DL应用:query生成和query推荐

摘要: 在机器翻译、图片描述、语义蕴涵、语音识别和文本摘要中,序列到序列的问题已经有太多大牛研究了,也取得了很多突破。谷歌的Attention is all you need[1],舍弃并超越了主流的rnn与cnn序列建模框架,刷出了新的state of the art,这种大胆创新的精神值得我们学习。
原文:http://click.aliyun.com/m/42450/
1 引言
在机器翻译、图片描述、语义蕴涵、语音识别和文本摘要中,序列到序列的问题已经有太多大牛研究了,也取得了很多突破。谷歌的Attention is all you need[1],舍弃并超越了主流的rnn与cnn序列建模框架,刷出了新的state of the art,这种大胆创新的精神值得我们学习。后面相信会有更多的attention变体甚至和rnn/cnn结合的电路图涌现,当然我们更期待的不是这些,我们更向往大道至简。我们在follow的同时,也期望自己的每一个新的想法,新的尝试能够汇入深度学习的大浪,为人类的未来贡献自己的一份力量。
在电子商务搜索中,query作为表达用户意图的载体起到了非常重要的作用。如何根据用户的历史行为序列给用户推荐一个query,吸引用户发生搜索以及后续的成交是非常有意义的,比如淘宝的底纹推荐。如下图是一个在iphone上的引导图,欢迎大家多多使用底纹。
2 技术方案
在技术方案这部分,我们首先介绍一下整体思路,然后重点讨论一下序列embedding.
2.1 整体思路
总的来说,思路主要有两种:
1)编码解码直接生成query;
2)把user向量和query向量映射到同样的向量空间里,然后通过向量相似召回来获取query,候选query是日志中已经存在的。
下面分别介绍下:
2.1.1 Sequence to sequence[2]
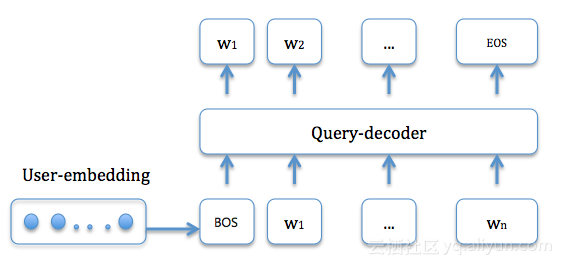
大体来说,这种思路一般是首先把source sequence通过一个encoder map成一个vector,然后用这个vector作为context向量去通过另一个decoder进行翻译得出output.后面有很多同行在这个基本思路上做了很多改进,我们尝试最基本的一种,没有把网络搞的很复杂。如下图所示,首先获取用户的行为序列,然后 encode成user-embedding向量,然后这个向量作为context向量来解码query,每一步解码一个词/字。在预测的阶段一般采取beam search搜索策略来获取最可能的topK个候选query的词序列。

2.1.2 向量召回
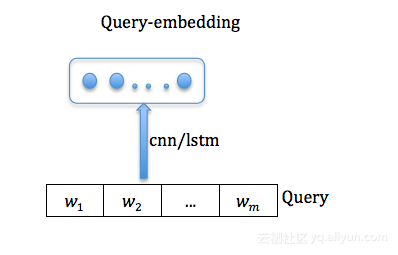
我们训练一个网络,让user-embedding和query-embedding映射到同一个向量空间里。user-embedding同上,query-embedding一般采取lstm或者cnn或者dnn都行。如下图所示:query word 表示为w1,w2,...wm.


