迁移学习实战猫狗大战

Go Deeper.
今天让我们总结一下迁移学习的相关知识点,并使用Kaggle上的 “猫狗大战” 为例进行实战,完成三个实验。
0. 模型的训练与预测
- 深度学习的模型可以划分为 训练 和 预测 两个阶段。
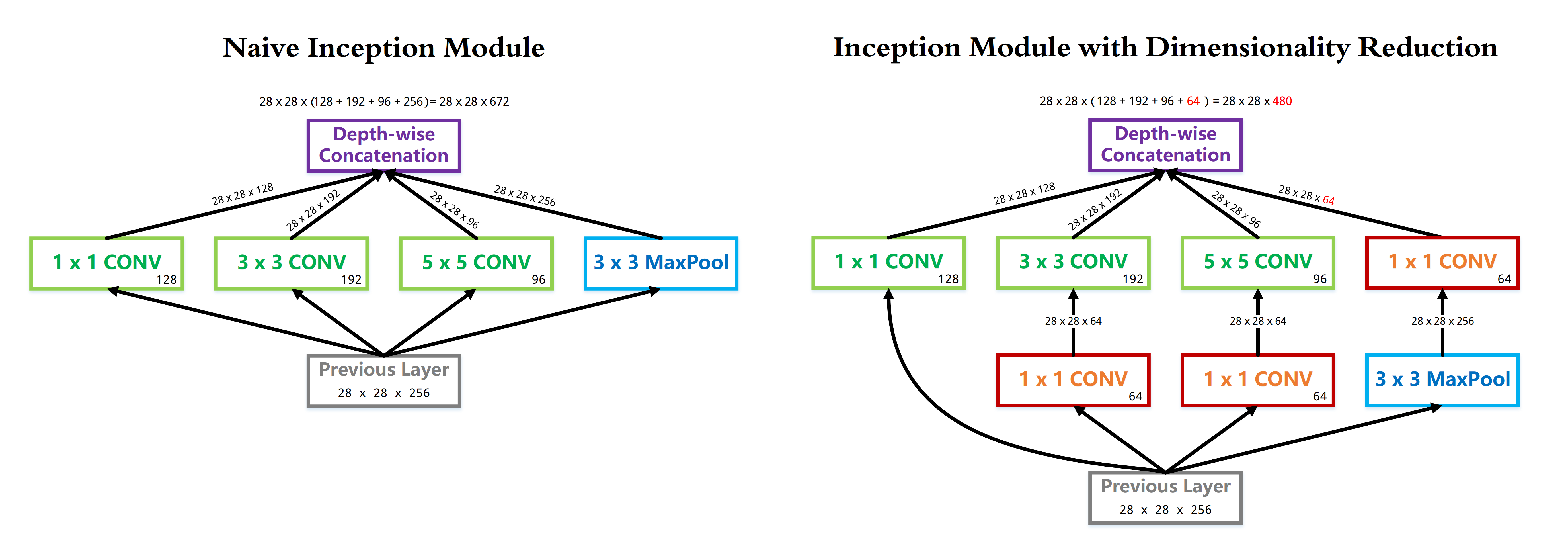
- 训练 分为两种策略:一种是白手起家从头搭建模型进行训练,一种是通过预训练模型进行训练。今天咱们讨论的就是后者,具体可以再细分为三种操作方式。(见下图)
- 预测 相对简单,直接用已经训练好的模型对数据集进行预测即可。
\textbf{Model} \begin{cases} \textbf{Training} \begin{cases} \color{Blue}{\textbf{Training From Scratch}} \\[2ex] \color{Green}{\textbf{Using Pre-trained Model}} \begin{cases} ^{\#} \textrm{1. Transfer Learning} \\[2ex] ^{\#} \textrm{2. Extract Feature Vector} \\[2ex] ^{\#} \textrm{3. Fine-tune} \end{cases} \end{cases} \\[3ex] \textbf{Inference}: \textrm{Using Pre-trained Model} \end{cases}
1. 为什么要迁移学习
- 站在巨人的肩膀上:前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要强悍,没有必要重复造轮子。
- 训练成本可以很低:后面可以看到,如果采用导出特征向量的方法进行迁移学习,后期的训练成本非常低,用 CPU 都完全无压力,没有深度学习机器也可以做。
- 适用于小数据集:对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠迁移学习。
2. 迁移学习有几种方式


