
前端模块化的十年征程

这是一篇关于前端模块化的文章,但这里并不讲新技术,而是谈一谈——历史
夫以铜为镜,可以正衣冠;以史为镜,可以知兴替 ——《旧唐书·魏徵传》
前言
也许在谈论具体的内容之前,我们需要谈论一下关键词的定义。 什么是"模块"?在不同的语境下模块有不同的含义。
但在本文中,我们从广义的角度出发,将它解释为两个方面
- 外部的模块: 指代引入前端工程的某个外部的包(package),可能由多个JS文件组成,但会通过入口暴露给我们项目调用
- 内部的模块: 指代我们自己的工程项目中编码的最小单元: 即单个的JS文件
模块化已经发展了有十余年了,不同的工具和轮子层出不穷,但总结起来,它们解决的问题主要有三个
- 外部模块的管理
- 内部模块的组织
- 模块源码到目标代码的编译和转换
时间线
下面是最各大工具或框架的诞生时间,不知不觉,模块化的发展已有十年之久了。
生态 诞生时间
Node.js 2009年
NPM 2010年
requireJS(AMD) 2010年
seaJS(CMD) 2011年
broswerify 2011年
webpack 2012年
grunt 2012年
gulp 2013年
react 2013年
vue 2014年
angular 2016年
redux 2015年
vite 2020年
snowpack 2020年 外部模块的管理
在模块化的过程中,首先要解决的就是外部模块的管理问题。
Node.js和NPM的发布
时间倒回到2009年,一个叫莱恩(Ryan Dahl)的精神小伙创立了一个能够运行JavaScript的服务器环境——Node.js,并在一年之后,发布了Node.js自带的模块管理工具npm,npm的全称是node package manager,也就是Node包管理器。
Node的出现给JavaScript的带来了许多改变:
一方面, Node使JavaScript不局限于前端,同时还成为了一门后端语言。更重要的是: 经过10年的发展,Node.js已经完全融入到了前端开发流程中。我们用它创建静态资源服务器,实现热重载和跨域代理等功能,同时还用它源代码中的特殊写法做编译转换处理(JSX/Sass/TypeScript),将代码翻译成浏览器可以理解的格式(ES5/CSS)。到今天,即使我们不用Node.js独立开发程序后台,它作为开发工具的重要性也不会改变
另一方面, Node.js自带的JS模块管理工具npm,从根本上改变了前端使用外部模块的方式,如果要打个比方的话,就好比从原始社会进入了现代社会
NPM时代以前的外部模块使用方式
在一开始没有npm的时候,如果我们需要在项目里使用某个外部模块,我们可能会去官网直接把文件下载下来放到项目中,同时在入口html中通过script标签引用它。


每引用一个外部模块,我们都要重复这个过程
- 需要用到jQuery,去 jQuery 官网下载 jQuery库,导入到项目中
- 需要用到lodash,去lodash官网下载lodash库
- 需要用到某个BootStrap,去BootStrap官网官网下载BootStrap库,导入到项目中
- ...
除了这些全局的UI库或工具库,我们可能还会使用到很多实现细节功能的辅助模块,如果都按这种方式使用未免过于粗暴,而且给我们带来许多麻烦
- 使用上缺乏便利性
- 难以跟踪各个外部模块的来源
- 没有统一的版本管理机制
而npm的出现改变了这种情况
NPM时代以后外部模块的使用方式
我们上面说过,NPM在2010年伴随着Node.js的新版本一起发布,是一个Node自带的模块管理工具。
从概念上看它由以下两个部分组成
- NPM是一个远程的JavaScript代码仓库,所有的开发者都可以向这里提交可共享的模块,并给其他开发者下载和使用
- NPM还包含一个命令行工具,开发者通过运行npm publish命令把自己写的模块发布到NPM仓库上去,通过运行npm install [模块名],可以将别人的模块下载到自己项目根目录中一个叫node_modules的子目录下
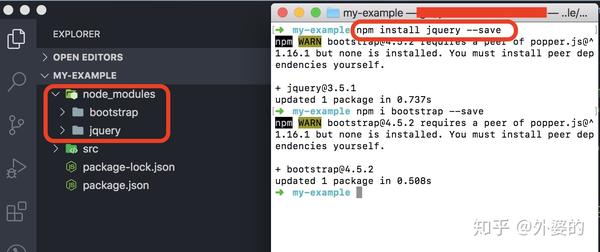

