
迈向通用人工智能:星际争霸2人工智能研究环境SC2LE完全入门指南

题图来源:http://www.neogaf.com/forum/showthread.php?t=1401417&amp;amp;amp;page=1
版权说明:本文为原创文章,未经作者允许不得转载。
注:本篇完全入门指南,相比于Flood Sung和杜客两位大神合作的SC2LE初体验专栏文章,可以看作是延伸,尤其是对PySC2实现、程序接口进行了深入分析,并对自定义代理的实现、增强学习的应用进行了一些初步的讨论。
1. 导言
近日,DeepMind联合暴雪娱乐共同发布了星际争霸2人工智能研究环境SC2LE(StarCraft II Learning Environment)。国内多个渠道都在第一时间对官方博客DeepMind and Blizzard open StarCraft II as an AI research environment进行了译载。正如DeepMind自己所言,DeepMind的科学使命是通过开发能够学习解决复杂问题的系统,来进一步推动AI发展的边界。此次发布,为业界提供了一套成熟的、开放的AI决策系统测试平台。在人工智能研究社区,尤其是在增强学习社区,无疑是引爆了一颗重磅炸弹。紧接着,在前两天举办的Dota2国际邀请赛(TI7)中,OpenAI开发的AI完胜世界顶级选手Dendi,让人大吃一惊。由此可见,两大AI巨头都将这类即时策略游戏作为迈向通用人工智能的必经之路。
本文作为SC2LE完全入门指南,将从SC2LE基本组成及功能、环境安装、PySC2初探、PySC2详解等四个方面展开,尤其是对PySC2实现、程序接口进行深入分析,并对自定义代理的实现、增强学习的应用进行了一些初步的讨论。
本次发布的SC2LE主要包括5个部分:
- 暴雪开发的机器学习API,其中包括了脚本API接口和基于图像的API接口(通过特征层的方式)。GitHub地址:https://github.com/Blizzard/s2client-proto
- 匿名的游戏回放数据集,在接下来的几周中将从65k增加到超过500k。GitHub地址:https://github.com/Blizzard/s2client-proto#replay-packs
- DeepMind开发的开源Python工具PySC2,允许研究者们在代理(agent)中方便使用暴雪的特征层API。GitHub地址:https://github.com/deepmind/pysc2
- 一系列简单的增强学习小游戏,允许研究者们在特定任务(如采矿)中测试代理的性能。GitHub地址:https://github.com/deepmind/pysc2/releases/download/v1.0/mini_games.zip
- 一篇对应的论文StarCraft II: A New Challenge for Reinforcement Learning,概述了这个环境,同时也记录了一些与游戏内置AI对抗的初步基准结果,包括在采矿等特定任务、从回放中监督学习以及完全的1对1天梯局中等一系列表现。
除去论文,其他4个部分的关系可以用下图表示
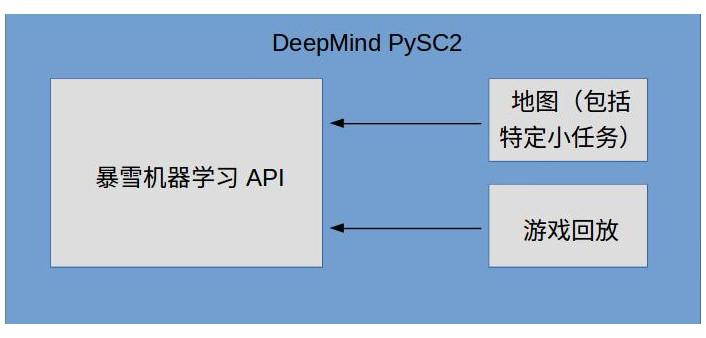
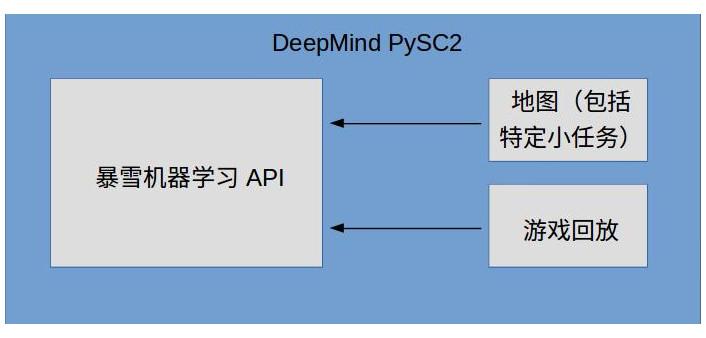
其中,机器学习API作为底层接口,可以和地图、游戏回放结合使用,DeepMind在此基础上开发了PySC2工具包。
2. SC2LE安装
基于4个部分的相对关系,我们将按照机器学习API-->地图-->游戏回放-->PySC2的顺序进行安装。
2.1 安装环境
Ubuntu 16.04
