
基于元学习(Meta-Learning)的冷启动推荐模型

引言
在真实的推荐系统中,会有源源不断的新用户、新物品加入,这些新加入系统的用户和物品由于缺乏足够丰富的历史行为数据,常常不能获得准确的推荐内容,或被准确推荐给合适的用户。这就是所谓的推荐冷启动问题。冷启动对推荐系统来说是一个挑战,究其原因是因为现有的推荐算法,无论是召回、粗排还是精排模块,都对新用户、新物品不友好,它们往往过度依赖系统收集到的用户行为数据,而新用户和新物品的行为数据是很少的。这就导致新物品能够获得的展现机会是偏少的。
对于某些业务来说,及时推荐新物品,让新物品获得足够的曝光量对于平台的生态建设和长期受益来说都是很重要的。比如,在新闻资讯的时效性很强,如不能及时获得展现机会其新闻价值就会大大降低;自媒体UGC平台如果不能让新发布的内容及时获得足够数量的展现就会影响内容创作者的积极性,从而影响平台在未来能够收纳的高质量内容的数量;相亲交友平台如果不能让新加入的用户获得足够多的关注,那么就可能不会有源源不断的新用户加入,从而让平台失去活跃性。
目前冷启动推荐大致有以下几种思路:
- 基于物品的属性数据(side information),比如利用商品的类目、品牌等信息;文章的作者、类别、关键词、摘要等。
- 基于其他领域的知识,比如领域知识图谱等
- 使用元学习(meta learning)的方法
- 基于试错的Contextual Bandit的方法
基于Contextual Bandit的方法,之前的文章中已有介绍,具体可以关注这两篇文章:《Contextual Bandit算法在推荐系统中的实现及应用》、《在生产环境的推荐系统中部署Contextual bandit算法的经验和陷阱》。
本文主要关注使用元学习的方法,在AAAI 2021中收录了一篇使用使用元学习方法解决推荐系统中的物品冷启动序列推荐的问题,题目为《Cold-start Sequential Recommendation via Meta Learner》,文本对该文章的思路进行详细解读,并指出作者所提出的方法跟我们已经熟悉的一些算法模型之间的关联,从而更好地帮助读者理解文章的内容。本文追求的目标是让即使对元学习一无所知的读者也能够轻松理解文章的内容。
背景知识
元学习(Meta-learning)是一种学习方法,它能够学习一个在多个任务间具有泛化能力的模型。听起来比较抽象,什么叫在多个任务间具有泛化能力的模型呢?实际上,它是相对于常规的学习方法学到的模型只能用来解决特定的任务,比如你训练了一个区分猫狗的模型,这个模型就只能用来区分猫和狗,它并不能用来识别苹果和梨。而元学习就有这种能力,它学习到的模型要么既能够区分猫狗又能够区分苹果和梨,要么基于元学习模型生成的子模型使用很少量的样本微调之后就能够得到一个能够识别苹果和梨的模型。需要注意的是,元学习模型的训练数据中不需要测试任务的样本,也就是说不需要苹果和梨的标注样本,这就是元学习的神奇之处。元学习又被称之为learn to learn,即学会学习,可见它强调的是学习这件事的底层逻辑。
元学习在很多场景下都被当成是达成少样本学习(few-shot learning)的一种方法,但元学习的能力和应用范围不仅限于此。少样本学习是一类使用少量的样本就能够训练出一个效果还不错的模型的方法。元学习和少样本学习经常出现在相同的语境中,因此很多人搞不清楚它们之间的关系。实际上,它们之间并没有谁包含谁的关系,只是说元学习可以用来解少样本学习的问题。解决少样本学习问题也不仅仅只有元学习这一种方法,还包括多任务学习、数据增强、半监督学习等等。当然,元学习也不仅仅只能用来解少样本学习的问题,它还可以用来做AutoML、协助强化学习等。
元学习的核心想法是先学习一个先验知识(prior),这个先验知识对解决 few-shot learning 问题特别有帮助。元学习解决的问题可以简单描述如下:
- A model is given a query sample belonging to a new, previously unseen class
- It is also given a support set, S, consisting of k examples each from n different unseen classes
- The algorithm then has to determine which of the support set classes the query sample belongs to
举一个火星文识别的例子如下:
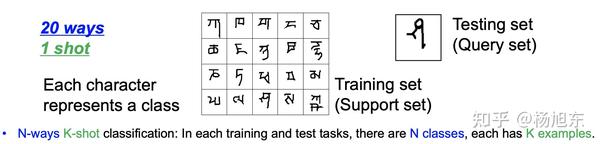