每次npm install的时候,都会在package.json这个文件中更新模块和对应的版本信息。
// package.json
{
...
"dependencies": {
"bootstrap": "^4.5.2",
"jquery": "^3.5.1"
}
}于是乎,包括jQuery等知名模块开发者的前端工程师们,都通过npm publish的方式把自己的模块发布到NPM上去了。前端开发者们真正有了一个属于自己的社区和平台,如万千漂泊游船归于港湾,而NPM也名声渐噪
早在2019年6月,NPM平台上的模块数量就超过了100万,而到写下这篇文章的时候,NPM模块数量已超过了140万
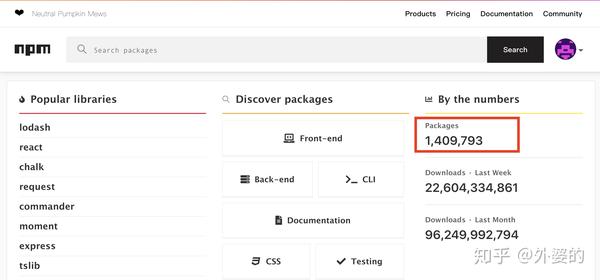

NPM的出现实际上是一个必然,前端工程的复杂化要求我们必须要有这么一个集中的JS库管理平台。但为什么它会是NPM呢?这和后来Node.js的火热有很大关系,因为NPM是Node.js内置的包管理器,所以跟随着Node得到了开发者的追捧。
综上所述,NPM解决了外部模块的管理问题。
内部模块的组织
在模块化的过程中,还需要解决的是内部模块的组织问题。
模块化第一阶段:原生JS组织阶段
在最原始的时代,我们是通过下面这种方式组织我们的模块代码的,将不同的JS文件在html中一一引入。每个文件代表一个模块
// index.html
<script src="./a.js"></script>
<script src="./b.js"></script>
<script src="./c.js"></script>
<script src="./d.js"></script> 并通过模块模式去组织代码:如下所示,我们通过一个“立即调用的函数表达式”(IIFE)去组织模块
- 将每个模块包裹在一个函数作用域里面执行,这样就可以最大程度地避免污染全局执行环境
- 通过执行匿名函数得到模块输出,可以暴露给下面的其他模块使用
<script>
var module1 = (function(){
var x = 1
return { a: x };
})();
</script>
<script>
var module2 = (function(){
var a = module1.a;
return { b: a };
})();
</script> 但这种使用方式仍然比较粗暴
- 随着项目扩大,html文件中会包含大量script标签。
- script标签的先后顺序并不能很好地契合模块间的依赖关系。在复杂应用中,模块的依赖关系通常树状或网状的,如a.js依赖于b.js和c.js,b.js依赖于b1.js和b2.js。相对复杂的依赖关系难以用script标签的先后顺序组织。
- 让代码的逻辑关系难以理解,也不便于维护,容易出现某个脚本加载时依赖的变量尚未加载而导致的错误。
- 因为对script标签顺序的要求而使用同步加载,但这却容易导致加载时页面卡死的问题
- 仍然会因为全局变量污染全局环境,导致命名冲突
我们需要针对这些问题提出解决方案,而AMD和CMD就是为解决这些问题而提出的规范
模块化的第二阶段:在线处理阶段
模块化规范的野蛮生长
10多年以前,前端模块化刚刚开始,正处在野蛮生长的阶段。这个过程中诞生了诸多模块化规范: AMD/CMD/CommonJS/ES6 Module。没错,前端并没有一开始就形成统一的模块化规范,而是多个规范同时多向发展。直到某一类规范占据社区主流之时,模块化规范野蛮生长的过程才宣告结束。
首先开始在前端流行的模块化规范是AMD/CMD, 以及实践这两种规范的require.js和Sea.js, AMD和CMD可看作是"在线处理"模块的方案,也就是等到用户浏览web页面下载了对应的require.js和sea.js文件之后,才开始进行模块依赖分析,确定加载顺序和执行顺序。模块组织过程在线上进行。
AMD && CMD
AMD和CMD只是一种设计规范,而不是一种实现。
AMD
我们先来说下AMD,它的全称是Asynchronous Module Definition,即“异步模块定义”。它是一种组织前端模块的方式
AMD的理念可以用如下两个API概括: define和require
define方法用于定义一个模块,它接收两个参数:
- 第一个参数是一个数组,表示这个模块所依赖的其他模块
- 第二个参数是一个方法,这个方法通过入参的方式将所依赖模块的输出依次取出,并在方法内使用,同时将返回值传递给依赖它的其他模块使用。
// module0.js
define(['Module1', 'Module2'], function (module1, module2) {
var result1 = module1.exec();
var result2 = module2.exec();
return {
result1: result1,
result2: result2
}
});
require用于真正执行模块,通常AMD框架会以require方法作为入口,进行依赖关系分析并依次有序地进行加载
// 入口文件
require(['math'], function (math) {
math.sqrt(15)
});
define && require的区别
可以看到define和require在依赖模块声明和接收方面是一样的,它们的区别在于define能自定义模块而require不能,require的作用是执行模块加载。
通过AMD规范组织后的JS文件看起来像下面这样
depModule.js
define(function () {
return printSth: function () {
alert("some thing")
}
});
app.js
define(['depModule'], function (mod) {
mod.printSth();
});
index.html
// amd.js意为某个实现了AMD规范的库
<script src="...amd.js"></script>
<script>
require(['app'], function (app) {
// ...入口文件
})
</script>我们可以看到,AMD规范去除了纯粹用script标签顺序组织模块带来的问题
- 通过依赖数组的方式声明依赖关系,具体依赖加载交给具体的AMD框架处理
- 避免声明全局变量带来的环境污染和变量冲突问题
- 正如AMD其名所言(Asynchronous), 模块是异步加载的,防止JS加载阻塞页面渲染
遵循AMD规范实现的模块加载器
我们前面说过,AMD只是一个倡议的规范,那么它有哪些实现呢?
根据史料记载,AMD的实现主要有两个: requireJS和curl.js, 其中requireJS在2010年推出,是AMD的主流框架