- 1. Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
- 2. Extract Feature Vector:先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
- 3. Fine-tune:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
其实 "Transfer Learning" 和 "Fine-tune" 并没有严格的区分,含义可以相互交换,只不过后者似乎更常用于形容迁移学习的后期微调中。
* 注:配图改编自CS231n。
3. 三种迁移学习方式的对比
- 第一种和第二种训练得到的模型本质上并没有什么区别,但是第二种的计算复杂度要远远优于第一种。
- 第三种是对前两种方法的补充,以进一步提升模型性能。要注意的是,这种方法并不一定能真的对模型有所提升。
- 本质上来讲,这三种迁移学习的方式都是为了让预训练模型能够胜任新数据集的识别工作,能够让预训练模型原本的特征提取能力得到充分的释放和利用。但是,在此基础上如果想让模型能够达到更低的Loss,那么光靠迁移学习是不够的,靠的更多的还是模型的结构以及新数据集的丰富程度。
开始实战
下面我就基于猫狗大战的数据,分别实现上面讲到的这三种迁移学习的方法。
具体代码详见我的 Github: Dog VS Cat - Experimenting With Transfer Learning
\quad\qquad\qquad\qquad\qquad\qquad\qquad\color{red}{\textbf{Ready?}} ~ \color{Green}{\textbf{Go! }}
实验一:冻结全部卷积层 + 训练自己定制的全连接层
- 使用InceptionV3预训练模型:该模型当初用ImageNet数据集训练时的输入图像尺寸是299x299,且图像通道顺序为RGB。需要注意的是,使用预训练模型一定要确保让待训练的数据尽可能向原数据集靠拢,这样才能最大程度发挥模型的识图本领。
- 预处理:按照预训练模型原本的预处理方式对数据进行预处理,在这里是归一化至[-1,1]
- 基模型:导入预训练模型(只导入卷积层部分),并锁定全部卷积层参数。
- 定制模型:卷积层之后先接全局平均池化(GAP),再接Dropout,再接分类器,根据分类任务选择输出个数。模型可训练参数只有两千个。
- 优化器:采用较小学习率的SGD。
- 数据准备:将训练集划分为训练集和验证集。
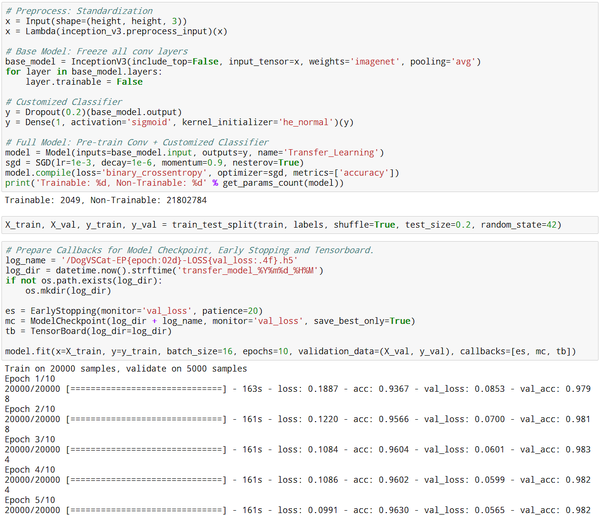
- 定义回调函数以方便训练:自动在每代结束保存模型,以val_loss作为监控指标进行早停,训练历史数据同步更新到Tensorboard供可视化。
- Batch Size:要用较小的batch size进行训练,这样可以让模型更快更好的收敛。
- 可以看到,虽然卷积层全都已经锁定,但是由于样本依然需要从模型的输入一直计算到输出,因此训练还是比较耗时的。训练五代需要十几分钟,验证集Loss在0.05左右。
(个人感觉知乎代码阅读效果不佳,这里就直接放截图了,代码请见Github)

实验二:导出特征向量,再单独训练分类器
- 预处理:导出训练集和测试集的特征向量之前,一定要记得按照预训练模型的要求进行预处理,否则导出的特征将不是模型的最佳表现。
- 基模型:基模型同样由InceptionV3的卷积层部分以及全局平均池化(GAP)构成。
- 导出即预测:所谓导出,其实就是让基模型直接对训练集和测试集进行预测,只不过预测出的结果不是图像类别,而是特征向量(特征图的浓缩版本)。
- 导出需要一定时间:由于导出需要对数据集的所有图片进行预测,因此通常需要一两分钟才能完成。好的是,一旦完成,就可以完全和CNN的耗时训练拜拜了。
- 新模型的输入是特征向量:新模型的输入不再是训练集的图像本身,而是经过预训练模型“消化”后的图像特征向量,该向量的第一个维度对应于每一个图像样本,其长度为样本的个数,第二个维度是基模型最后一层每个卷积核输出特征图的平均值,对于InceptionV3来说,第二个维度的长度是2048。
- 划分训练集和验证集:注意这里是对输入的特征向量划分训练集和验证集。
- 定制新模型:由于已经导出特征向量,因此接下来只需训练一个输入特征长度为2048的全连接网络即可。
- 同样采用回调函数以及很小的batch_size(16)进行训练。
- 训练快到飞起。五代训练仅用时十几秒钟,就可以在验证集上达到0.02左右的Loss。
- 此时模型已经基本可以跻身于 Kaggle Leaderboard 的 Top20。如果进一步融合ResNet50, Xception 等模型,则可以达到 Top10。


