一文看懂 Controller Manager


Controller Manager 由 kube-controller-manager 和 cloud-controller-manager 组成,是 Kubernetes 的大脑,它通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。

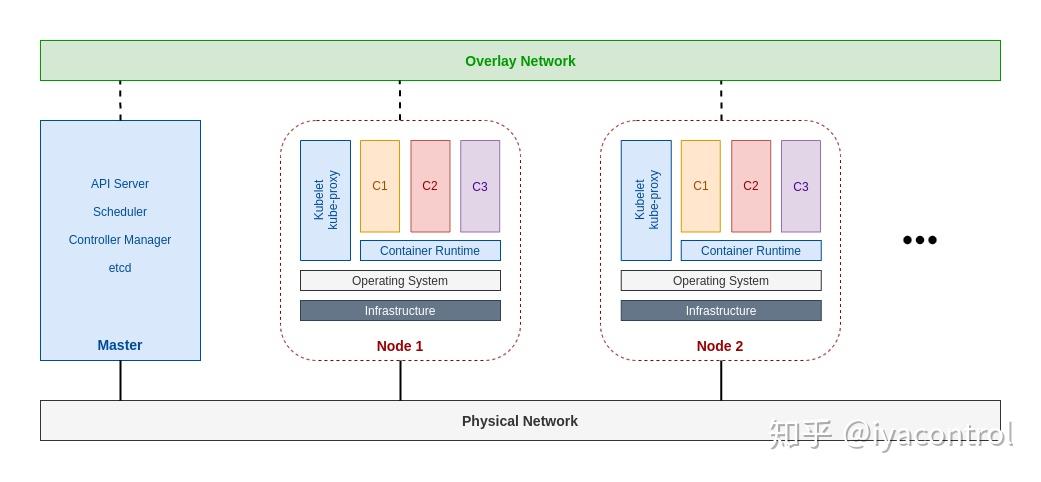
kube-controller-manager 由一系列的控制器组成
- Certificate Controller
- ClusterRoleAggregation Controller
- Node Controller
- CronJob Controller
- Daemon Controller
- Deployment Controller
- StatefulSet Controller
- Endpoint Controller
- Endpointslice Controller
- Garbage Collector
- Namespace Controller
- Job Controller
- Pod AutoScaler
- PodGC Controller
- ReplicaSet Controller
- Service Controller
- ServiceAccount Controller
- Volume Controller
- Resource quota Controller
- Disruption Controller
cloud-controller-manager 在 Kubernetes 启用 Cloud Provider 的时候才需要,用来配合云服务提供商的控制,也包括一系列的控制器,如
- Node Controller
- Node Lifecycle Controller
- Route Controller
- Service Controller

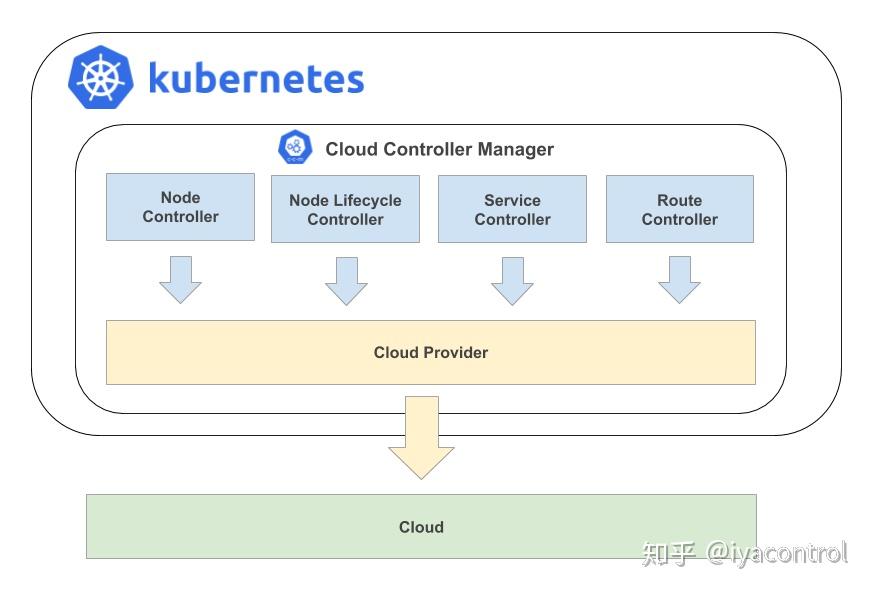
基本上,每个控制器都负责Kubernetes中的特定资源。作为一个集群管理员,必须了解每种控制器的功能。那控制器是如何工作的那?
工作原理
在机器人技术和自动化领域,控制回路(Control Loop)是一个非终止回路,用于调节系统状态。比如温度自动控制,当你设置了温度,告诉了温度自动调节器你的期望状态(Desired State)。 房间的实际温度是当前状态(Current State)。 通过对设备的开关控制,温度自动调节器让其当前状态接近期望状态。


