
【R爬虫】利用RSelenium抓取动态页面

本文所有内容基于Windows系统。
前言
对于R进行静态页面爬虫,rvest、RCurl、XML这几个包都可以实现这个功能。在此推荐@文兄 写的两篇文件,介绍了如何爬取静态页面数据,我也是通过这两篇文章入门R爬虫。
传送门:【数据获取】爬虫利器Rvest包【数据获取】爬虫基础Rcurl与XML包
前几日,我遇到了一个难题,需要抓取动态页面(JS渲染页面)。通过网络搜集知识,不断整理,总算是初步解决了问题。由于相关的中文资料并不多,所以写下这篇文章和大家分享一下。
解决抓取动态页面的问题,需要一个比较强大的R包——RSelenium。
RSelenium介绍
RSelenium作用是用R调用Selenium Server。
而什么又是Selenium Server呢?
Selenium Server允许你在不同的浏览器上打开网址,对网页进行操作,并爬取网页元素的独立JAVA程序。
所以,通过Selenium Server我们可以对网页进行操作,然后爬取操作后的数据,从而进行爬取动态页面。
Selenium Server安装
下载列表:
- JAVA JDK 1.8(传送门)。Selenium Server是一个JAVA程序,需要JAVA的环境。
- Selenium Server stand-alone 3.0.1(传送门)。Selenium Server的JAVA文件。
- Chrome(传送门)。
- ChromeDriver(需翻墙传送门)(未翻墙传送门)。Selenium Server调用Chrome的驱动。
安装流程:
- 首先,安装JAVA JDK 1.8。
- 然后,安装Chrome(最新版本)。
- 之后,把解压后的ChromeDriver.exe(最新版本)放在Chrome的安装路径下。一定要和chrome.exe放在同一个目录下面。例如:
chrome.exe与chromedriver.exe都在C:\Program Files (x86)\Google\Chrome\Application目录下。(一般Chrome的默认安装路径都在这里)
- 最后,将此路径C:\Program Files (x86)\Google\Chrome\Application添加到环境变量PATH的路径中。具体的添加流程可参考这里(传送门)。
基本配置大功告成!
RSelenium使用与实例
通过实例来进一步了解RSelenium的使用。
目标:在网贷之家的数据平台(http://shuju.wdzj.com/)中爬取近7日各个P2P平台的投资人数、人均投资金额、平均收益率和成交量。下图红色方框的内容。
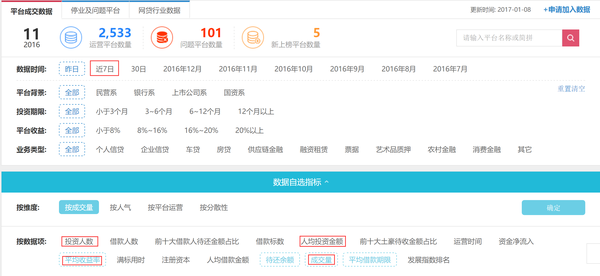
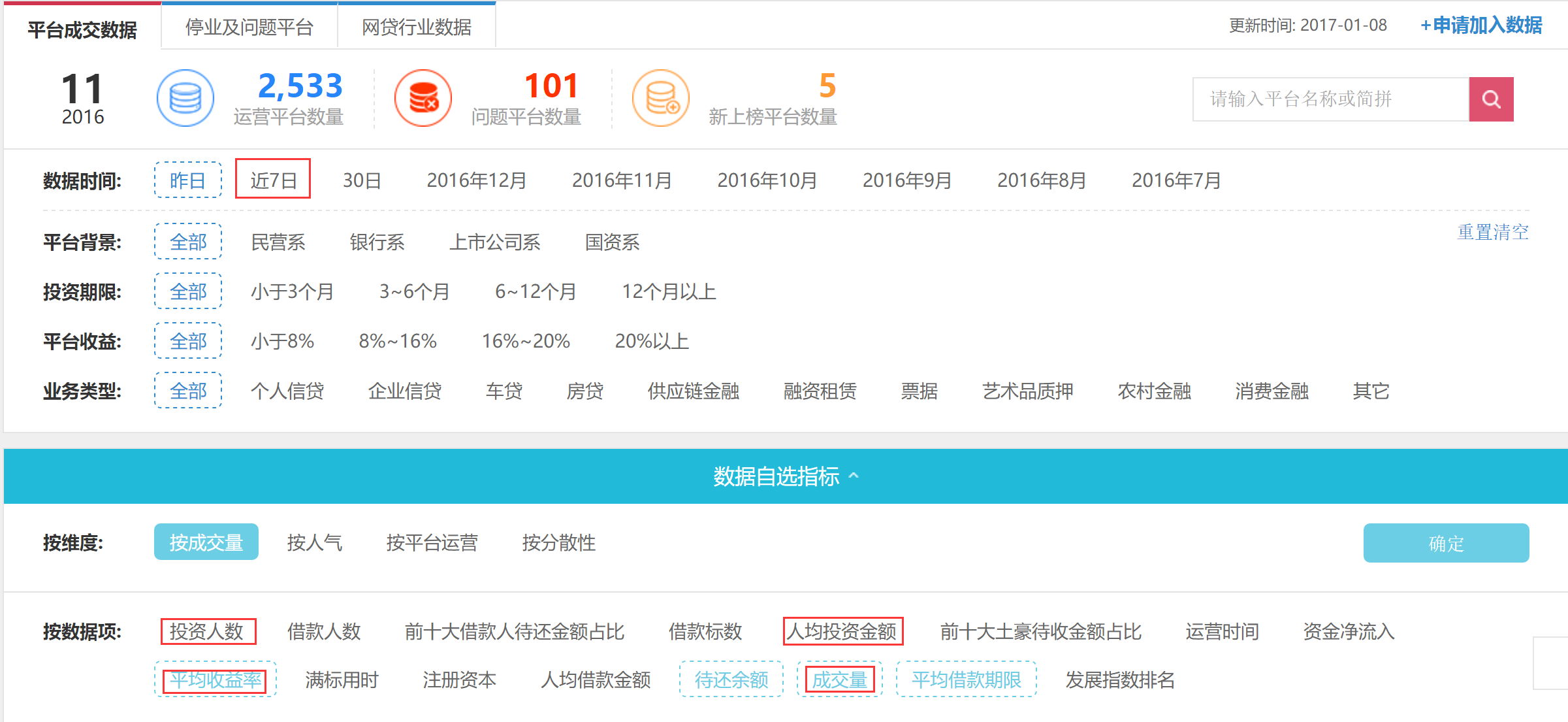
流程:
- 启动Selenium Server。在selenium-server-standalone-3.0.1.jar文件所在的位置,通过shift+鼠标右键选择“在此处打开命令行”。在命令行中运行下面的code从而启动Selenium Server。
java -jar selenium-server-standalone-3.0.1.jar
- 运行后,最小化,不要关闭。
- 通过R调用Selenium Server并打开网页,对页面进行点击,选取相应条件。通过RSelenium与rvest共同爬取数据。通过 一步一步解读Rcode来解释这一过程。
################调用R包#########################################
library(rvest) # 为了read_html函数
library(RSelenium) # 为了使用JavaScript进行网页抓取
###############连接Server并打开浏览器############################
