【代码】StackGAN

Paper:StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN
TensorFLow code:hanzhanggit/StackGAN
论文笔记:【论文阅读】StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN
这篇学习代码↓↓↓
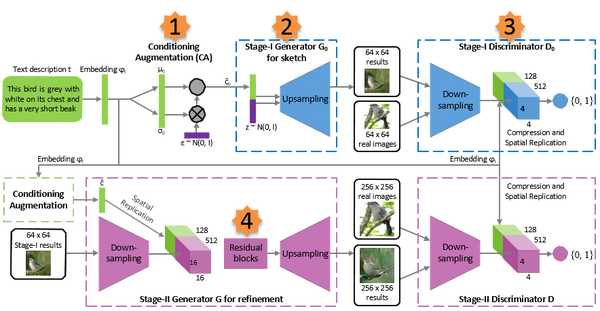

1.\varphi _{t}的处理
stackGAN 没有直接将 embedding 作为 condition ,而是用 embedding 接了一个 FC 层从得到的独立的高斯分布N(\mu (\varphi _{t}),\Sigma (\varphi _{t}))中随机采样得到隐含变量( \hat{c_0}=\mu_0+\sigma_0\odot\epsilon , \epsilon\sim N(0,I) )。其中\mu (\varphi _{t})和\Sigma (\varphi _{t})是关于\varphi _{t}的函数。之所以这样做的原因是,embedding 通常比较高维,而相对这个维度来说, text 的数量其实很少,如果将 embedding 直接作为 condition,那么这个 latent variable 在 latent space 里就比较稀疏,这对训练不利。
StageI/model.py
def generate_condition(self, c_var):
conditions =\
(pt.wrap(c_var).
flatten().
custom_fully_connected(self.ef_dim * 2).
apply(leaky_rectify, leakiness=0.2))
mean = conditions[:, :self.ef_dim]
log_sigma = conditions[:, self.ef_dim:]
return [mean, log_sigma]StageI/train.py
def sample_encoded_context(self, embeddings):
'''Helper function for init_opt'''
c_mean_logsigma = self.model.generate_condition(embeddings)
mean = c_mean_logsigma[0]
if cfg.TRAIN.COND_AUGMENTATION:
# epsilon = tf.random_normal(tf.shape(mean))
epsilon = tf.truncated_normal(tf.shape(mean))
stddev = tf.exp(c_mean_logsigma[1])
c = mean + stddev * epsilon
kl_loss = KL_loss(c_mean_logsigma[0], c_mean_logsigma[1])
else:
c = mean
kl_loss = 0
return c, cfg.TRAIN.COEFF.KL * kl_loss上述代码出现了KL损失,目的是正则化:为了防止过拟合或者方差太大的情况,generator 的 loss 里面加入了对这个分布的正则化:D_{KL}(\mathcal N (\mu(\phi_t), \Sigma(\phi_t)) || \mathcal N (0, I)) 。
StageI/model.py
# reduce_mean normalize also the dimension of the embeddings
def KL_loss(mu, log_sigma):
with tf.name_scope("KL_divergence"):
loss = -log_sigma + .5 * (-1 + tf.exp(2. * log_sigma) + tf.square(mu))
loss = tf.reduce_mean(loss)
return loss2.生成器 G_0
StageI/model.py
def generator(self, z_var):
node1_0 =\
(pt.wrap(z_var).
flatten().
custom_fully_connected(self.s16 * self.s16 * self.gf_dim * 8).
fc_batch_norm().
reshape([-1, self.s16, self.s16, self.gf_dim * 8]))
node1_1 = \
(node1_0.
custom_conv2d(self.gf_dim * 2, k_h=1, k_w=1, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_conv2d(self.gf_dim * 2, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_conv2d(self.gf_dim * 8, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm())
node1 = \
(node1_0.
apply(tf.add, node1_1).
apply(tf.nn.relu))
node2_0 = \
(node1.
# custom_deconv2d([0, self.s8, self.s8, self.gf_dim * 4], k_h=4, k_w=4).
apply(tf.image.resize_nearest_neighbor, [self.s8, self.s8]).
custom_conv2d(self.gf_dim * 4, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm())
node2_1 = \
(node2_0.
custom_conv2d(self.gf_dim * 1, k_h=1, k_w=1, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_conv2d(self.gf_dim * 1, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_conv2d(self.gf_dim * 4, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm())
node2 = \
(node2_0.
apply(tf.add, node2_1).
apply(tf.nn.relu))
output_tensor = \
(node2.