在 Kubernetes 中,控制器通过监控集群的公共状态,并致力于将当前状态转变为期望的状态。
一个控制器至少追踪一种类型的 Kubernetes 资源。这些对象有一个代表期望状态的spec字段。 该资源的控制器负责确保其当前状态接近期望状态。每个控制器的control loop 可以用以下的伪代码来解释:
for {
desired := getDesiredState()
current := getCurrentState()
makeChanges(desired, current)
}讲到这里,我们基本上明白控制器工作原理了。那一个控制器包含哪些组件那?进而我们可以实现一个自定义的控制器。
控制器有两个主要组件:Informer/SharedInformer 和 Workqueue。 Informer/SharedInformer监视Kubernetes对象当前状态的变化,并将事件发送到Workqueue,然后由Workers pop 事件进行处理。


Reflector 和 APIServer 建立长连接,并使用 ListAndWatch 方法获取并监听某一个资源的变化。List 方法将会获取某个资源的所有实例(如ReplicaSet、Deployment等),Watch 方法则监听资源对象的创建、更新以及删除事件,获取到的事件称之为一个增量(Delta),该增量会被放进一个称之为 Delta FIFO Queue,即增量先进先出队列中。
然后,Informer会不断的从 Delta FIFO Queue 中 pop 增量事件,并根据事件的类型来决定新增、更新或者是删除本地缓存,也就是 Local Key-Value Sotrage。根据集群中某资源的事件来更新本地缓存是Informer的第一个职责。
Informer 的另外一个职责就是根据事件类型来触发事先注册好的 Event Handler。在回调函数中通常只会做一些简单的过滤处理,然后将该事件的Key(注意不是事件本身,只是事件的key,key的格式如<resource_namespace>/<resource_name>)添加到 Work Queue 这个工作队列中。
Work Queue提供了方便的功能来管理事件的Key。下图描述了Work Queue 事件的Key的生命周期:


在处理事件失败的情况下,控制器将调用AddRateLimited()函数将其Key推回到Work Queue,以便以后以预定义的重试次数进行处理。否则,如果处理成功,则可以通过调用Forget()函数从Work Queue中删除Key。但是,该功能只能停止Work Queue跟踪事件的历史记录。为了将事件Key从Work Queue中完全删除,控制器必须触发Done()函数。
接下来就是 Controller 的业务逻辑了,也就是上图中的 Processer。控制器从 Work Queue 中取出一个事件Key,然后通过indexer从本地存储获取具体事件,并根据自身的业务逻辑对其进行处理,不同的控制器会有不同的处理逻辑。
社区提供了一个示例controller -- sample-controller 。大家可以参阅学习。
编写一个自定义控制器,我们需要注意另外一个参数:resyncPeriod。如果resyncPeriod不为零,那么Reflector为以resyncPeriod为周期定期执行list的操作,这样就可以使用Reflector来定期处理所有的对象,也可以逐步处理变化的对象。
发展趋势
随着Kubernetes普及,当我们试图将所有的应用都容器化,进而部署到Kubernetes中的时候,我发现官方原生提供的工作负载(Deployment, Statefulset, Daemonset)并不能满足我们的需求。此时社区出现了诸多的方案,比如阿里推出了面向自动化场景的 Kubernetes 应用负载扩展控制器 -- kruise。
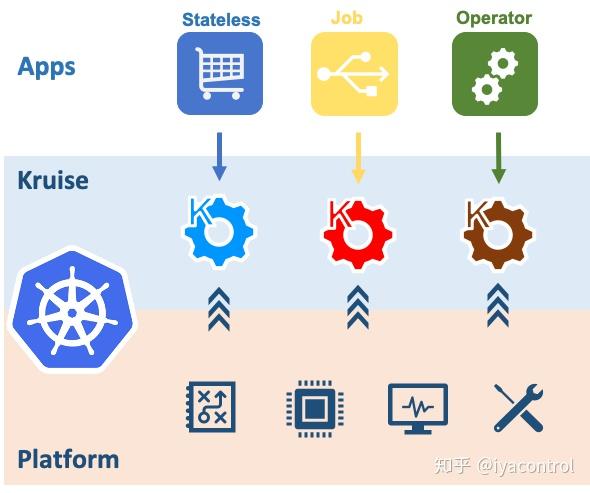

Kruise 提供了CloneSet等新的工作负载形式。
另外在弹性伸缩领域,诸如Keda等事件触发HPA控制器。
其实未来会有更多的领域,基于控制器控制模式和申明式API,编写特定领域的控制器,来满足各种场景。