remDr <- remoteDriver(remoteServerAddr = "127.0.0.1"
, port = 4444
, browserName = "chrome")#连接Server
remDr$open() #打开浏览器
remDr$navigate("http://shuju.wdzj.com/") #打开网页
接下来,模拟单击所需要的选项。本文通过Xpath确定选项的位置,然后点击。
如何获得Xpath?
在Chrome浏览器中,通过右击所需要查看的元素,单击“检查”,在开发者模式中,通过右击被蓝色覆盖(即被选中)的部分,单击Copy,单击Copy Xpath,即可得到Xpath。
###############对浏览器进行点击操作##############################
webElem <- remDr$findElement(using = "xpath", "/html/body/div[3]/div[2]/div[1]/div[2]/div[2]/div[1]/ul/li[4]")
#近7日
webElem$clickElement()#单击
webElem <- remDr$findElement(using = "xpath", "/html/body/div[3]/div[2]/div[2]/div[1]/a")
#数据自选指标
webElem$clickElement()#单击
webElem <- remDr$findElement(using = "xpath", "/html/body/div[3]/div[2]/div[2]/div[2]/div[2]/ul/li[1]")
#投资人数
webElem$clickElement()#单击
webElem <- remDr$findElement(using = "xpath", "/html/body/div[3]/div[2]/div[2]/div[2]/div[2]/ul/li[5]")
#平均收益率
webElem$clickElement()#单击
webElem <- remDr$findElement(using = "xpath", "/html/body/div[3]/div[2]/div[2]/div[2]/div[2]/ul/li[13]")
#待还余额
webElem$clickElement()#单击
webElem <- remDr$findElement(using = "xpath", "/html/body/div[3]/div[2]/div[2]/div[2]/div[2]/ul/li[15]")
#平均借款期限
webElem$clickElement()#单击
webElem <- remDr$findElement(using = "xpath", "//*[@id='btn-diy']")
#确定
webElem$clickElement()#单击
到此,我们已经得到了我们所需要的网页。接下来就是爬取数据了。
webElem <- remDr$findElement(using = "xpath","//*[@id='platTable']/tr[1]/td[3]/div")
webElem$getElementAttribute("outerHTML")[[1]]
read_html(webElem$getElementAttribute("outerHTML")[[1]]) %>% html_text()
通过Xpath爬取相应的HTML,然后用rvest的read_html解读得到数值。上面的代码求得表格第一行第三列的数值(成交量)。如果需要爬取更多的数值,可以通过循环或者apply家族进行获取。
结语
本文到此到一段落,以后可能还会进行修改。本文大部分内容参考RSelenium的官方文档,如果需要更加深入了解,请移步至下面的链接。
这是本人第一次写有关R的知乎文章,有什么不妥的地方,望请见谅!有什么问题或者错误,请随时通知我。
关注我本人知乎主页:火车嘟嘟嘟