Python 3.5
注:Windows和Mac平台下的安装,差别主要在于机器学习API的安装。PySC2支持Python 2.7+或3.4+。
2.2 机器学习API安装
项目地址:https://github.com/Blizzard/s2client-proto
该项目主要给出了星际争霸2(StarCraft II,SC2)所用的通讯协议、API接口等。对于Windows、Mac平台,API已经包含在零售版的星际争霸2中,只需在战网上完整安装星际2即可。对于Linux平台,并没有完整的游戏包,但项目也给出了自我完备的Linux包。因此,这一步主要是安装Linux包。由于通讯协议、API接口等较为底层,关注增强学习算法应用的读者可以不必关注实现细节。
对于Linux用户,首先下载SC2的Linux包,版本号为3.16.1。版本号需要注意,要与之后的游戏回放的版本号一致,否则无法兼容。
解压下载得到的zip压缩包,默认解压路径为“~/StarCraftII/”。如解压至其他路径,需要在之后PySC2安装时添加环境变量SC2PATH。解压密码为“iagreetotheeula”(引号内),表示同意暴雪的许可协议。
其他平台默认安装路径:
- Windows: C:\Program Files (x86)\StarCraft II\
- Mac: /Applications/StarCraft II/
2.3 地图安装
目前,支持的地图主要有三类:
- 特定任务地图Mini-game maps:包括采矿等特定任务,地图较小。
- Melee地图
- Ladder地图:包含2017年三季(Season 1、Season 2、Season 3)
将下载得到的地图压缩包解压到StarCraftII/Maps文件夹中,解压密码同上。
2.4 游戏回放安装
下载游戏回放数据,注意版本号一致。将压缩包解压至StarCraftII/Replays和StarCraftII/Battle.net文件夹中,解压密码同上。
2.5 PySC2安装
PySC2是基于Python的接口封装,比较友好。一般的读者,例如关注增强学习算法应用的读者,需要了解、接触最多的应该就是PySC2。
注:目前,PySC2依赖完整的星际2游戏和机器学习API,要求游戏版本号大于3.16.1。
PySC2可以有两种方式安装。
一是利用pip工具:
$ pip install pysc2二是从GitHub安装:
$ git clone https://github.com/deepmind/pysc2.git
$ pip install pysc2/3. PySC2初探
暴雪提供的机器学习API主要侧重于更为底层的通讯协议和游戏控制。对于一般读者,PySC2这个Python下的封装工具包更为简单友好。PySC2为增强学习代理提供了一个与星际2交互的借口,能够接收观测量并发送动作量。因此,本文将重点对PySC2进行探究。
目前,PySC2主要支持两种模式进行游戏:利用代理进行操作或者人直接操作。另外,PySC2也支持观看游戏回放。
3.1 利用代理进行操作
利用代理进行操作,需要用到pysc2.bin.agent模块。同时,需要指定游戏的地图。例如,
$ python -m pysc2.bin.agent --map Simple64运行界面如下
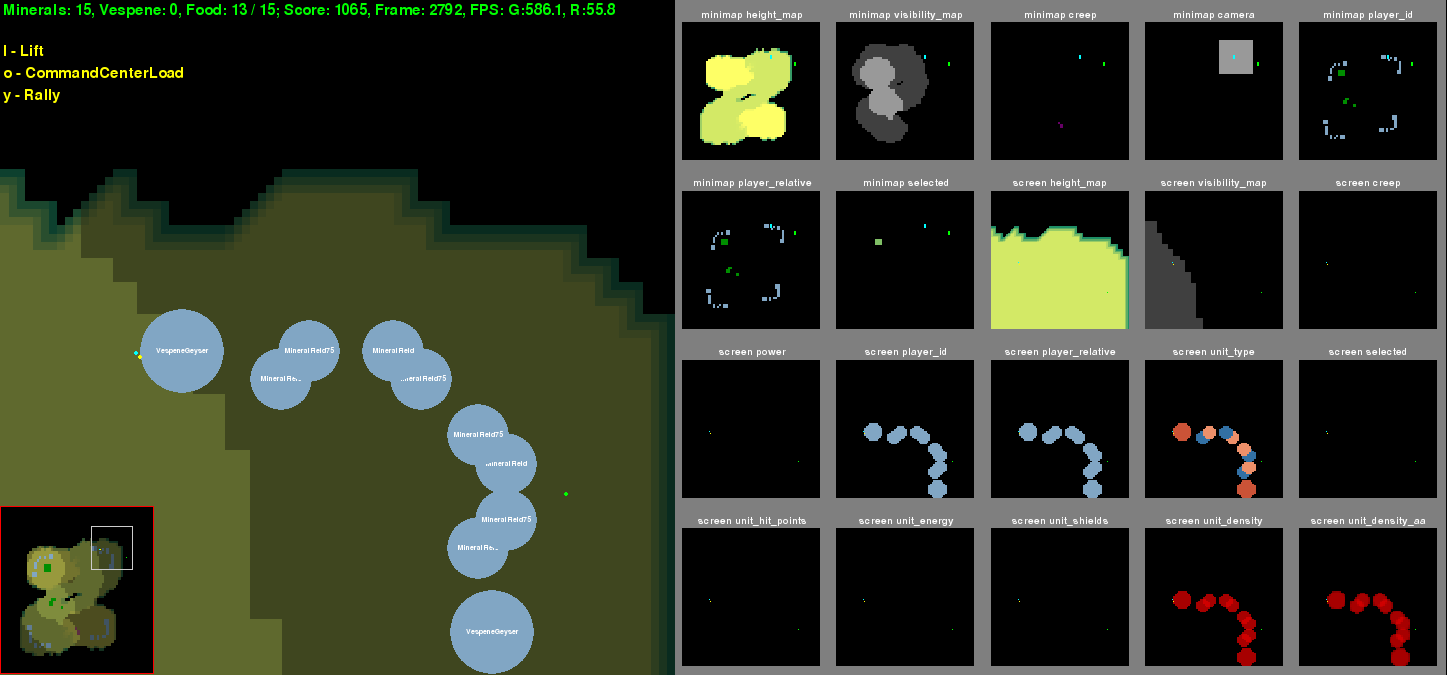

界面主要分为游戏画面screen和小地图minimap两种;左侧大地图显示的是实时游戏画面,是全局地图中分辨率较高的局部视野;大地图左下角是小地图,是分辨率较低的全局视野。PySC2将这两种画面分解成了不同的特征层,便于提取有效信息。特征层包含了一些能够描述战局的特征在地图中的分布情况,包括地图高度、玩家ID等信息。其中,游戏画面可以分解成13个特征层,小地图可以分解成7个特征层。总计20个特征层显示在界面右侧。