官网: https://requirejs.org/CMD
CMD是除AMD以外的另外一种模块组织规范。CMD即Common Module Definition,意为“通用模块定义”。
和AMD不同的是,CMD没有提供前置的依赖数组,而是接收一个factory函数,这个factory函数包括3个参数
- require: 一个方法标识符,调用它可以动态的获取一个依赖模块的输出
- exports: 一个对象,用于对其他模块提供输出接口,例如:exports.name = "xxx"
- module: 一个对象,存储了当前模块相关的一些属性和方法,其中module.exports属性等同于上面的exports
如下所示
// CMD
define(function (requie, exports, module) {
//依赖就近书写
var module1 = require('Module1');
var result1 = module1.exec();
module.exports = {
result1: result1,
}
});
// AMD
define(['Module1'], function (module1) {
var result1 = module1.exec();
return {
result1: result1,
}
});
CMD && AMD的区别
从上面的代码比较中我们可以得出AMD规范和CMD规范的区别
一方面,在依赖的处理上
- AMD推崇依赖前置,即通过依赖数组的方式提前声明当前模块的依赖
- CMD推崇依赖就近,在编程需要用到的时候通过调用require方法动态引入
另一方面,在本模块的对外输出上
- AMD推崇通过返回值的方式对外输出
- CMD推崇通过给module.exports赋值的方式对外输出
遵循CMD规范实现的模块加载器
sea.js是遵循CMD规范实现的模块加载器,又或者更准确的说法是: CMD正是在sea.js推广的过程中逐步确立的规范,并不是CMD诞生了sea.js。相反,是sea.js诞生了CMD

