时间序列多步预测的五种策略

通常,时间序列预测描述了预测下一个时间步长的观测值。这被称为“一步预测”,因为仅要预测一个时间步。在一些时间序列问题中,必须预测多个时间步长。与单步预测相比,这些称为多步时间序列预测问题。例如,给定最近7天观察到的温度:
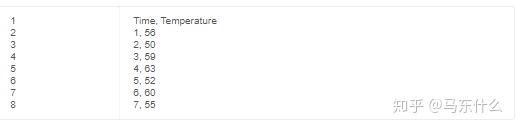
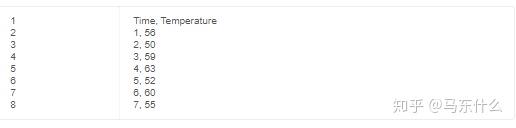
单步预测仅需要在时间步骤8进行预测。
多步骤可能需要在接下来的两天内进行预测,如下所示:


在开始之前,需要明确一些一直很模糊的问题,也就是时间序列预测的数据形式,我们平常在公众号或者百度的一些blog里看到的时间序列预测的数据形式都很简单,并且基本都是单个序列,单变量的序列问题,比如说我们要预测某一个商品的未来销量,举个例子:
nike的XXX款鞋子,其销量序列数据[100,200,150,300,200].......
这类问题算是最初进入大众视野的时间序列问题的形式,arima,fbprophet之类的都是针对这类问题的,但是我们在业务上碰到的问题基本上是成百上千的序列,比如:
nike的XXX款鞋子,其销量序列数据[100,200,150,300,200].......
nike的XXX款袜子,其销量序列数据[100,200,150,300,200].......
nike的XXX款衣服,其销量序列数据[100,200,150,300,200].......
当然我们也可以每一款商品单独用arima之类的方法来建模,理论上可以,但是实际上基本不可能,一方面维护成千上万的模型的成本是不可估计的,一方面不同商品的序列长度差异很大,有的序列长度可能非常完整有1500+个序列数据,有的冷门商品或者是新上的商品序列长度很短可能只有不到10个,这种情况下,后者基本没法单独建模。
因此实际上我们常见的业务问题的数据形式是这样的:
商品 日期 销量序列数据
nike的XXX款衣服 2020-01-01 100
nike的XXX款衣服 2020-01-02 200
nike的XXX款衣服 2020-01-03 150
nike的XXX款衣服 2020-01-04 250
nike的XXX款袜子 2020-03-01 100
nike的XXX款袜子 2020-03-02 300
nike的XXX款袜子 2020-03-03 250
nike的XXX款袜子 2020-03-04 350
这也是web traffic,m5 forecast,favorite store 这些序列比赛的数据的普遍形式,可以说我们面对的主要的问题形式是这样的。
进行建模的时候我们面临最直接的问题就是,你用多少的时间步的历史数据预测未来多少个时间步的未来数据,即 时间窗的问题,比如我们就用前一天的数据预测后一天的,那么数据就要变成:
商品 日期 过去一天销量 销量序列数据
nike的XXX款衣服 2020-01-01 nan 100
nike的XXX款衣服 2020-01-02 100 200
nike的XXX款衣服 2020-01-03 200 150
nike的XXX款衣服 2020-01-04 ... 250
nike的XXX款袜子 2020-03-01 100
nike的XXX款袜子 2020-03-02 300
nike的XXX款袜子 2020-03-03 250
nike的XXX款袜子 2020-03-04 350
这就是我们的所谓的滞后特征,也是时间序列问题中最常见的也是最重要的特征衍生方法,废话,你不用历史数据预测未来,难道用静态数据(商品,店铺,城市之类的)来预测销量??