注:Linux平台没有完整的星际2支持,因此显示的游戏画面是简化后的画面,而不是完整的游戏画面。Windows和Mac平台可以显示原始游戏画面。
如果没有指定agent,则默认使用的代理是随机代理。你也可以指定特定或者自己定义的代理。例如在采矿的小任务(地图)中使用针对采矿任务的脚本代理。
$ python -m pysc2.bin.agent --map CollectMineralShards --agent pysc2.agents.scripted_agent.CollectMineralShards

运行中可以看到,这个代理能够很快地完成采矿任务。
在指定地图的前提下(必需),也可以运行--help标记来查看可以修改的运行选项。
3.2 人直接操作
为了便于调试,PySC2也支持人直接操作。当然,界面还是比较简单,不够完整。需要用到pysc2.bin.play模块,
$ python -m pysc2.bin.play --map Simple64在游戏界面中按下?键可以调出快捷键列表,例如F4退出、F5重新开始等。可以通过鼠标和键盘,依据左边列出的指令列表进行游戏操作。


3.3 观看游戏回放
除了操作游戏,PySC2也支持观看游戏回放,为从专业游戏数据中利用监督学习甚至模仿学习来训练智能代理提供了可能。同样需要用到pysc2.bin.play模块,
python -m pysc2.bin.play --replay <path-to-replay>需要注意的是,<path-to-replay>需要指定.SC2Replay回放文件的绝对路径。page up / page down按键可以用来控制回放速度。
4. PySC2详解
PySC2源码中包含了几个部分:
- agents:主要定义了代理的基类,给出了随机代理和针对小任务的脚本代理
- bin:PySC2的核心启动程序,主要包含了两种运行模式
- env:主要定义了面向增强学习研究的环境接口以及代理和环境相互作用的关系
- lib:定义了一些运行时依赖的代码,包括观测量、动作量及特征层的定义等
- maps:定义了一些针对地图的设置
- run_configs:定义了一些关于游戏运行的设置
- tests:定义了PySC2的一些单元测试
其中,比较重要的是agents,bin,env,lib,maps五个部分。下面将结合这五个部分,从运行模式、环境、代理、地图四个方面对PySC2的源码进一步分析。
4.1 运行模式
运行模式是在bin中定义的,主要包括通过代理操作和人直接操作两种。通过代理操作对应的是bin.agent模块;人直接操作对应的是bin.play模块。这两个模块是PySC2的核心运行模块,在运行PySC2时必须调用这两个模块中的某一个。其中,针对不同的运行模式,可以通过命令行参数定制不同的运行选项。
通过代理操作。agent模块主要完成的功能是根据需求打开多个线程;每个线程中,分别从env中生成星际2的环境,从agents中调用代理模块,并利用env.run_loop模块执行环境和代理之间的循环交互。这种运行模式下,一共有15个命令行参数可以定制,其中部分为增强学习环境的参数,为了便于叙述,将其放在此处介绍,在3.2中将不再赘述。15个参数分别为
- render: 是否通过pygame渲染游戏画面。默认为True。
- screen_resolution: 环境参数。游戏画面分辨率。默认为84。
- minimap_resolution: 环境参数。小地图分辨率。默认为64。