CMD和AMD并不是互斥的,require.js和sea.js也并不是完全不同,实际上,通过阅读API文档我们会发现,CMD后期规范容纳了AMD的一些写法。
AMD && CMD背后的实现原理
下面以sea.js为例
1.解析define方法内的require调用
我们之前说过,sea.js属于CMD, 所以它的依赖是就近获取的,
所以sea.js会多做一项工作:也就是对define接收方法体内require调用的解析。
先定义parseDependencies方法: 通过正则匹配获取字符串中的require中的参数并存储到数组中返回
var REQUIRE_RE = /"(?:\\"|[^"])*"|'(?:\\'|[^'])*'|\/\*[\S\s]*?\*\/|\/(?:\\\/|[^\/\r\n])+\/(?=[^\/])|\/\/.*|\.\s*require|(?:^|[^$])\brequire\s*\(\s*(["'])(.+?)\1\s*\)/g
var SLASH_RE = /\\\\/g
function parseDependencies(code) {
var ret = []
code.replace(SLASH_RE, "")
.replace(REQUIRE_RE, function(m, m1, m2) {
if (m2) {
ret.push(m2)
}
})
return ret
}
然后通过toString将define接收的方法转化为字符串,然后调用parseDependencies解析。这样我们就获取到了一个define方法里面所有的依赖模块的数组
// Parse dependencies according to the module factory code
if (!isArray(deps) && isFunction(factory)) {
deps = parseDependencies(factory.toString())
}
2. 然后Sea.js执行的时候,会从入口开始遍历依赖模块,并依次将它们加载到浏览器中,加载方法如下所示。
function request(url, callback, charset, crossorigin) {
var node = doc.createElement("script")
addOnload(node, callback, url) // 添加回调,回调函数在 3 中
node.async = true //异步
node.src = url
head.appendChild(node)
}
而且在每个依赖加载完后都会通过回调的方式调用3中的onload方法
3.在onload方法中,sea.js会设置一个计数变量remain,用来计算依赖是否加载完毕。每加载完一个模块就执行remain - 1操作,并通过remain === 0 判断依赖是否全部加载完毕。
如果全部加载完毕就执行4中的mod.callback方法
Module.prototype.onload = function() {
var mod = this
mod.status = STATUS.LOADED
for (var i = 0, len = (mod._entry || []).length; i < len; i++) {
var entry = mod._entry[i]
if (--entry.remain === 0) {
entry.callback()
}
}
delete mod._entry
}
大概因为require.js出来比较早的原因,所以没有用Promise.all一类的API
4.当判断entry.remain === 0时,也即依赖模块全部加载完毕时,会调用一开始callback方法,去依次执行加载完毕的依赖模块,并将输出传递给use方法回调
// sea.js的use方法类似于AMD规范中的require方法,用于执行入口函数
Module.use = function (ids, callback, uri) {
var mod = Module.get(uri, isArray(ids) ? ids : [ids])
mod.callback = function() {
var exports = []
var uris = mod.resolve();
// 依次执行加载完毕的依赖模块,并将输出传递给use方法回调
for (var i = 0, len = uris.length; i < len; i++) {
exports[i] = cachedMods[uris[i]].exec()
}
// 执行use方法回调
if (callback) {
callback.apply(global, exports)
}
}
}
参考资料: https://segmentfault.com/a/1190000016001572 ES6的模块化风格
关于AMD/CMD的介绍到此为止,后面的事情我们都知道了,伴随着babel等编译工具和webpack等自动化工具的出现,AMD/CMD逐渐湮没在历史的浪潮当中,然后大家都习惯于用CommonJS和ES6的模块化方式编写代码了。
这一切是怎么发生的呢? 请看
CommonJS && ES6
CommonJS是Node.js使用的模块化方式,而import/export则是ES6提出的模块化规范。它们的语法规则如下。
// ES6
import { foo } from './foo'; // 输入
export const bar = 1; // 输出
// CommonJS
const foo = require('./foo'); // 输入
module.exports = { 。 // 输出
bar:1
}
实际上我们能感觉到,这种模块化方式用起来比CMD/AMD方便。
但在最开始的时候,我们却不能在前端页面中使用它们,因为浏览器并不能理解这种语法。
但后来,编译工具babel的出现让这变成了可能
babel的出现和ES6模块化的推广
在2014年十月,babel1.7发布。babel是一个JavaScript 编译器,它让我们能够使用符合开发需求的编程风格去编写代码,然后通过babel的编译转化成对浏览器兼容良好的JavaScript。
Bablel的出现改变了我们的前端开发观点。它让我们意识到:对前端项目来说,开发的代码和生产的前端代码可以是不一样的,也应该是不一样的。
- 在开发的时候,我们追求的是编程的便捷性和可阅读性。
- 而在生产中,我们追求的是代码对各种浏览器的兼容性。
babel编译器让我们能做到这一点。在babel出现之前的AMD/CMD时代,开发和生产的代码并没有明显的区分性,开发是怎样的生产出来后也就是怎样的。
而babel则将开发和生产这两个流程分开了,同时让我们可以用ES6中的import/export进行模块化开发。
至此,AMD/CMD的时代宣告结束,ES6编程的时代到来