一般来说,时间距离约接近的滞后特征对于预测的准确的贡献越大。所以我们会用所谓的窗口的问题,比如你使用 1阶滞后 2阶滞后。。。n阶滞后来预测未来,则你的时间窗的长度为n,当然这个时间窗不一定连续,你可以使用1阶滞后,3阶滞后,7阶滞后。。。。n阶滞后等,但是你的时间窗长度仍旧为n,只不过滞后特征的数量变少了而已。
除此之外,还有一个地方就是gap的问题,也就是提前多少天预测,实际的应用的时候,很多时候除了多步预测之外,还需要你做提前预测,也就是你可能要提前几天的时间进行预测,例如你需要在11月1日预测11月11日,则就是提前10天做预测,那么进行特征构建的时候也需要注意,滞后特征要从10天前开始做起。
为了便于描述,这里假设一个序列:
[1,2,3,4,5,6,7,8,9,10,X,Y,Z]
我们要做的是预测未来的3个时间点,X,Y,Z的序列的值,并且为了方便描述,这里我们统一仅仅使用1阶滞后特征
第一种:直接多步预测:
直接多步预测的本指还是单步预测,
多步转单步,比如上面我们要预测3个时间点的序列的值,则,我们就构建3个模型,
model1:[1,2,3,4,5,6,7,8,9],[X]
model2:[1,2,3,4,5,6,7,8,9],[Y]
model3:[1,2,3,4,5,6,7,8,9],[Z]
这种做法的问题是如果我们要预测N个时间步,则复杂度很高,比如预测未来100天,则意味着我们要构建100个模型;
另外需要注意的是,在使用这种方法的时候,我们在进行特征工程的时候要比较小心,因为我们在序列问题的特征工程过程中常常会涉及到一些lag方法,即滞后特征的引入,比如对于:
model1:[1,2,3,4,5,6,7,8,9],[X]
我们可以构建一阶滞后特征
[1,2,3,4,5,6,7,8,9],[nan,1,2,3,4,5,6,7,8],而待预测的X的一阶滞后是9,是我们已经观测到的值,因此取1阶滞后没有问题(当然这里涉及到很多特征衍生的方法,还有rolling这类的特征衍生也是要注意这类的问题)
但是对于:
model2:[1,2,3,4,5,6,7,8,9],[Y] 我们无法使用1阶滞后,因为Y的一阶滞后是X,X并不是我们的观测值,这个时候我们的滞后特征只能从二阶滞后开始做起
对于后续的model3,model4.。。。等等,基本是一样的道理
这里我们仅仅使用了1阶滞后,所以时间窗长度是 1。
另外需要注意的是,时间窗的长度和我们处理无序的结构化问题有一些区别,我们直观的感受是,长度的概念对应的是样本的数量,但是实际上在结构化数据中,对应的是特征的维度,比如
lag-3 lag-2 lag-1 label
1 2 3 4
2 3 4 5
3 4 5 6
这就是滑动窗口的概念,
当我们使用n阶滞后特征训练了一个模型之后,我们可以称这个模型为n阶滞后模型。
直接预测方法的缺点在于可能会出现较高的方差,特别是如果我们要预测的时间步长比较长的情况下,比如我们要预测未来100个时间步骤,则第100个时间步骤使用的最近的一样观测样本是100个时间步之前的,我们直到,周期约接近当前时间点的滞后特征预测效果越好,间隔时间越长效果越差。
第二种:递归多步预测:
递归多步预测,递归多步预测的本质还是简单的单步预测,但是和第一种情况不同,递归多步预测不需要预测 时间步个模型,仅仅一个模型就够了。举个例子,假设我们构建了一个3阶滞后模型:
lag(t-3) lag(t-2) lag(t-1) t
1 2 3 4
2 3 4 5
...