- max_agent_steps: 代理的最大步数。默认为2500。
- game_steps_per_episode: 环境参数。每个运行片段的游戏步数。默认为0,表示没有限制。若为None,表示使用地图的默认设置。
- step_mul: 环境参数。代理的每一步中游戏推进步数。这一参数决定了代理操作的速度,通俗讲即人类操作的“手速”,影响和人类对比时的公平性,详见actions per minute (APM)。默认为8,约等于180APM,和中等水平人类玩家相当。若为None,表示使用地图的默认设置。
- agent: 指定运行哪个代理。默认为自带的随机代理pysc2.agents.random_agent.RandomAgent。
- agent_race: 环境参数。代理的种族。默认为None,即Protoss、Terran、Zerg中随机产生。
- bot_race: 环境参数。游戏AI的种族。默认为None,即Protoss、Terran、Zerg中随机产生。
- difficulty: 环境参数。游戏难度。默认为None,表示VeryEasy。对于难度设置,有对应关系:1 --> VeryEasy, 2 --> Easy, 3 --> Medium, 4 --> MediumHard, 5 --> Hard, 6 --> Harder, 7 --> VeryHard, 8 --> CheatVision (视野作弊), 9 --> CheatMoney (金钱作弊), A --> CheatInsane (疯狂作弊)。
- profile: 是否打开代码分析功能。默认为False。
- trace: 是否追溯代码执行。默认为False。
- parallel: 并行运行多少个实例(线程)。默认为1。
- save_replay: 是否在结束时保存游戏回放。默认为True。
- map: 环境参数。将要使用的地图名字。默认为None。注意该参数必须指定,不能缺省。
人直接操作。play模块实现了人机交互的功能也能实现游戏回放的功能。对于一般读者而言,本模块重点在于应用,无需深入掌握,因此不再赘述。感兴趣的读者可以阅读源码。
注:bin部分主要是agent和play两个模块,读者可以根据自身需要进行代码改写。对其他模块感兴趣的可以在此查看,例如map_list模块可以列出可用的地图名称。
4.2 环境
环境主要是在env中定义的。一个适用于增强学习研究的环境至少需要具备这几个元素:对于观测量集合的描述、对于动作集合的描述、状态推进功能、状态重置功能等。包含这些元素,PySC2在env.environment中定义了环境的Base基类,从而定义了增强学习环境的基本接口,并在env.base_env_wrapper中进行了进一步封装。在Base基类的基础上,env.sc2_env定义了具体的星际2环境,即SC2Env类。该环境具备了增强学习所必需的要素。
环境参数设置。SC2Env环境实例化时有15个可以设置的参数,其中部分在3.2.1中已经介绍不再赘述。参数如下:
- map_name: 地图名称。
- screen_size_px: 游戏画面大小(像素点)。默认为(64, 64)。
- minimap_size_px: 小地图大小(像素点)。默认为(64,64)。
- camera_width_world_units: 用真实世界单位来衡量的游戏画面宽度(摄像机视角)。例如摄像机视角宽度为24,游戏画面宽度为默认的64个像素,则每个像素代表24 / 64 = 0.375个真实世界单位。默认为None,即24。一般不用考虑。
- discount: 增强学习中回报的折现系数。默认为1。
- visualize: 是否显示画面。默认为False。