# custom_deconv2d([0, self.s4, self.s4, self.gf_dim * 2], k_h=4, k_w=4).
apply(tf.image.resize_nearest_neighbor, [self.s4, self.s4]).
custom_conv2d(self.gf_dim * 2, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
# custom_deconv2d([0, self.s2, self.s2, self.gf_dim], k_h=4, k_w=4).
apply(tf.image.resize_nearest_neighbor, [self.s2, self.s2]).
custom_conv2d(self.gf_dim, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
# custom_deconv2d([0] + list(self.image_shape), k_h=4, k_w=4).
apply(tf.image.resize_nearest_neighbor, [self.s, self.s]).
custom_conv2d(3, k_h=3, k_w=3, d_h=1, d_w=1).
apply(tf.nn.tanh))
return output_tensor
def generator_simple(self, z_var):
output_tensor =\
(pt.wrap(z_var).
flatten().
custom_fully_connected(self.s16 * self.s16 * self.gf_dim * 8).
reshape([-1, self.s16, self.s16, self.gf_dim * 8]).
conv_batch_norm().
apply(tf.nn.relu).
custom_deconv2d([0, self.s8, self.s8, self.gf_dim * 4], k_h=4, k_w=4).
# apply(tf.image.resize_nearest_neighbor, [self.s8, self.s8]).
# custom_conv2d(self.gf_dim * 4, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_deconv2d([0, self.s4, self.s4, self.gf_dim * 2], k_h=4, k_w=4).
# apply(tf.image.resize_nearest_neighbor, [self.s4, self.s4]).
# custom_conv2d(self.gf_dim * 2, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_deconv2d([0, self.s2, self.s2, self.gf_dim], k_h=4, k_w=4).
# apply(tf.image.resize_nearest_neighbor, [self.s2, self.s2]).
# custom_conv2d(self.gf_dim, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_deconv2d([0] + list(self.image_shape), k_h=4, k_w=4).
# apply(tf.image.resize_nearest_neighbor, [self.s, self.s]).
# custom_conv2d(3, k_h=3, k_w=3, d_h=1, d_w=1).
apply(tf.nn.tanh))
return output_tensor
def get_generator(self, z_var):
if cfg.GAN.NETWORK_TYPE == "default":
return self.generator(z_var)
elif cfg.GAN.NETWORK_TYPE == "simple":
return self.generator_simple(z_var)
else:
raise NotImplementedError连接c和z↓↓↓,调用get_generator生成fake_images。
配置文件中__C.GAN.NETWORK_TYPE = 'default'
StageI/train.py
def sampler(self):
c, _ = self.sample_encoded_context(self.embeddings)
if cfg.TRAIN.FLAG:
z = tf.zeros([self.batch_size, cfg.Z_DIM]) # Expect similar BGs
else:
z = tf.random_normal([self.batch_size, cfg.Z_DIM])
self.fake_images = self.model.get_generator(tf.concat(1, [c, z]))3.判别器D_{0}
首先\varphi _{t}经过一个全连接层被压缩到N _{d}维,然后经过空间复制将其扩成一个M _{d}\times M _{d}\times N _{d}的张量。同时,图像会经过一系列的下采样到M _{d}\times M _{d}。然后,图像过滤映射会连接图像和文本张量的通道。随后张量会经过一个1\times 1的卷积层去连接跨文本和图像学到的特征。最后,会通过只有一个节点的全连接层去产生图像真假的概率。
StageI/model.py
def context_embedding(self):
template = (pt.template("input").
custom_fully_connected(self.ef_dim).
apply(leaky_rectify, leakiness=0.2))
return template
def d_encode_image(self):
node1_0 = \
(pt.template("input").
custom_conv2d(self.df_dim, k_h=4, k_w=4).
apply(leaky_rectify, leakiness=0.2).
custom_conv2d(self.df_dim * 2, k_h=4, k_w=4).
conv_batch_norm().
apply(leaky_rectify, leakiness=0.2).