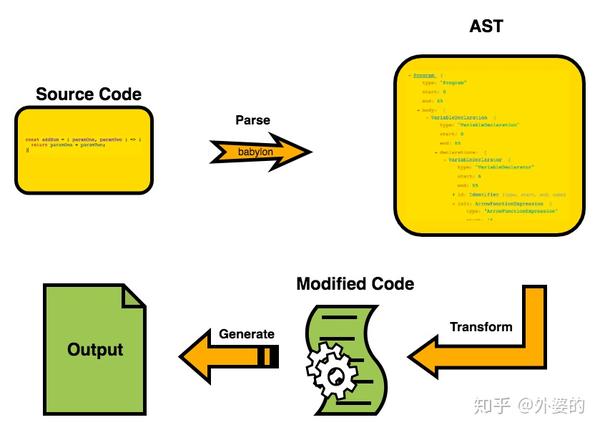
Babel的工作原理
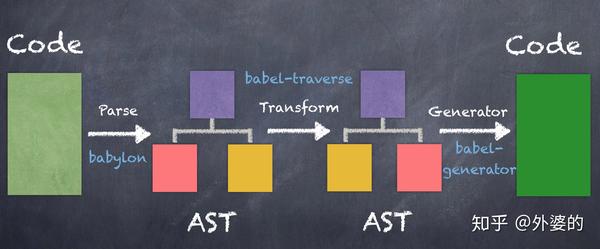
Babel的工作流程可概括为三个阶段
- Parse(解析): 通过词法分析和语法分析,将源代码解析成抽象语法树(AST)
- Transform(转换):对解析出来的抽象语法树做中间转换处理
- Generate(生成):用经过转换后的抽象语法树生成新的代码


模块化的第三阶段:预处理阶段
现在时间来到了2013年左右,AMD/CMD的浪潮已经逐渐退去,模块化的新阶段——预编译阶段开始了。
一开始的CMD/AMD方案,可看作是“在线编译”模块的方案,也就是等到用户浏览web页面下载了js文件之后,才开始进行模块依赖分析,确定加载顺序和执行顺序。但这样却不可避免的带来了一些问题
- 在线组织模块的方式会延长前端页面的加载时间,影响用户体验。
- 加载过程中发出了海量的http请求,降低了页面性能。
于是开发者们想了对应的方法去解决这些问题:
- 开发一个工具,让它把组织模块的工作提前做好,在代码部署上线前就完成,从而节约页面加载时间
- 使用工具进行代码合并,把多个script的代码合并到少数几个script里,减少http请求的数量。
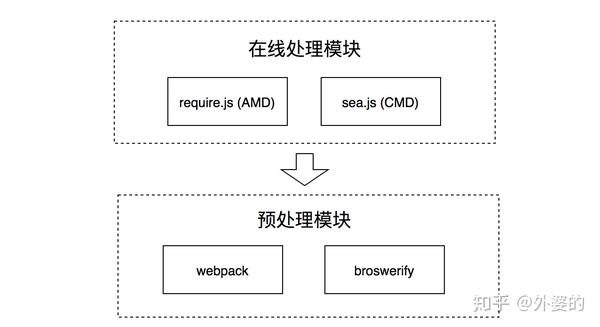

在这样的背景下,一系列模块预处理的工具如雨后春笋般出现了。
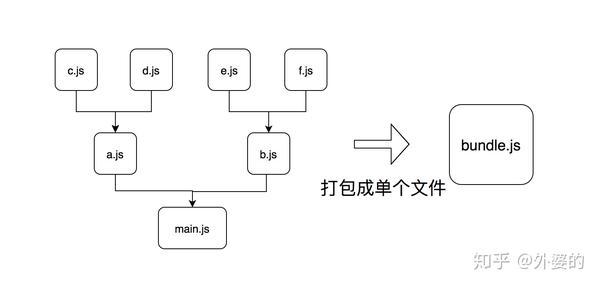
典型的代表是2011年出现的broswerify 和2012年发明的webpack。


它们一开始的定位是类似的,都是通过预先打包的方式,把前端项目里面的多个文件打包成单个文件或少数几个文件,这样的话就可以压缩首次页面访问时的http请求数量,从而提高性能。