- agent_race: 代理种族。见上。
- bot_race: 内置AI种族。见上。
- difficulty: 游戏难度。见上。
- step_mul: 代理的每一步中游戏推进步数。见上。
- save_replay_steps: 每次保存回放时间隔的游戏步数。默认为0,即不保存。
- replay_dir: 保存回放的路径。默认为None。
- game_steps_per_episode: 每个运行片段的游戏步数。见上。
- score_index: 得分(回报)的指标方式。-1代表采用赢或输的环境回报作为增强学习训练的输入;>=0 意味着选取观测量累计得分score_cumulative中的某一种得分指标,例如所有单位的总价值total_value_units。总共有13种指标可以选择,详见lib.features中score_cumulative的定义。默认为None,即采用地图默认值。
- score_multiplier: 得分(回报)的放大系数。默认为None,即采用地图默认值。
对于观测量集合的描述。即env.sc2_env中SC2Env类的observation_spec方法,其实现细节则是在lib.features中Features类的observation_spec方法。观测量主要包括12种:
- screen: 游戏画面信息。存储数据的张量大小为(len(SCREEN_FEATURES), self._screen_size_px.y, self._screen_size_px.x),第一维表示画面的特征量个数,后两维表示游戏画面大小。SCREEN_FEATURES包含了13种游戏画面特征,例如地形图height_map和可见地图visibility_map等。详见定义及文档。同时,这些特征层也显示在界面右侧。
- minimap: 小地图信息。存储数据的张量大小为(len(MINIMAP_FEATURES), self._minimap_size_px.y, self._minimap_size_px.x),第一维表示小地图的特征量个数,后两维表示小地图大小。MINIMAP_FEATURES包含了7种小地图特征,例如地形图height_map和可见地图visibility_map等。详见定义及文档。同时,这些特征层也显示在界面右侧。
- player: 玩家信息。张量大小为(11,)。总共有11种玩家信息,包括玩家ID、矿物量minerals、使用的食物量food_used等。详见定义及文档。
- game_loop: 游戏循环。张量大小为(1,)。
- score_cumulative: 累计得分。张量大小为(13,)。总共有13种得分信息,包括所有单位的总价值total_value_units等。详见定义及文档。
- available_actions: 目前观测情况下的可用动作集合。张量大小为(0,)。0代表可变长度。
- single_select: 单个被选择的单位的信息。张量大小为(0, 7)。总共有7种单位信息,包括单位类型unit type、生命值health等。详见文档。
- multi_select: 多个被选择的单位的信息。张量大小为(0, 7)。总共有7种信息,与single_select一致。
- cargo: 运输工具中所有单位的信息。张量大小为(0, 7)。总共有7种信息,与single_select一致。与unload动作搭配使用。
- cargo_slots_available: 运输工具中可用的空位。张量大小为(1,)。
- build_queue: 一个生产建筑正在生产的所有单位的信息。张量大小为(0, 7)。总共有7种信息,与single_select一致。与build_queue动作搭配使用。