在预测阶段,采取向量相似召回的策略,首先我们对候选query聚类成K个簇,然后采用二级查找的方式(首先查找topM相似的簇,然后再遍历topM相似簇中的query),获取每一个用户向量的topk相似query作为推荐结果。
2.2 序列embedding
2.2.1 Rnn-embedding
第一种是RNN,解决序列问题的标配。
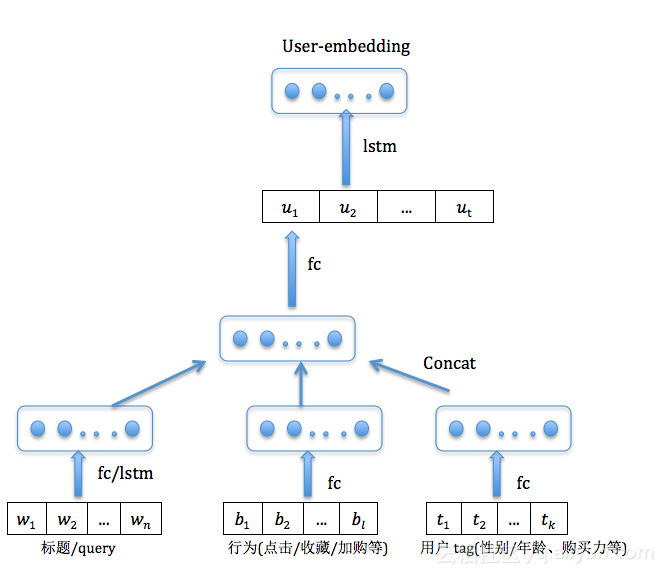
我们假设一个用户的一个时间序列向量是u1,u2...ut,其中下标i代表第i个时间步。每一个时间步的特征输入主要三类:
1) 文本特征:用户点击的标题/搜索的query;
2)行为特征:停留时间,是否点击/加购/收藏/购买等;
3)用户tag:性别,年龄,购买力等。
如下图所示,我们首先把每一个时间步对应的特征分别向量化然后concat然后再过一层全连输入到lstm中,一般采用lstm最后一步的输出作为decoder的context向量,当然还有更有效的方式,比如再加上attention机制。

2.2.2 WRT-embedding[3]
先简单说一下背景,神经网络在word embedding上的成功激起了大伙研究长文本embedding的热情,比如句子和段落都可以embedding,lstm似乎等到了最美的春天。但是,令人惊讶的是,Wieting等人[4]表示,这些复杂的方法被一些超级简单的方法超越了,这些简单的方法包括对word embedding进行轻度重新训练和基本的逻辑回归。
我们是从A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS[3]中得到启发,可以用一种简单有效的方法来获取文本向量,作者在论文中证明:在维基百科上的非标签语料库中使用流行的方法训练word embedding,将句子用词向量加权平均,然后使用PCA/SVD修改一下 。 这种权重在文本相似性任务中将效果提高了约10%至30%,并且击败了复杂的监督方法,包括RNN和LSTM, 它甚至可以改善Wieting等人[4]的embeddings.
作者称他的算法是WR,由于我们在权重里面加入了时间因素,所以暂且称之为WRT吧。算法非常简洁,作者也对他的算法做出了有力的理论解释。主要分2步:
W:就是词向量加权平均的时候的权重。
R: 使用PCA/SVD remove掉向量中的common部分。
下面是算法流程图:


上面的vw前面的系数a/a+p(w)代表词w的权重,我们在使用的时候会加上时间衰减因数,即f(tw)*a/a+p(w),其中f(tw)是时间衰减因子。然后对应的|s|我们也根据f(tw)进行了scale.
在上面的第一种方法中我们定义时间衰减为简单的单调函数,但是行为的时间不一定越远越不重要,比如每个类目的复购周期都是不一样的,所以我们想用下面的方法学习一下时间函数,这里把时间函数定义成多项式函数,因为多项式可以拟合任何函数。和上面直接在词维度上不一样的是,这里我们假设每一个时间步的ut已经按照WR方法embedding好了。
我们把时间函数定义为下式,里面的ti表示第i时间步距离当前的时间,时间的参数是m维:
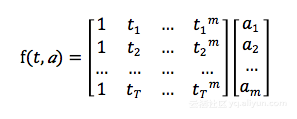
为了求解a,我们配置一个网络求解,首先我们把u进行一个t变换
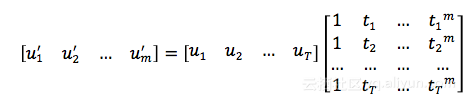