当然后面的事情我们都知道了,webpack因为发展得更好而占据了主流的前端社区,而broswerify则渐渐消失在红尘之中。
broswerify
以broswerify为例,我们可以通过npm安装它
npm install -g browserifybroswerify允许我们通过CommonJS的规范编写代码,例如下面的入口文件main.js
// main.js
var a = require('./a.js');
var b = require('./b.js');
...
然后我们可以用broswerify携带的命令行工具处理main.js,它会自动分析依赖关系并进行打包,打包后会生成集合文件bundle.js。
browserify main.js -o bundle.js webpack
webpack是自broswerify出现一年以后,后来居上并占据主流的打包工具。webpack内部使用babel进行解析,所以ES6和CommonJS等模块化方式是可以在webpack中自由使用的。
通过安装webpack这一npm模块便可使用webpack工具
npm install --save-dev webpack 它要求我们编写一份名为webpack.config.js的配置文件,并以entry字段和output字段分别表示打包的入口和输出路径
// webpack.config.js
const path = require('path');
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js'
}
};
打包完毕后,我们的index.html只需要加载bundle.js就可以了。
<!doctype html>
<html>
<head>
...
</head>
<body>
...
<script src="dist/bundle.js"></script>
</body>
</html> 打包工具面临的问题 && 解决方案
代码打包当然不是一本万利的,它们也面临着一些副作用带来的问题,其中最主要的就是打包后代码体积过大的问题
代码打包的初衷是减少类似CMD框架造成的加载脚本(http请求)数量过多的问题,但也带来了打包后单个script脚本体积过大的问题:如此一来,首屏加载会消耗很长时间并拖慢速度,可谓是物极必反。
webpack于是引入了代码拆分的功能(Code Splitting)来解决这个问题, 从全部打包后退一步:可以打包成多个包
虽然允许拆多个包了,但包的总数仍然比较少,比CMD等方案加载的包少很多
Code Splitting有可分为两个方面的作用:
- 一是实现第三方库和业务代码的分离:业务代码更新频率快,而第三方库代码更新频率是比较慢的。分离之后可利用浏览器缓存机制加载第三方库,从而加快页面访问速度
- 二是实现按需加载: 例如我们经常通过前端路由分割不同页面,除了首页外的很多页面(路由)可能访问频率较低,我们可将其从首次加载的资源中去掉,而等到相应的触发时刻再去加载它们。这样就减少了首屏资源的体积,提高了页面加载速度。
A.实现第三方库和业务代码的分离
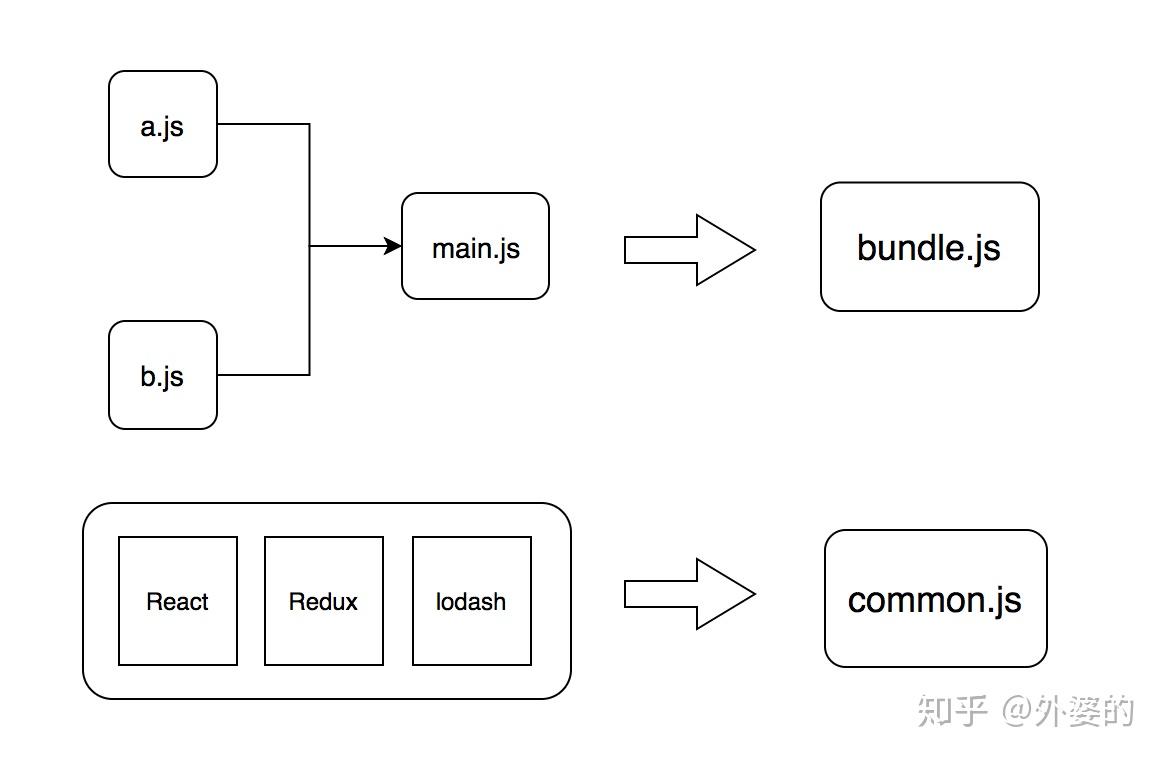
这种代码拆分可通过webpack独特的插件机制完成。plugins字段是是一个数组,可接收不同的plugins实例,从而给webpack打包程序附加不同的功能,CommonsChunkPlugin就是一个实现代码拆分的插件。
// webpack.config.js
module.exports = {
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: 'commons', // the commons chunk name
filename: 'commons.js', // the filename of the commons chunk)
minChunks: 3, // Modules must be shared between 3 entries
});
]
};
通过上面的配置,webpack在执行打包的时候会把被引用超过3次的依赖文件视为"公共文件",并单独打包到commons.js中,而不是打包到主入口文件里。
对于React,Redux,lodash这些第三方库,因为引用次数远远超过3次,当然也是会被打包到common.js中去的。

