深度学习对话系统理论篇--seq2seq+Attention机制模型详解

上一篇文章已经介绍了几篇关于Seq-to-Seq模型的论文和应用,这里就主要从具体的模型细节、公式推导、结构图以及变形等几个方向详细介绍一下Seq-to-Seq模型。这里我们主要从下面几个层次来进行介绍:
- Seq-to-Seq框架1
- Seq-to-Seq框架2
- Seq-to-Seq with Attention(NMT)
- Seq-to-Seq with Attention各种变形
- Seq-to-Seq with Beam-Search
Seq-to-Seq框架1
第一个要介绍的Seq-to-Seq模型来自“Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation”这篇论文,其结构图如下所示:

特点是Encoder阶段将整个source序列编码成一个固定维度的向量C(也就是RNN最终的隐藏状态hT),C = f(x1, x2,...,xT),f就是各种RNN模型。并认为C中保存了source序列的信息,将其传入Decoder阶段即可,在每次进行decode时,仍然使用RNN神经元进行处理(下面公式中的f函数),不过输入包括前一时刻输出yt-1、前一时刻隐层状态ht-1、输入编码向量C三个向量,也就是解码时同时会考虑前一时刻的输出和source序列两方面的信息,如下图所示。

有了ht之后在计算该时刻的输出值yt,这里计算一个条件概率分布,计算出当前情况下target vocab中每个词所对应的概率,这里往往需要一个额外的Projection层,因为RNN的输出维度与vocab维度不同,所以需要经过一个矩阵进行映射(后面介绍代码的时候会讲到)。yt的计算会使用ht、yt-1、C三个向量。g函数往往是一个softmax函数,用于计算归一化的概率值。

Seq-to-Seq框架2
第二个要讲的Seq-to-Seq模型来自于“Sequence to Sequence Learning with Neural Networks”,其模型结构图如下所示:


与上面模型最大的区别在于其source编码后的向量C直接作为Decoder阶段RNN的初始化state,而不是在每次decode时都作为RNN cell的输入。此外,decode时RNN的输入是目标值,而不是前一时刻的输出。首先看一下编码阶段:

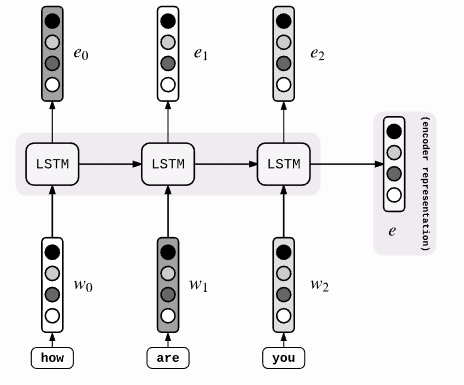
就是简单的RNN模型,每个词经过RNN之后都会编码为hidden state(e0,e1,e2),并且source序列的编码向量e就是最终的hidden state e2。接下来再看一下解码阶段:


e向量仅作为RNN的初始化状态传入decode模型。接下来就是标准的循环神经网络,每一时刻输入都是前一时刻的正确label。直到最终输入<eos>符号截止滚动。
Seq-to-Seq with Attention(NMT)
第三个要讲的是Attention based Seq-to-Seq模型,来自于“Neural Machine Translation by Jointly Learning to Align and Translate”这篇论文,模型框架如下图所示:

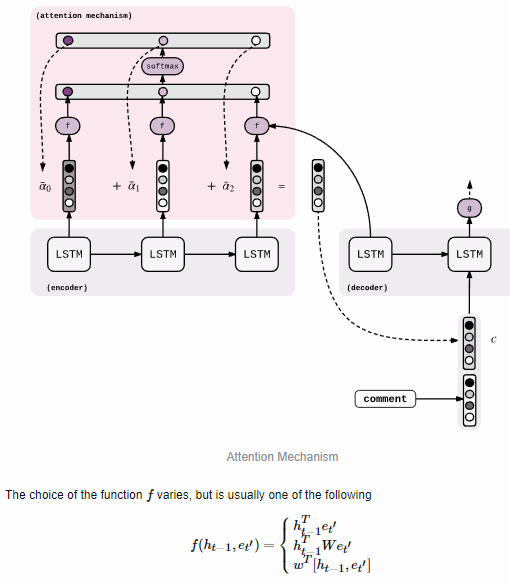
前面两个模型都是将source序列编码成一个固定维度的向量,但是这样做对于长序列将会丢失很多信息导致效果不好,所以作者提出将encoder阶段所有的隐层状态保存在一个列表当中,然后接下来decode的时候,根据前一时刻状态st-1去计算T个隐层状态与其相关程度,在进行加权求和得到编码信息ci,也就是说每个解码时刻的c向量都是不一样的,会根据target与source之间的相关程度进行权重调整和计算。编码过程就不再赘述了,主要看一下解码过程的流程:
1,计算h1~hT各个隐层向量与st-1之间的相关程度,并进行softmax归一化操作得到每个隐层向量的权重aij:


eij就表示第i个target与第j个隐层向量hj之间的相关性,可以通过一个MLP神经网络进行计算,在上面示意图中没有显示出来。得到eij之后,将其传入softmax函数我们就可以获得归一化的权重值aij。
2,对h1~hT进行加权求和得到此次解码所对应的source编码的向量ci:

到这里我们可以参考下图进行理解(其实这里有一点不同,因为下面这个图并未引入st-1这个向量,而是仅考虑了h1~hT),从图中可以看出T个隐层向量经过左上角的MLP+softmax神经网络之后就变成了T个权重值,然后对T个向量按照该权重值进行加权求和即可得到Ci:

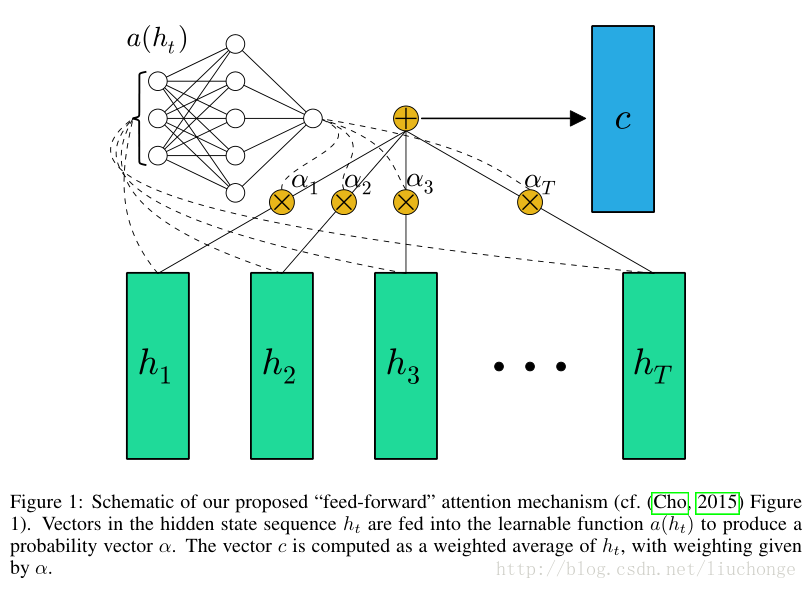
针对这个模型我们也可以参考下图进行理解,每个aij都是用zi和hj之间计算得到的,这个图是分开来讲每个向量之间的计算,而上面那个图是将其整体作为一个矩阵进行考虑,直接传入MLP神经网络即可。


3,有了ci之后,就和前面两个Seq-to-Seq模型一样了,我们根据ci进行解码即可,同样是先计算st,在计算yt,两个公式如下所示:


这里的Attention机制采用的是Soft Attentin(也就是对所有的h向量都有分配权重),可以将其理解为对齐模型,作用是匹配target与source之间的对应关系。从这个角度上来讲aij可以理解为yi是由xj翻译过来的概率。所以这个权重值可以很好的对模型进行可视化,以了解模型工作的机理和效果。
Seq-to-Seq with Attention各种变形
这是我们要介绍的第四个Seq-to-Seq模型,来自于论文“Effective Approaches to Attention-based Neural Machine Translation”,目前引用量530+。这篇论文提出了两种Seq-to-Seq模型分别是global Attention和local Attention,下面分别进行介绍:
1,global Attention,这种模型跟上面的思路差不多,也是采用soft Attention的机制,对上面模型进行了稍微的修改,模型结构图如下所示:
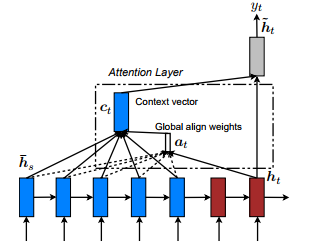
从上图可以看出,原理上与NMT区别不大,只是aij计算方法稍有区别,这里的score函数从上面的神经网络变成了下面三种选择,包括内积、general、concat。结果表明general效果比较好。如下图所示:


为了显示出aij的计算细节,我们可以参考下图进行理解,其中的f函数就是上面提到的score评分函数:

因为与NMT模型差别很小,所以不在扩展介绍。下面看看local Attention。
2,local Attention,目前存在两种Attention方式soft Attention和hard Attention。上面提到的global模型属于soft Attention,这种方法的缺点是每次decode时都要计算所有的向量,导致计算复杂度较高,而且很容易可以想到,其实有些source跟本次decode根本没有任何关系,所以计算他们之间的相似度有些多余;除此之外,当source序列较长时,这种方法的效果也会有所下降。而hard Attention,每次仅选择一个相关的source进行计算,这种方法的缺点是不可微,没有办法进行反向传播,只能借助强化学习等手段进行训练。这部分内容可以参考论文“Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”。所以为了融合两种方法,作者提出了一种local Attention的机制,每次只选择一部分source进行计算。这样既可以减少计算量,又可微,效果也更好。接下来看一下其原理:

思路就是先根据st找到source中所对应的窗口中心位置,然后取出该窗口内的source所对应的h隐层向量,在进行求aij并加权求和得到ci向量。这个过程中最重要的就是如何确定st所对应的source的中心位置,论文中提出了两种方法:
- monotonic alignment:直接选择source序列中的第t个作为中心pt,然后向两侧取窗口大小个词;
- predictive alignment:使用下面的公式决定pt值的大小,将ht经过一个激活函数tanh和sigmod两个函数之后变成0~1,再乘以S(source序列长度)就变成0~S,也就是我们想要的原序列所对应的中心位置pt,取出窗口大小个隐层,在进行加权求和。这里权重乘以了一个高斯分布,目的是让靠近中心pt的词的权重更大一点,让aij形成一种钟型分布,如下图所示,原本的aij再乘以高斯分布之后,相应的aij值发生变化,导致靠近中心的aij增加,两侧的减小。






3,为了让模型能够学习到更多的信息,作者又提出Input-feeding的方法,也就是将计算出的ht传递到下一时刻的输入中,如下图所示:

Seq-to-Seq with Beam-Search
上面讲的几种Seq-to-Seq模型都是从模型结构上进行的改进,也就说为了从训练的层面上改善模型的效果,但这里要介绍的beam-search是在测试的时候才用到的技术。我们先来说一下一般的方法,也就是greedy search,在进行解码的时候,每一步都选择概率最大的那个词作为输出,然后再将这个词作为下一解码时刻的输入传递进去。以此类推,直到输出<EOS>符号为止,我们最终会获得一个概率最大的序列当做是解码的输出。但是这么做的缺点就是,某一步的错误输出可能会导致后面整个输出序列都发生错误,那么改进的方案就是beam-search,思路也很简单,就是每次都选择概率最大的k个词(beam size)作为输出,并在下一时刻传入RNN进行解码,以此类推。
举个例子来说明一下,假设我们翻译时的vocab就是A,B,C三个单词,beam size取2,。然后第一次解码时对应概率分别是[0.2,0.5,0.3],于是我们就选择概率最大的两个B,C作为候选分别传入下一个解码时刻,B的输出概率分别是[0.7, 0.2, 0.1],C的输出概率分别是[0.3, 0.5, 0.2],仍然分别去概率最大的两个输出,于是我们得到下面四个序列:BA:0.5*0.7=0.35, BB:0.5*0.2=0.1, CB:0.3*0.5=0.15, CA:0.3*0.3=0.09,取概率最大的两个序列就是BA和CB。再继续做下一步。。。接下来每次都会生成K^2个序列,取概率最大的K个最为候选进行下一轮解码输入即可。
这样做的好处是可以通过增加搜索范围来保证一定的正确率。比如说我们最终得到两个序列ABCCBA和BACBC,虽然第一个步骤中A的概率大于B,但最终BACBC的概率比ABCCBA要大,于是BACBC就作为最终输出序列而且也恰恰是正确答案。参考文献2中提到,beam size等于2时效果就已经不错了,到10以上就不会再有很大提升。
参考文献和博客
1. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
2. Sequence to Sequence Learning with Neural Networks
3. Neural Machine Translation by Jointly Learning to Align and Translate
4. Grammar as a Foreign Language
5. On Using Very Large Target Vocabulary for Neural Machine Translation
6.A Neural Conversational Model
7. Effective Approaches to Attention-based Neural Machine Translation
8. Addressing the Rare Word Problem in Neural Machine Translation
9. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
10. Seq2Seq with Attention and Beam Search
11. NLP 笔记 - Neural Machine Translation
12. 神经网络机器翻译Neural Machine Translation(2): Attention Mechanism
