合匹配条件的最少字符。最后记得写出标签的后半部分,对匹配的信息封闭,不然很容易匹配到多余信息。最后的re.S使得 . 可以包括换行符在内的任意字符,如果只是符号 . 是不包括换行符的。想知道更多正则表达式的话可以转到这个链接:正则表达式30分钟入门教程
然后使用findall()方法在html这个返回的文本中查询所有符合匹配信息的结果,findall()方法返回的是一个列表,所以随后我们可以用for循环迭代,并用字典提取出存在其中的信息,由于提取的信息里前后可能存在空格,所以这里用strip()去除前后空格,评论信息中可能中间也会存在空格,这对于之后存成csv文件时,会有格式上的影响,所以再用spilt()分割,不带参数时,默认是空格作为参数。最后用一个列表将所有信息保存起来。


这里存入的文件形式时csv文件,这个文件是以纯文本形式存储表格数据,可以使用Excel打开该文件。我们的信息是以字典形式放入列表中的,所以在写入csv文件时,可以用字典的写入方式。首先用‘a’追加的方式打来开文件,其中newline=''是为了不让csv文件换行写入,然后用fieldnames定义了三个字段,分别对应我们存入字典时的key,然后将其传给DictWriter来初始化一个字典写入对象,接着调用writerheader()写入头信息,最后用writerrow()方法写入对应信息。
存入文件时如果没有用try/except处理的话,会出现gbk错误,这是因为有些用户的名字用了非法字符,所以识别不出来,当用了异常处理后,就过滤掉了这个用户的评论,这其实是不正确的做法,使得信息缺失了。我也尝试了用encoding='utf-8'的制指定编码方式,但这样爬取到的信息为乱码,不知道怎么从代码层面去修改,从百度上找到其他人的解决办法,但未能成功解决,如果你有好的办法,不妨告诉我呀,不胜感激。
最后由于短评页数不止一页,所以可以通过翻页找到url页数不同的规律,发现是start参数的不同,所以我们传入url的时候可以用字符串的拼接的方法,然后主函数传参,就可以爬取到不同页数的短评了。
代码如下:
import requests
import re
import csv
import time
def get_one_page(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
response = requests.get(url,headers=headers,timeout=10)
if response.status_code == 200:
# print(response.text)
return response.text
return None
except EOFError as e:
print(e)
return None
def parse_one_page(html,info):
info = []
pattern = re.compile(r'div class="comment".*?<a href.*?class="">(.*?)</a>.*?<span class="comment-time " title="(.*?)">.*?</span>.*?<p class="">(.*?)<',re.S)
items = re.findall(pattern,html)
for item in items:
comic = {}
comic['User'] = item[0].strip() #去除两端空格
comic['Time'] = item[1].strip()
comic['Comment'] = item[-1].strip().split()
info.append(comic)
return info
def write_to_file(info):
with open('《头号玩家》短评.csv','a',newline='') as f:
fieldnames = ['User','Time','Comment']
writer = csv.DictWriter(f,fieldnames=fieldnames)
writer.writeheader()
try:
writer.writerows(info)
except:
pass
def main(start):
info = {}
url = 'https://movie.douban.com/subject/4920389/comments?start=' + str(start) + '&limit=20&sort=new_score&status=P&percent_type='
html = get_one_page(url)
data = parse_one_page(html,info)
write_to_file(data)
if __name__ == '__main__':
for i in range(10):
main(i*20)
print('本页采集完毕。') # 采集完一页后的标识
time.sleep(1) # 采集完一页休息一秒我这里只采集了9页的短评,用Excel打开后如下图所示:


用户,时间和评论都获取到了,我也可以去交任务了。