- control_groups: 控制编组的信息。张量大小为(10, 2)。2种信息分别为10个控制编组中每个编组领头的单位类型和数量。与control-group动作搭配使用。
可以看到,代理从环境能够获得的信息,和人类玩家是基本一致的,都是通过图像信息和一些附加信息进行决策的。这种方式是相对公平的。这与直接从底层API获得游戏的全状态信息是不同的。例如,由于战争迷雾的存在,我们无法从图像中获得全局所有单位的状态信息,但是底层API是可以做到这一点的。
对于动作集合的描述。与观测量集合不同,对于动作集合的描述显得复杂得多。
星际2的动作空间非常之大。例如就“移动一个已选择的单位”这一简单组合动作而言,首先需要按下m键,然后考虑到是否要等待之前动作执行完再执行还是立即执行,需要考虑按下shift键,最后在画面或者小地图中选择一个点,来执行移动。事实上,游戏中许多基本的操作都是键盘鼠标的组合动作。将组合动作拆分成多个独立动作,再考虑这些动作的全部组合,会带来动作空间维度的急剧膨胀,是没有必要的。因此,寻找一种有效的动作表达方式来简化动作空间,是非常有必要的。一种方式是定义一个组合函数动作:move screen(queued, screen)。
PySC2定义了一系列组合动作函数,以及多种可能的参数类型。通过将组合动作转化为带参数的函数,有效简化了动作空间。命令行输入如下命令,可以查看所有的动作
$ python -m pysc2.bin.valid_actions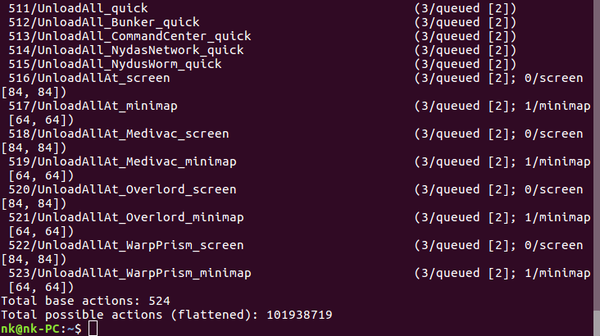

可以看到,总共有524个动作函数,都满足这样的形式
<函数ID>/<函数名>(<参数ID>/<参数类型> [<参数值大小>, *]; *)其中,函数ID和函数名是唯一的,详见定义。这些动作函数又具有不同的函数类型,每个函数类型具有特定的参数类型。因此,每个动作函数都有与之对应的参数。具体的参数类型有13个:
- screen: 游戏画面中的一个点。
- minimap: 小地图中的一个点。
- screen2: 一个矩形的第二个点。(定义的函数无法接受两个同类型的参数,因此需要定义screen2。)
- queued: 这个动作是否现在执行,还是延迟执行。
- control_group_act: 对控制编组做什么。
- control_group_id: 对哪个控制编组执行动作。
- select_point_act: 对这个点上的单位做什么。
- select_add: 是否添加这个单位到已经选择的单位中或者替换它。
- select_unit_act: 对通过ID选择的单位做什么。
- select_unit_id: 通过ID选择哪个单位。
- select_worker: 选择一个生产者做什么。
- build_queue_id: 选择哪个生产序列。
- unload_id: 从交通工具/虫洞/指挥中心中卸载哪个单位。
举两个例子:
- 1/move_camera (1/minimap [64, 64])是move_camera函数(移动摄像机),函数ID为1。该函数接受一个参数,参数类型为minimap(参数ID为1)。该参数分别需要两个整型数据,每个数据的范围为[0, 64),代表在小地图中的坐标。
- 331/Move_screen (3/queued [2]; 0/screen [84, 84]) 是Move_screen函数(移动游戏画面中已选择的单位),函数ID为331。该函数接受2个参数,参数类型分别为queued (参数ID为3,bool型,表示这个动作是现在执行还是等待之前动作执行完再执行)、screen(参数ID为0,包含两个整型数据,范围分别为 [0, 84),代表在游戏画面中的坐标)。