则当我们预测的时候,还是以上面的例子为例:
[1,2,3,4,5,6,7,8,9,10,X,Y,Z]
我们先预测X,即根据:
用model 去 predict([8,9,10]) 得到 prediction(X),假设predict出来的结构为11.24,然后我们把预测值当作特征,得到[9,10,11.24],然后用model去predict([9,10,11.24])得到prediction(y)。。。。依此类推。
由于使用预测代替真实值,因此递归策略会累积预测误差,即递归策略的偏差比较大,从而随着预测时间范围的增加,模型的性能可能会迅速下降。
3、直接+递归的混合策略
可以将直接策略和递归策略结合使用,以提供这两种方法的好处。
例如,可以为要预测的每个时间步构建一个单独的模型,但是每个模型都可以将模型在先前的时间步进行的预测用作输入值。
令我感到惊讶的是,这种偏工程的方法居然还有专门的论文描述其好处:




这也是M5 forecast的top1 solution的winner使用的策略。
思路也不复杂,和直接预测一样我们要根据n个时间步构造n个模型,还是以原来的例子为例:[1,2,3,4,5,6,7,8,9,10,X,Y,Z]
我们先构造一个3阶滞后的model 1:[8,9,10][X],然后用model1 进行预测得到prediction(X),然后我们构造model2 ,按照直接预测法的思路,
model2应该是无法将X作为观测样本进行训练,因此model2可以是[8,9,10][Y],当然,使用直接预测法不一定要构造相同的n阶模型,也可以是[7,8,9,10][Y]。。。。依此类推,但是核心都是无法使用X处的数据,因为X是未知的没有观测到的值,
那么混合策略的做法是,我们用model1预测X得到prediction(X),然后将这个prediction(X)作为model2的”观测“数据,纳入模型训练,即:
model2:[9,10,model1.prediction(X)][Y],然后
model3:[10,model1.prediction(X),model2.prediction(Y)][Z]
。。。。依此类推。
为什么会有上述三种策略呢?本质原因是传统的机器学习算法无法正常处理多输出问题,多步预测的本指是多输出,我们需要多输出模型才能在一个模型里预测多个标签,比如 预测未来的3步是一个3输出模型,这个概念就类似于我们的多标签分类、多标签回归的概念。实际上针对于直接预测法,就是一种常见的使用传统的机器学习算法解决多标签问题的转化方法,而递归预测法本质上还是普通的简单的单标签问题。