B.实现按需加载
正如其字面意思,按需加载就是等到需要的时候才加载一部分模块。并不选择将其代码打包到首次加载的入口bundle中,而是等待触发的时机,届时才通过动态脚本插入的方式进行加载: 即创建script元素,添加脚本链接并通过appendChild加入到html元素中
例如我们需要实现一个功能,在点击某个按钮的时候,使用某个模块的功能。这时我们可以使用ES6的import语句动态导入,webpack会支持import的功能并实现按需加载
button.addEventListener('click',function(){
import('./a.js').then(data => {
// use data
})
});
模块化的第四阶段:自动化构建阶段
正当打包工具方兴未艾的时候,另外一个发展浪潮也几乎在同步发生着。
它就是 —— 全方位的自动化构建工具的发展。
什么叫自动化构建工具呢? 简单的说就是: 我们需要这样一个工具,专门为开发过程服务,尽可能满足我们开发的需求,提高开发的效率。
前面说过,在模块化的过程中,我们渐渐有了“开发流程”和“生产流程”的区分,而自动化构建工具就是在开发流程中给开发者最大的自由度和便捷性,同时在生产流程中能保证浏览器兼容性和良好性能的工具。而所有的功能已经由插件直接提供,所以被称作“自动化” 构建工具。
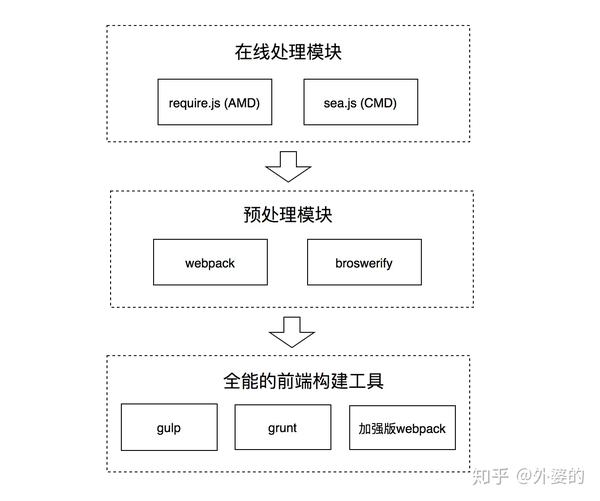

在这时,我们已经不再满足于“打包”这个功能了,我们渴望做更多的事情:
- 开发时使用丰富且方便的JS新特性,如用ES6,typescript编程,由自动化构建工具转化成浏览器兼容的ES5格式的JS代码
- 用Sass,less编写阅读性和扩展性良好的样式代码,由自动化构建工具转化成浏览器兼容的CSS代码
- 提供开发时SourceMap功能,也即提供生产代码(如ES5)到源代码(typescript)的映射,方便开发调试
- 提供生产时代码压缩功能,压缩js和css,删除注释,替换变量名(长变短),减少代码加载体积
- 提供开发热重载功能(Hot Module Reload), 也即在编辑器保存代码的时候自动刷新浏览调试页面。
- 当然也还包括基本的模块打包功能
- 其他.....
自动化构建工具的代表性工具有三个,分别是
- 2012年出现的webpack
- 2012年出现的grunt
- 2013年出现的gulp
下图中,左中右分别是gulp, grunt和webpack