虽然相对传统的方式,动作空间已经简化,但由于参数不同,实际可能发生的动作远远超过了动作函数的数量,达到了101938719个,仍然是十分庞大的。对于这个问题,还有一点需要注意的是,在每一个游戏状态下,不是所有的动作都是可用的。例如,只有在有单位被选中后,移动指令才是可用的。人类玩家可以在游戏的命令卡中看到哪些指令可用;在PySC2中,我们也可以从观测量集合的可用动作available_actions中获得类似信息。相比于键鼠动作,动作函数的描述方式也为可用动作的过滤提供了便利。在键鼠动作中,很难有一种简单的方式快速过滤不可用的动作,因为单独的键鼠动作并没有特定的功能含义。
因此,采用动作函数+可用动作过滤的方式,可以大幅度缩小每个游戏状态下可操作的动作空间。当然,对于动作函数的功能和相关参数需要结合游戏本身来理解。另外,函数+参数的设计,对代理的实现,尤其是增强学习中策略网络的构造,造成了一定困难,之后会进行分析。
官方博客也用一张图,对人类的键鼠动作描述和PySC2动作函数描述进行了对比。


状态推进功能。需要接收动作,完成状态推进,返回观测量,功能实现详见step方法。实际返回的是一个元组,包括:状态类型、回报、折现系数和观测量集合。目前暂不支持多个玩家的功能。
状态重置功能。开始一个新的片段(episode),功能实现详见reset方法。
4.3 代理
代理完成的功能是接收观测量并处理,选择合适的动作,并与环境交互,主要是在agents中定义的。其中,agents.base_agent模块定义了代理的基类BaseAgent,其最主要的方法是step,即接收观测量,并返回动作。在此基础上,PySC2内置了两种演示子类,分别是随机代理(agents.random_agent.RandomAgent)和针对小任务定制的脚本代理(agents.scripted_agent中的3种)。
如何自己编写一个简单代理。对于我们自己构造的代理,与这些内置的类似,我们需要继承BaseAgent基类,并重写step方法。具体如何处理观测量并返回动作呢?注意到3.2环境的step方法返回的是一个元组timesteps,由env.run_loop可以看出,timesteps直接给到了代理的step方法作为输入。对timesteps分解,包含以下四个部分:
- timesteps.step_type: 状态类型(是首末状态或其他)。
- timesteps.reward: 回报。
- timesteps.discount: 折现系数。
- timesteps.observation: 观测量集合,字典类型,详见4.2。对于某个观测量可以通过类似timesteps.observation["available_actions"]的方式获取。
一个简单的代理应该具有如下形式
class SimpleAgent(base_agent.BaseAgent):
"""简单代理"""
def step(self, timesteps):
super(SimpleAgent, self).step(timesteps)
#############
由观测量生成动作
#############
return actions.FunctionCall(function_id, args)其中,function_id为动作函数ID,args为动作函数的参数。例如,对于select_point动作,可以有
return lib.actions.FunctionCall(2, [[0], [23, 38]]) 到这里,我们已经可以自己编写一个简单的脚本代理了。进一步,和增强学习怎么结合?