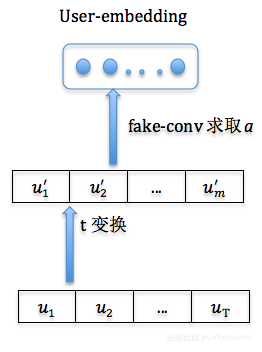
然后再配置一个fake-conv来求取a(图中的fake-conv虽然用卷积实现,但是其实和卷积关系不大,就是为了方便求取a参数。)
3. 实验
3.1 Sequence to sequence
我们在底纹数据集上进行了尝试,训练样本的格式是<使用底纹query之前的行为序列,使用底纹的query>.
在encode部分我们分别尝试了DNN和lstm,结果显示效果差别不大,用bleu指标对比:dnn_encoder:0.003,lstm_encoder:0.0025,dnn还稍微好一些。
在bleu的基础上,我们另外定义了召回率指标:用生成的topN和真实的topM比较,假设完全匹配topM中的K个(可带权重),定义召回率为(topN,topM,K/topM);如果召回率高,代表学到了真实数据的分布,同时新生成query质量也比较好,在底纹测试集上的召回率是(10,5,0.69).
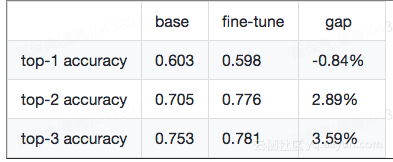
由于底纹的log在一些中长尾类目上比较少,后面我们还尝试了先用全量点击训练,再用底纹数据fine tune,结果显示收敛更快,在中长尾类目上泛化表现更好:
3.2 向量召回
3.2.1 Rnn-embedding
我们在搜索数据集上进行了尝试,训练样本的格式是<用户搜索query前的行为序列,搜索query>,根据搜索query之后的表现区分正例和负例。网络里面的标题是用doc2vec预测好的,没有更新标题对应的词向量,query向量用其点击的商品集合用doc2vec向量化。
最开始我们用女装类目数据训练,在预测集合上的cosin平均相似度是0.951,感觉还是非常高的。
后面扩展到全类目数据训练,抽查case发现预测的有些有些天马星空了。分析原因可能是用的当前搜索的query可能和前面的序列之间的意图跳跃比较大。后面做了2个改动:1)目标由"query"更改为"query点击的第一个宝贝"; 2)切分点由"30分钟"更改为"query预测的二档类目没有重合",然后再看,效果就好了不少。
3.2.2 WRT-embedding
这次我们依照比较直接的方式在底纹上进行尝试,值得一提的是,这个方法性能问题可以忽略不计。
我们按照类目维度给每个user根据其行为序列(只考虑点过的标题和搜索query的文本)向量化,然后通过向量相似召回top10个最相似的query作为推荐,bts结果显示相关业务指标有比较大的提升。
目前仅仅是考虑了内容相似度,后续如果上面加上一层gbdt融合其他特征排序后再推荐,预计还有很大潜力。
4 总结和展望
query生成/推荐基本是Sequence to sequence和向量相似召回两个思路,主流的RNN/CNN方法当时还是因为性能问题在应用上有点阻碍,所以我们尝试了一些在效果上不输于lstm但是非常简洁的方法,这些方法在性能上也非常给力,便于快速尝试获取结果。比较遗憾的是,user向量我们目前主要关注了文本内容特征,而用户的行为特征和用户tag特征并没有进行应用,也是后续需要改进的方向。
query生成我们后续可能会更关注于生成一些风格轻盈的自然语言,比如“微微一胖很倾城”,“露出一点小性感”,希望能让大家在购物的时候感受到一种美好的心情,顺便也能买到心仪的宝贝。
除了query生成这个主题,其实更重要的是怎么样利用好已有的其他候选,所以后续我们计划把学习到user序列向量和query向量的相似度作为特征参与query推荐的排序,这个预计会有更大的收益。
参考文献
[1] A Vaswani, N Shazeer, N Parmar, J Uszkoreit, L Jones ,... Attention Is All You Need
[2] I Sutskever, O Vinyals, QV Le. Sequence to sequence learning with neural networks
[3] Sanjeev Arora, Yingyu Liang, Tengyu Ma. A Simple but Tough-to-Beat Baseline for Sentence Embeddings
[4] John Wieting, Mohit Bansal, Kevin Gimpel, and Karen Livescu. Towards universal paraphrastic sentence embeddings.
更多技术干货敬请关注云栖社区知乎机构号:阿里云云栖社区 - 知乎