这一次,webpack并没有止步于成为一个单纯的打包工具,而是参与到自动化构建的浪潮里,并且成为了最后的赢家。而grunt和gulp则像过去的Sea.js,Require.js等工具一样。逐渐地从热潮中隐退,静静地待在前端社区里的一方僻静的角落里
gulp && webpack
因为篇幅关系,我们下面只来介绍下gulp和webpack这两个自动化构建工具。
gulp和webpack的区别
对于使用者来说,gulp和webpack最大的区别也许在它们的使用风格上
- gulp是编程式的自动化构建工具
- webpack是配置式的自动化构建工具
下面我们以less代码的编译为例,展示Gulp和webpack的区别
Gulp
Gulp基本的风格是编程式的, 它是一种基于流即Node.js 封装起来的 stream 模块的自动化构建工具,一般先通过gulp.src将匹配的文件转化成stream(流)的形式,然后通过一连串的pipe方法进行链式的加工处理处理,对后通过dest方法输出到指定路径。
// gulpfile.js
const { src, dest } = require('gulp');
const less = require('gulp-less');
const minifyCSS = require('gulp-csso');
function css() {
return src('client/templates/*.less')
.pipe(less())
.pipe(minifyCSS())
.pipe(dest('build/css'))
}
Webpack
webpack的基本风格则是配置式的,它通过loader机制实现文件的编译转化。通过配置一组loader数组,每个loader会被链式调用,处理当前文件代码后输出给下一个loader, 全部处理完毕后进行输出
// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.less$/, // 正则匹配less文件
use: [
{ loader: 'style-loader' }, // creates style nodes from JS strings
{ loader: 'css-loader' }, // translates CSS into CommonJS
{ loader: 'less-loader' }, // compiles Less to CSS
],
},
],
},
};
gulp和webpack的共同点
gulp和webpack并没有自己完成所有的功能,而是搭建起一个平台,吸引世界各地的开发者们贡献插件,并构建起来一个繁荣的生态。
从提供的功能上看,gulp和webpack在很多方面是类似的,这从它们的相关生态上也可以看得出来
Gulp
- gulp-uglify : 压缩js文件
- gulp-less : 编译less
- gulp-sass:编译sass
- gulp-livereload : 实时自动编译刷新
- gulp-load-plugins:打包插件
Webpack
- uglifyjs-webpack-plugin: 压缩js文件
- less-loader: 编译less
- sass-loader: 编译sass
- devServer.hot配置为true: 实时自动编译刷新
- ....
Gulp的没落和webpack的兴起
经过了七八年的发展,webpack逐渐取代了gulp成为前端开发者的主流自动化构建工具。
究其原因
- 一方面,是因为gulp是编程式的,webpack是配置式的,webpack用起来更加简单方便,上手难度相对低一些,所以得到众多开发者的喜欢
- 另一方面,从2014年React,Vue等SPA应用的热潮兴起后,webpack和它们的结合性更好,所以也助长了webpack生态的繁荣
模块化的故事,到这里就先告一段落了。
十年征程,前端模块化终于从呱呱坠地到长大成人,


自动构建工具的新趋势:bundleless
webpack之所以在诞生之初采用集中打包方式进行开发,有几个方面的原因
- 一是浏览器的兼容性还不够良好,还没提供对ES6的足够支持(import|export),需要把每个JS文件打包成单一bundle中的闭包的方式实现模块化
- 二是为了合并请求,减少HTTP/1.1下过多并发请求带来的性能问题
而发展到今天,过去的这些问题已经得到了很大的缓解,因为
- 主流现代浏览器已经能充分支持ES6了,import和export随心使用
- HTTP2.0普及后并发请求的性能问题没有那么突出了
bundleless就是把开发中拖慢速度的打包工作给去掉,从而获得更快的开发速度。代表性工具是vite和snowpack


- vite: 尤雨溪开发的bundleless工具,能很好的配合Vue框架的开发,github上star为11k
- snowpack: 另一个bundleless工具,目前框架生态更广泛一些,支持React/Vue/Svelte,github上star为11.9k
具体的内容介绍可看之前写的一篇文章,这里暂不多介绍了
本文完