实验三:尝试对模型进行微调,以进一步提升模型性能
1. Fine-tune 所扮演的角色
- 拿到新数据集,想要用预训练模型处理的时候,通常都会先用上面实验一或者实验二里的方法看看预训练模型在新数据上的表现怎么样,摸个底。如果表现不错,还想看看能不能进一步提升,就可以试试Fine-tune,进一步解锁卷积层以继续训练模型。
- 但是不要期待会有什么质的飞跃。
- 另外,如果由于新数据集与原数据集(例如ImageNet数据集)的差别太大导致表现很糟,那么一方面可以考虑自己从头训练模型,另一方面也可以考虑解锁比较多层的训练,亦或干脆只用预训练模型的参数作为初始值,对模型进行完整训练。
2. Fine-tune 也可以有三种操作方式
其实基本思路都是一样的,就是解锁少数卷积层继续对模型进行训练。
- 场景1:已经采用实验一里的方法,带着冻僵的卷积层训练好分类器了。
- 如何做:接着用实验一里的模型,再解锁一小部分卷积层接着训练就好了。
- 场景2:已经采用实验二里的方法,把分类器训练好了,现在想要进一步提升模型。
- 如何做:重新搭一个预训练模型接新分类器,然后把实验二里训练好的分类器参数载入到新分类器里,解锁一小部分卷积层接着训练。
- 场景3:刚上手,想要 Transfer Learning + Fine-tune 一气呵成。
- 如何做:和实验一里的操作一样,唯一不同的就是只冻僵一部分卷积层训练。需要注意的是,这么做需要搭配很低的学习率,因此收敛可能会很慢。
3. 具体实现
由于实验二的得到的模型性能好于实验一,因此下面我们接着实验二的脚步进一步对模型进行Fine-tune(即上面所说的场景2)。
- 基模型和定制模型:构建和实验一里面完全相同的模型。要注意的是得把Dense层的名字定义的和实验二中一样(都叫'classifier')。
- 导入分类器的参数:由于实验二中已经将分类器(即Dense层)训练好了,因此这里只需要by_name的load_weight就可以让刚搭的模型满血复活了。
- 通过evaluate函数查看模型状态:载入权重之前,模型的预测准确率很低,跟瞎猜(50%)差不多。载入之后,准确率直接飙升到99%,说明权重载入的过程没有问题。


4. 关于如何选取要解锁的区域
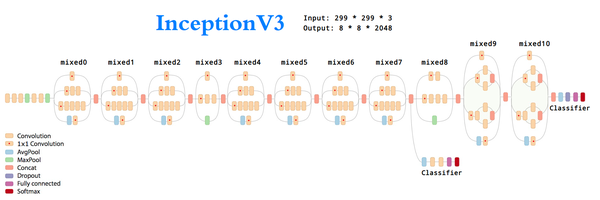

- 由于InceptionV3模型是按照一个一个的Inception Module级联起来的,因此我们要选择Fine-tune的话,最好也以Inception Module为最小单位(而不是单独的某一层)进行锁定和解锁。(具体可以看我画的题图放大版结构)
- 通过看 model_finetune.summary() 可以基本确定上图中的 mixed10 区域(倒数34层)构成的 Inception Module 可以解锁训练下。
- 比较遗憾的是,经过多次尝试,Fine-tune出来的模型性能都不太好,Loss最低只能到0.05左右,比实验二得到的0.02还要差一些。


疑问
- 为什么使用特征向量迁移学习的模型(实验二)会始终好过带着卷积层训练(实验一)及微调(实验三)的方式呢?
- 我目前的理解是因为前者的模型简单,因此搭配猫狗的数据集可以更好的拟合,后者网络庞大,在非常高的维度进行梯度下降,收敛将十分缓慢。不知道是否正确。另外一种可能是Keras本身的问题,计划有空的时候用其他框架验证下。
附录
- 我的实验代码:Dog VS Cat - Experimenting With Transfer Learning
- 参考了 @杨培文 培神的猫狗大战:ypwhs/dogs_vs_cats
- 题图改编自CS231n ^_^
编辑于 2017-10-15 22:49