custom_conv2d(self.df_dim * 4, k_h=4, k_w=4).
conv_batch_norm().
custom_conv2d(self.df_dim * 8, k_h=4, k_w=4).
conv_batch_norm())
node1_1 = \
(node1_0.
custom_conv2d(self.df_dim * 2, k_h=1, k_w=1, d_h=1, d_w=1).
conv_batch_norm().
apply(leaky_rectify, leakiness=0.2).
custom_conv2d(self.df_dim * 2, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(leaky_rectify, leakiness=0.2).
custom_conv2d(self.df_dim * 8, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm())
node1 = \
(node1_0.
apply(tf.add, node1_1).
apply(leaky_rectify, leakiness=0.2))
return node1
def d_encode_image_simple(self):
template = \
(pt.template("input").
custom_conv2d(self.df_dim, k_h=4, k_w=4).
apply(leaky_rectify, leakiness=0.2).
custom_conv2d(self.df_dim * 2, k_h=4, k_w=4).
conv_batch_norm().
apply(leaky_rectify, leakiness=0.2).
custom_conv2d(self.df_dim * 4, k_h=4, k_w=4).
conv_batch_norm().
apply(leaky_rectify, leakiness=0.2).
custom_conv2d(self.df_dim * 8, k_h=4, k_w=4).
conv_batch_norm().
apply(leaky_rectify, leakiness=0.2))
return template
def discriminator(self):
template = \
(pt.template("input"). # 128*9*4*4
custom_conv2d(self.df_dim * 8, k_h=1, k_w=1, d_h=1, d_w=1). # 128*8*4*4
conv_batch_norm().
apply(leaky_rectify, leakiness=0.2).
# custom_fully_connected(1))
custom_conv2d(1, k_h=self.s16, k_w=self.s16, d_h=self.s16, d_w=self.s16))
return template
def get_discriminator(self, x_var, c_var):
x_code = self.d_encode_img_template.construct(input=x_var)
c_code = self.d_context_template.construct(input=c_var)
c_code = tf.expand_dims(tf.expand_dims(c_code, 1), 1)
c_code = tf.tile(c_code, [1, self.s16, self.s16, 1])
x_c_code = tf.concat([x_code, c_code],3)
return self.discriminator_template.construct(input=x_c_code)看到上述get_discriminator里函数名字不太一样,是因为在StageI/model.py最上面有如下定义:(配置文件中__C.GAN.NETWORK_TYPE = 'default')
if cfg.GAN.NETWORK_TYPE == "default":
with tf.variable_scope("d_net"):
self.d_encode_img_template = self.d_encode_image()
self.d_context_template = self.context_embedding()
self.discriminator_template = self.discriminator()
elif cfg.GAN.NETWORK_TYPE == "simple":
with tf.variable_scope("d_net"):
self.d_encode_img_template = self.d_encode_image_simple()
self.d_context_template = self.context_embedding()
self.discriminator_template = self.discriminator()
else:
raise NotImplementedError4.residual blocks
前一GAN生成的图形可能会存在物体形状的失真扭曲或者忽略了文本描述中的细节部分,所以再利用一个GAN去根据文本信息修正之前得到的图像,生成更高分辨率含有更多细节信息的图像。
- 生成器G:与前一个阶段相似,由\varphi _{t}生成N_{g} 维的高斯条件变量c然后被扩成一个M _{g}\times M _{g}\times N _{g}的张量。同时,由前一个GAN生成的图像会经过下采样变成M _{g}\times M _{g}。图像特征和文本特征连接起来扔到residual blocks(学习图像和文本的多模型表示),上采样生成图片。
- 判别器D:和阶段一差不多哦,只是由于这个部分图像的尺寸更大,所有有额外的一系列下采样块。
# stage II generator (hr_g)
def residual_block(self, x_c_code):
node0_0 = pt.wrap(x_c_code) # -->s4 * s4 * gf_dim * 4
node0_1 = \
(pt.wrap(x_c_code). # -->s4 * s4 * gf_dim * 4
custom_conv2d(self.gf_dim * 4, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_conv2d(self.gf_dim * 4, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm())
output_tensor = \
(node0_0.
apply(tf.add, node0_1).
apply(tf.nn.relu))
return output_tensor