你能看出来上图中右边那个待识别的字符属于左边的20个不同字符中的哪一个吗?如果你认为是最下面一行最中间的那个,那么我们的意见是一致的。现在请你想一想你是怎么得出这个结论的,你得出这个结论的方法是什么?我问这个问题的目的是想让你比较一下,我接下来要介绍的基于度量的元学习方法在做这个学习任务时使用的方法与你自己做出判断的方法有什么异同,也就是机器和人类在学习同一个任务时所使用的方法有什么异同。
元学习方法通常分为三类:memory-based, metric-based, optimization-based。本文只会解释其中的一种,即基于度量(metric-based)的方法,因为我们要解读的论文中所介绍的冷启动推荐模型只涉及这一类元学习方法。当然,元学习只是解读作者所提模型的一种视角,其实我们完全可以换一个不同的、跟元学习没有关系的视角来认识作者所提的方法。本文会带你用两种不同的视角来解读作者提出的方法,除了元学习,另一种解读视角可能你会更加熟悉,它能够把作者提出的方法跟你已经熟悉的某个方法或模型联系起来,让你有一种“旧瓶装新酒”的熟悉感。学习的乐趣大概就在于让自己大脑中孤立的知识之间建立联系,最终达到融会贯通的境界吧!
我们还是先从元学习的视角来看看问题是如何被解决的吧。
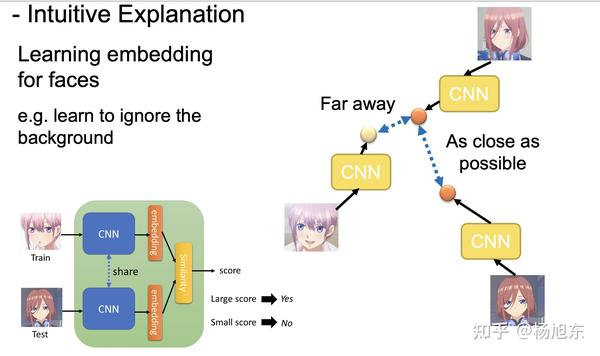
先别着急,让我们先来看看什么是基于度量的元学习方法,它是怎么解少样本学习问题的。我们从人脸验证这样一个典型的少样本学习任务开始。现在很多智能手机都有人脸解锁的功能,在录入人脸时我们只录入了几张自己的照片,此后手机软件就能够准确验证使用者是不是注册用户,也就是说智能手机内的人脸验证模块只用了有限几张图片就学习建立了一个准确的模型,它是如何做到的呢?


从元学习的角度出发,学习器接受一系列训练任务,在这些任务上训练得到一个模型,称之为元模型。在接受到一个测试任务时,由元模型生成一个子模型,这个子模型在测试任务上用很少量的样本训练后就能达到一个不错的性能水平。元模型和子模型通常在结构上是一样的,元模型用来为子模型提供初始化参数。从这个意义上来讲,元学习与迁移学习的预训练-微调的流程比较类似,但其实还是有区别的。迁移学习的预训练任务通常只有一个,而元学习的训练任务通常有很多;迁移学习一般情况下预训练模型需要在预训练任务上达到不错的性能,而元学习不需要元模型在训练任务上都达到不错的性能,它的目标是掌握学习方法,而不是学会某个具体的知识;迁移学习一般只能在比较类似的任务和数据集上做迁移,而元学习的测试任务与训练任务可以很不一样。
元模型能否不需要在测试任务上训练就能直接用来做测试任务呢?基于度量(metric-based)的方法得到的元模型是可以的。比如在人脸验证这个任务中,我们可以在由标注好两张人脸图片是否是同一个人的数据集上训练得到一个元模型,并直接用这个元模型来处理新的人脸验证任务。


