
My solutions for `Google TensorFlow Speech Recognition Challenge`

前段时间利用业余时间参加了 Google Brain 在 Kaggle 平台上举办的 TensorFlow Speech Recognition Challenge,最终在 1315 个 team 中排名 58th:




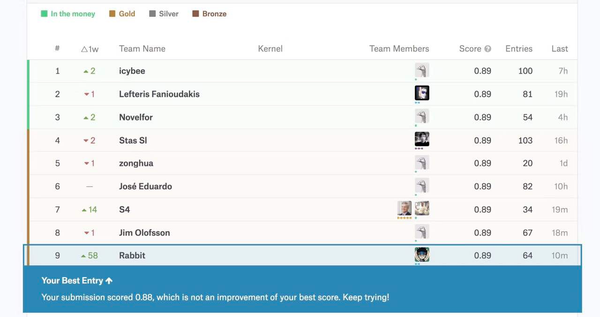

这个比赛并不是通常意义上说的 Speech Recognition 任务,专业点的说法是一个 keyword spotting 的活。从各 team 的解决方案,以及在该数据集上发表的学术论文来看,绝大部分是将其当作机器学习领域的典型分类任务: “给定固定长度数据(1 second 音频),判断类别 - 唤醒词 yes,no,up,down,left,right,on,off,stop,go + silence + unknown”
训练数据包含 60000 多条各唤醒词的音频,LeaderBoard 数据含有150000 条数据(与训练数据的不同: 说话人有变化,录音环境有变化)。
基于 speech_commands 分别实现了文章 [2, 3, 4, 5] 的模型,针对语音场景做了些许调整与优化,代码放在了 github 上:lifeiteng/TF_SpeechRecoChallenge
install
(sudo) pip install -e .model
典型的分类 pipeline:
audio -> Mfcc / Fbank -> [FeatureScale] -> deep neural networks [dnn / convnets ] -> class labels
model - baseline conv LeaderBoard Accuracy 0.77
[1] Sainath T N, Parada C. Convolutional neural networks for small-footprint keyword spotting[C]//Sixteenth Annual Conference of the International Speech Communication Association. 2015.
speech_commands 跑出来的基线系统
model - resnet LeaderBoard Accuracy from 0.85 -> 0.89
[2] Tang R, Lin J. Deep Residual Learning for Small-Footprint Keyword Spotting[J]. arXiv preprint arXiv:1710.10361, 2017.
- No FeatureScale + BatchNorm (The paper's architecture) + Mfcc 40: LB < 0.1
- No FeatureScale + remove BatchNorm + Mfcc 40: LB 0.84
- No FeatureScale + Add BN after input + BatchNorm + Mfcc 40: LB 0.86
如果不做 FeatureScale,根据论文 [2] 写出的模型,在 LB数据集上完全不work(从训练数据集合分出来的eval / test Accuracy 可以到 95%左右),在我苦逼的发了条微博之后,想到可以在 input 之后加层 BatchNorm 模拟 FeatureScale


- FeatureScale(centered mean) + BatchNorm + Mfcc 40: LB 0.85
- 实现 Feature Scale
big improvement (cmvn + Fbank80):
- FeatureScale(cmvn) + BatchNorm + Fbank80: LB 0.89333


cmvn: centered mean, div variance
其他修改:LB 0.88617 (在比赛时只显示到 0.88,赛后才看到具体分数,上面的config是最佳的)
commit: [922aa0d85](improve resnet)
+ Fbank 80
+ dropout
+ feature scale: centered mean (e.g. cmn)
+ [First Conv: kernel_size=(3, 10), strides=(1, 4)](https://github.com/lifeiteng/TF_SpeechRecoChallenge/blob/master/speech/model_resnet.py#L256)
+ use [MaxPool + AvgPool](https://github.com/lifeiteng/TF_SpeechRecoChallenge/blob/master/speech/model_resnet.py#L330)
model densenet LeaderBoard from 0.86 -> 0.88
[3] Huang G, Liu Z, Weinberger K Q, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, 1(2): 3.


model - ensemble LB 0.89745


没怎么花时间在上面,实际上 Kaggle 比赛都是拼 ensemble 拉开最后的差距,改比赛的第一名亦是靠 ensemble 获得。
不使用 Distilling (Ensemble probs as labels)、 Ensemble,论坛上其他 team 报出的单模型准确率在 0.86 左右。
data argument
[4] Jaitly N, Hinton G E. Vocal tract length perturbation (VTLP) improves speech recognition[C]//Proc. ICML Workshop on Deep Learning for Audio, Speech and Language. 2013, 117.
[5] Ko T, Peddinti V, Povey D, et al. Audio augmentation for speech recognition[C]//Sixteenth Annual Conference of the International Speech Communication Association. 2015.
- tried changing speed / pitch, but got a little achievement.
总结:
- resnet / densenet 获得的 绝对 > 10 % Accuracy 提升,让我感受到了语音届的相对保守,尽管语音届在 2016 年就眼红 ConvNets 在计算机视觉的突飞猛进[6, 7, ...],当然 ASR 也不是简单的分类任务;
- TensoFlow 带来的生产力,实现 resnet / densenet / mibilenet 都没有花太多时间,读完文章 1 - 2 两小时就能写个初始版本(后续调优,仍需仔细读文章核对细节);
- ensemble 仍然是 Kaggle 比赛的银弹;
- keyword spotting 的典型玩法 [8, 9, ...] 探索不足,最后一天的时间从零写了个 CTC - keyword spotting 系统,看了下统计的 score,基本不靠谱。。
[6] Xiong W, Droppo J, Huang X, et al. Achieving human parity in conversational speech recognition[J]. arXiv preprint arXiv:1610.05256, 2016.
[7] Yu D, Li J. Recent progresses in deep learning based acoustic models[J]. IEEE/CAA Journal of Automatica Sinica, 2017, 4(3): 396-409.
[8] Lengerich C, Hannun A. An end-to-end architecture for keyword spotting and voice activity detection[J]. arXiv preprint arXiv:1611.09405, 2016.
[9] He Y, Prabhavalkar R, Rao K, et al. Streaming Small-Footprint Keyword Spotting using Sequence-to-Sequence Models[J]. arXiv preprint arXiv:1710.09617, 2017.