但是深度学习可以很容易的打破这样的限制,这里介绍第四种策略:
多输出策略:
注意,直接进行多输出,则model的形式是:
model 多输出:[8,9,10][X,Y,Z]
传统的机器学习算法包括lr gbdt无法直接构建多输出模型而要借助于直接预测、递归预测或者混合策略,但是神经网络可以打破这样的限制,nn可以非常灵活的支持多输入或者多输出的形式。
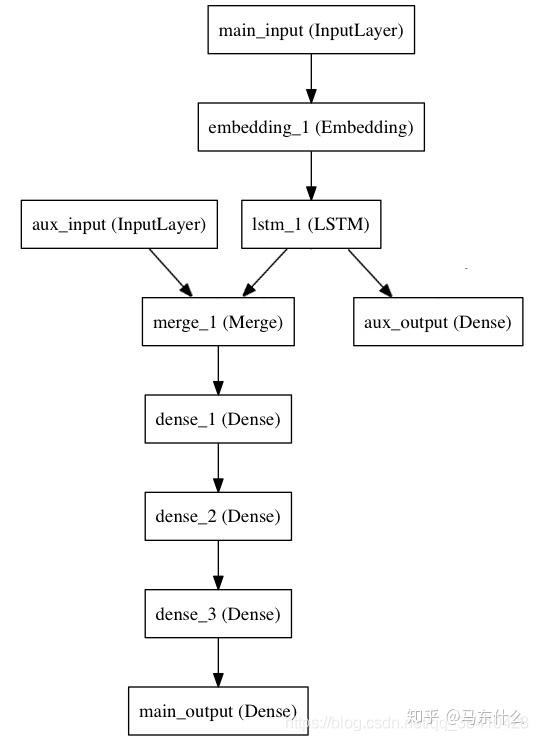
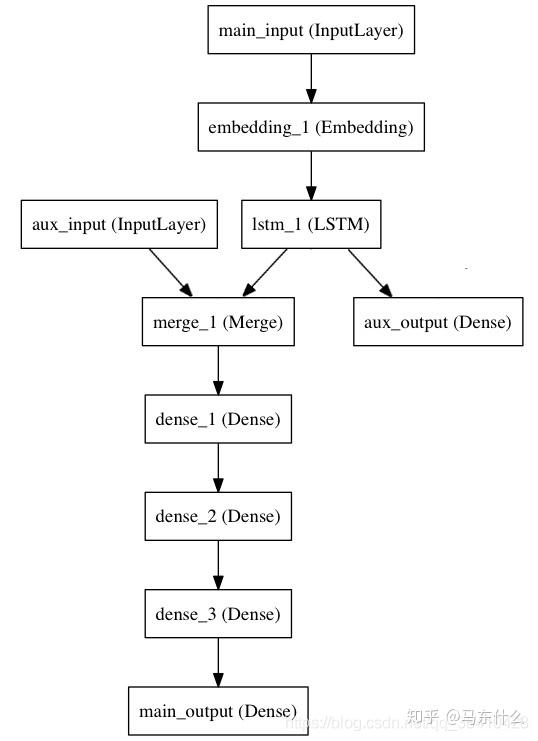
我们只需要把这里的main_output的Dense层的神经元个数设置为 n就可以(n是要预测的未来的时间的步数)
这是常见的使用nn进行多步预测的网络设计,特点就只是输出层的nn根据预测的时间步数进行设置而已。
有没有发现和序列标注问题的形式非常类似?早期使用nn来处理序列标注(序列标注问题是一个多分类问题),简单直观的思路就是输出接一个n分类层。
这种方法的问题就是,我们的标签如果是时序依赖的,比如时间序列预测未来3个时间步骤t+1,t+2,t+3,如果我们直接使用多输出的方式,则 t+1,t+2,t+3 三个标签我们其实是认为它们是完全独立的,但是实际上它们是存在序列依赖性的,这个问题和序列标注早期的简单方法存在的问题是一样的,就是没有考虑标签的序列依赖的性质。因此就诞生了第五种策略,也是基于深度学习的方法。
第五种策略:seq2seq结构
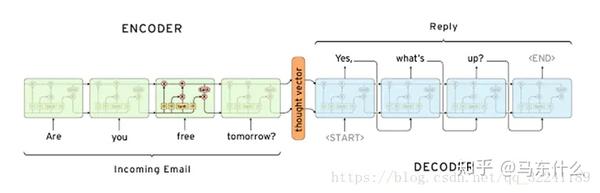
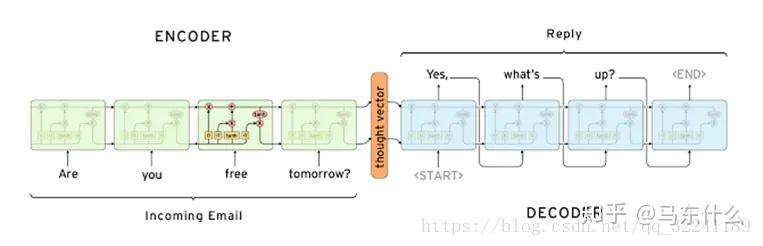
这是一个常见的问答系统的seq2seq结构,以上面的例子为例:
[1,2,3,4,5,6,7,8,9,10][X,Y,Z],我们可以直接构造上述seq2seq结构的输入输出样本,假设我们使用3阶滞后,预测未来的3个时间步,则样本构造为:
input output
[1,2,3][4,5,6]
[2,3,4],[5,6,7]
[3,4,5],[6,7,8]
.....
[8,9,10],[X,Y,Z]
在seq2seq的结构中,我们使用LSTM或者CNN的网络结构作为encoder和decoder的组件即可,这种情况下,当然,attention+seq2seq,transformer,bert等网络结构都可以直接处理这样的问题。
并且,他们都可以考虑输出的标签之间的序列依赖性。
这也是web traffic冠军采用的模型结构。