我们可以用孪生网络模型来学习这个任务。两张输入图片经过一个共享参数的CNN网络提取到它们的embedding向量,再计算这两个embedding向量的相似度,如果两张图片是同一个人的照片,则学习器需使得向量相似度尽可能高,反之,则要使得向量相似度尽可能低,如下图所示。
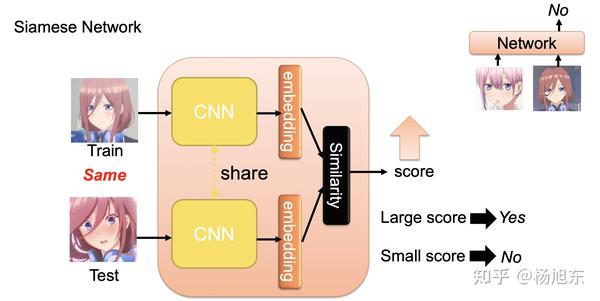


当然,每次只学习两张图片,学习效率比较低,为了提高学习效率,我们可以改造一下学习任务,比如可以让学习器学会判断给定的N张图片中哪一张与测试图片是同一个人,网络结构如下所示:


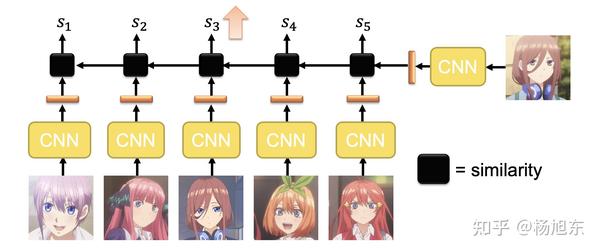

如果同一mini batch的训练/测试数据中同一个人的照片不止一张,而是K张,又该如何学习呢?这个时候可以用原型网络的思路,即对同一个人的K个embedding向量做一个池化操作(比如求均值)得到1个唯一的embedding向量,然后比较它与测试图片的相似度,从而判断测试图片是不是当前这个人。如下图:


模型框架
具体到推荐场景中,我们把上述学习任务中的图片换成用户的行为序列,比如点击浏览过的商品的序列,再把CNN特征提取器换成一个能处理不定长序列的特征提取器,比如RNN,Attention等,就可以用上述原型网络来处理序列推荐问题了。即给定当前访问用户的历史行为序列,对应上述任务中的测试图片,我们通过比较该行为序列与索引库中的行为序列的相似度,找出索引库中最相似的行为序列,把这个最相似的行为序列中的最后一个商品作为下一个推荐给用户的商品。实际上作者就是这么做的。
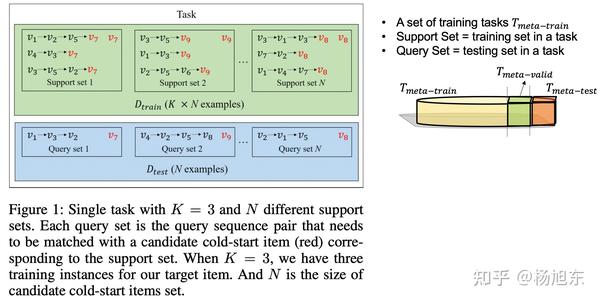

训练数据中每个行为序列的最后一个item作为该序列的label,在上图中用红色标注。上图中的每一个序列可以想象成是之前人脸验证任务中的一张图片,同一个support set对应同一个人的K张图片。这个K个序列的embedding向量需要经过一个池化操作得到唯一的一个embedding向量,再用来和每个query set中的序列的embedding向量求相似度,以便确定query set的label。
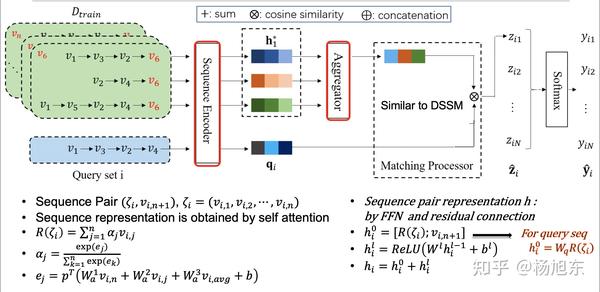