如何编写增强学习代理。对于增强学习代理,只有step方法是不够,还需要有一系列方法使其能够训练。以策略梯度为例,代理至少需要具备以下几个方法:
class PolicyGradientAgent(base_agent.BaseAgent):
"""策略梯度代理"""
def setup(self, obs_spec, action_spec): # 初始化,覆盖基类setup方法
def create_policy_net(self): # 构造策略网络
def create_training_method(self): # 构造训练方法
def train_policy_net(self): # 训练策略网络
def step(self, obs): # 根据观测量输出动作,覆盖基类step方法同时,env.run_loop只能用于一个固定的代理与环境的循环交互。在训练过程中,我们还需自己编写训练代码,调用PolicyGradientAgent和SC2Env进行交互,这不是本篇指南的内容,不做展开。
如何构造策略网络。动作函数+参数这种描述方式,与一般的动作集合有很大的不同,对策略网络的构造造成了很大的困难。一般的动作集合中,一个动作 a 是一个单独的动作。构造策略网络,就是通过一系列网络参数来逼近关于动作 a 的单变量概率分布 \pi(a|s) 。在PySC2中,一个动作 a 实际上是一个包含了多个单独动作的列表,包括了动作函数 a^0 以及一系列参数 a^1, a^2,\cdots,a^L 。构造策略网络,逼近的是关于动作 a 的多变量联合概率分布 \pi(a|s) 。
一种方式是假定这 L+1 个随机变量是相互独立的,直接构造网络表示 \pi(a|s) 。由于动作函数和参数都较多,尤其是画面坐标这些离散参数范围较大,导致这样的采样空间非常大,有101938719种可能的动作。一方面,需要非常多的网络参数才能刻画这个分布;另一方面,采样空间中无效部分太大,影响训练效果。
一同发布的论文提供了另一种思路,核心思想是发掘这 L+1 个随机变量之间内在的依赖关系,从而剔除不合理的组合,减小采样空间。对于某个特定的动作函数 a^0 ,并不一定要求全部 L 个参数,每个参数也不要求全部的参数类型都可能发生。例如,no_op(表示不采取任何操作)这个动作函数,完全不需要任何参数,这种情况下认为其他参数是独立的并仍然进行采样,显然是十分低效的。再如,move_screen(将选择的单位移动到画面中某一点)这个动作函数,只需要两个参数,参数类型也是确定的(即queued和screen),同时参数范围也是明确的。利用链式法则,论文中将这种思想通过自回归的方式表示为
\pi(a|s) = \prod_{l=0}^{L}\pi(a^l|a^{<l},s)
实际上,是将选择一组完整动作 a 的问题转化为对各个参数 a^l 的序列决策问题。
另外,对于不可用动作的限制,论文是通过对动作函数 a^0 的概率分布重新规范化来实现的。至于具体的算法实现细节及源代码,DeepMind暂时并未公布,感兴趣的可以继续探索。
4.4 地图
无论使用何种方式,地图都是必须给出的参数。SC2Map地图文件应该存储在StarCraftII/Maps文件夹中,同时可以在pysc2.maps中定制地图对应的配置文件。配置文件可以设置一个游戏片段持续的时间、玩家个数等信息。
目前,地图主要有三种:
- DeepMind开发的Mini-Games: 由一些特定小任务组成,针对单个玩家,固定长度,可以更方便地区分代理性能的好坏。
- Ladder: 星际2天梯地图。
- Melee: 为机器学习特别定制的地图。格式上与天梯类似,但是规模更小,针对高水平操作也不一定平衡。其中,平坦(Flat)地图在地形上没有特别的要素,鼓励简单攻击,文件名中的数字代表地图大小。简单(Simple)地图更常规,具有扩张、斜坡等特性,但是比正常的天梯地图规模要小,文件名中的数字代表地图大小。
其中,Mini-Games包含7个小任务,详见mini_games。
5. 小结
不得不说,DeepMind和暴雪共同开发的SC2LE确实为人工智能社区带来了一个全新的验证平台,也为广大研究者提供了更多想象的空间。众多科技巨头、业界大牛都纷纷在这样的“竞技场”上磨炼捶打,我们不禁要问,能不能带来人工智能算法的突破性发展?能不能为一系列大规模决策问题提供解决思路?能不能带领我们向通用人工智能迈出坚实一步呢?本文抛砖引玉,希望可以帮助大家更好地入门、更快地上手实践。感谢大家!
参考资料
- s2client-proto项目:https://github.com/Blizzard/s2client-proto
- PySC2项目:https://github.com/deepmind/pysc2
- 《StarCraft II: A New Challenge for Reinforcement Learning》: https://deepmind.com/documents/110/sc2le.pdf