具体的网络结构如上,其中Aggregator直接使用平均池化操作。在原始论文中上图中的Matching Processor部分是一个复杂的相似度计算结构,为了便于理解,先用简单的直接算余弦相似度的方法。作者用了self attention的方法得到序列的embedding向量,具体的公式在上图中已经呈现,不再赘述。需要注意的是,query set中的序列Pair的embedding特征计算方式与support set中的方式稍微有点不同,这是因为query set不能够把label的信息编码到embedding向量中,因为在预测的时候是没有label可用的。
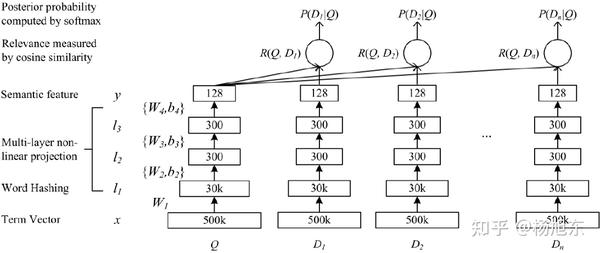
看到这个网络结构,大家有没有一种似曾相识的感觉?每次它其实非常类似于我们熟悉的DSSM模型,熟悉DSSM模型的朋友看到这里就已经明白在这个推荐场景下套用所谓的元学习,其实就是新瓶装旧酒而已。

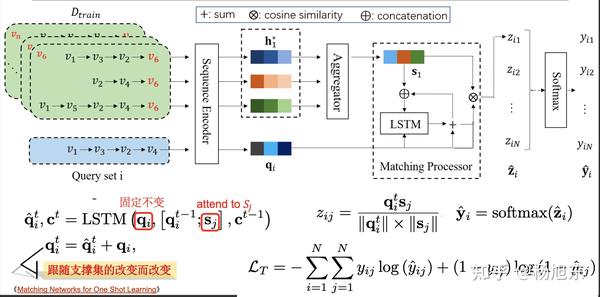
我们接下来看看Matching Processor到底做了什么。这里用了一个形式上的LSTM模型来做相似度计算,具体的公式见下图,值得注意的是,这里的LSTM只是当成一个计算函数用的,并没有一个实体的序列与之对应(不要认为输入是query set中的序列哦)。为什么这里需要用这种形式的相似度计算呢?其实这个计算公式来自于Matching Network,但是为了计算上的简便,作者做了简化。Matching Network设计这样的相似度计算函数是基于这样一种假设:元学习的训练任务与测试任务很可能是不同类型的任务,比如训练任务是识别区分猫与狗,而测试任务是识别苹果与梨,也就是说训练任务与测试任务的数据集可能完全不同。那么为了让训练阶段得到的模型可以不用在测试任务上微调就可以直接应用,所以在计算相似度时需要把测试任务的support set的信息也编码进去。然而,我们这个推荐场景的任务并不存在训练任务与测试任务的不同,因此我认为没有必要设计这样复杂的相似度计算函数。虽然作者通过消融实验证明了该函数有助于提升效果,但这样会导致预测阶段每一个query都需要与索引库中的所有序列算相似度,不能使用成熟的向量匹配引擎,从而大大限制了模型能够应用的规模,因此我认为Matching Processor部分是这个模型框架在设计上的一个败笔,应该去掉。去掉这个部分之后,该模型与DSSM模型也就没有什么本质区别了。

最后,作者提到了一些模式使用过程中的tricks,这些trick对于保证模型的效果是很重要的:
1)数据增强 E.g. A sequence ( v_0,v_1,v_2,v_3 ) is divided into three successive sequences: ( v_0,v_1 ) , ( v_0,v_1,v_2 ) , ( v_0,v_1,v_2,v_3 )
2)模型预训练 使用Top部分(非冷启动)的物品做模型预训练,得到 item embedding 模型训练时用预训练得到的item embedding做初始化
总结
本文介绍了一种物品冷启动推荐方案,其主要思想是相似的行为交互序列会到达相似的物品(相似的session里包含类似的物品)。其中,物品的特征为历史行为交互序列(k个序列对应k组特征)。并且,历史行为序列中的每个对象可以使用任意的encoder得到embedding, 可以在encoder中融入side information。提出的模型与DSSM很像;本质是是一种Nearest Neighbor++ 算法;++主要体现在 1. 可以End-to-End训练出sequence的embedding;2. 距离的计算跟样本有关。
需要注意的是,该模型对冷启动物品的定义是在用户session中很少出现过的物品,也就是只有少量用户行为序列包含了的物品,而不是全新的物品,因为全新的物品完全不会包含在任何行为序列中,也就没法构建模型需要的特征。这一点也使得模型的应用范围大打折扣。总之,个人觉得该模型的实用性不高,了解一下思路即可。全新物品的冷启动问题的解法方案可参考这两篇文章:《Contextual Bandit算法在推荐系统中的实现及应用》、《在生产环境的推荐系统中部署Contextual bandit算法的经验和陷阱》。

