
深度压缩之蒸馏模型


近年在计算机视觉、语音识别等诸多领域,深度神经网络(DNN, Deep Neural Network)被证明是一种极具成效的问题解决方式。如卷积神经网络CNN(Convolutional neural network)在计算机视觉诸多传统问题(分类、检测、分割)都超越了传统方法。
在利用深度网络解决问题的时候人们常常倾向于设计更为复杂的网络收集更多的数据以期获得更好的performance。但是,随之而来的是模型的复杂度急剧提升,直观的表现是模参数越来越多size越来越大,需要的硬件资源(内存、GPU)越来越高。不利于模型的部署和应用向移动端的推广。
有研究表明深度模型具有较大的信息参数冗余。因此我们可以通过一定的技术方法对复杂的模型进行去冗余压缩。现有的压缩方法主要可以下四类:
浅层网络:通过设计一个更浅(层数较少)结构更紧凑的网络来实现对复杂模型效果的逼近。但是浅层网络的表达能力很难与深层网络相匹敌【1】。因此,这种设计方法的局限性在于只能应用解决在较为简单问题上。如分类问题中类别数较少的task。
直接压缩训练好的复杂模型:直接对训练得到的复杂模型采用矩阵量化【2】、Kronecker内积、霍夫曼编码、模型剪枝【3】等优化方式,对模型中的参数进行量化。以实现对模型的压缩,部署阶段采用量化过后的模型可以同时达到参数压缩和提速的效果。
多值网络:最为典型就是二值网络【4】、XNOR【5】网络等。其主要原理就是采用1bit对网络的输入、权重、响应进行编码。减少模型大小的同时,原始网络的卷积操作可以被bit-wise运算代替,极大提升了模型的速度。但是,如果原始网络结果不够复杂(模型描述能力),由于二值网络会较大程度降低模型的表达能力。因此现阶段有相关的论文开始研究n-bit编码【6】方式成为n值网络或者多值网络来克服二值网络表达能力不足的缺点。
蒸馏模型:蒸馏模型采用的是迁移学习,通过采用预先训练好的复杂模型(Teacher model)的输出作为监督信号去训练另外一个简单的网络。这个简单的网络称之为student model。
下面我们将着重介绍蒸馏模型压缩方法,文章来自Geoffrey Hinton《Distilling the Knowledge in a Neural Network》【7】
摘要
在ML领域中有一种最为简单的提升模型效果的方式,在同一训练集上训练多个不同的模型,在预测阶段采用综合均值作为预测值。但是,运用这样的组合模型需要太多的计算资源,特别是当单个模型都非常浮渣的时候。已经有相关的研究表明,复杂模型或者组合模型的中“知识”通过合适的方式是可以迁移到一个相对简单模型之中,进而方便模型推广部署。
简介
在大规模的机器学习领域,如物体检测、语音识别等为了获得较好的performance常常会训练很复杂的模型,因为不需要考虑实时性、计算量等因素。但是,在部署阶段就需要考虑模型的大小、计算复杂度、速度等诸多因素,因此我们需要更小更精炼的模型用于部署。这种训练和部署阶段不同的模型形态,可以类比于自然界中很多昆虫有多种形态以适应不同阶段的需求。具体地,如蝴蝶在幼虫以蛹的形式存储能量和营养来更好的发育,但是到了后期就为了更好的繁殖和移动它就呈现了另外一种完全不一样的形态。
有一种直观的概念就是,越是复杂的网络具有越好的描述能力,可以用来解决更为复杂的问题。我们所说的模型学习得到“知识”就是模型参数,说到底我们想要学习的是一个输入向量到输出向量的映射,而不必太过于去关心中间映射过程。
模型蒸馏
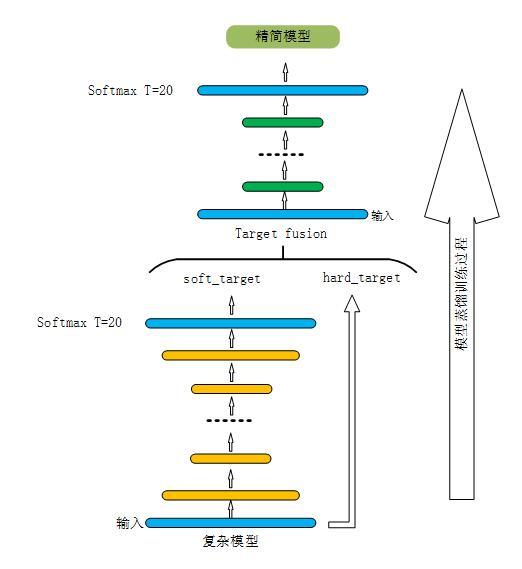
所谓模型蒸馏就是将训练好的复杂模型推广能力“知识”迁移到一个结构更为简单的网络中。或者通过简单的网络去学习复杂模型中“知识”。其基本流程如下图:
基本可以分为两个阶段:
原始模型训练:
1. 根据提出的目标问题,设计一个或多个复杂网络(N1,N2,…,Nt)。
2. 收集足够的训练数据,按照常规CNN模型训练流程,并行的训练1中的多个网络得到。得到(M1,M2,…,Mt)
精简模型训练:
1. 根据(N1,N2,…,Nt)设计一个简单网络N0。
2. 收集简单模型训练数据,此处的训练数据可以是训练原始网络的有标签数据,也可以是额外的无标签数据。
3. 将2中收集到的样本输入原始模型(M1,M2,…,Mt),修改原始模型softmax层中温度参数T为一个较大值如T=20。每一个样本在每个原始模型可以得到其最终的分类概率向量,选取其中概率至最大即为该模型对于当前样本的判定结果。对于t个原始模型就可以t概率向量。然后对t概率向量求取均值作为当前样本最后的概率输出向量,记为soft_target,保存。
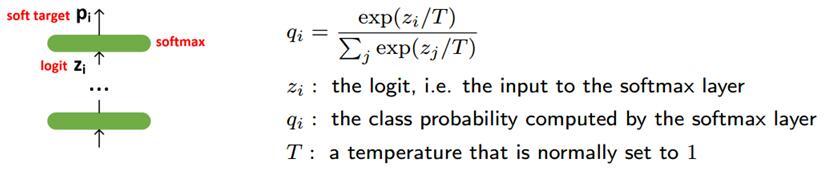

4. 标签融合2中收集到的数据定义为hard_target,有标签数据的hard_target取值为其标签值1,无标签数据hard_taret取值为0。Target = a*hard_target + b*soft_target(a+b=1)。Target最终作为训练数据的标签去训练精简模型。参数a,b是用于控制标签融合权重的,推荐经验值为(a=0.1 b=0.9)
5. 设置精简模型softmax层温度参数与原始复杂模型产生Soft-target时所采用的温度,按照常规模型训练精简网络模型。
6. 部署时将精简模型中的softmax温度参数重置为1,即采用最原始的softmax

结果
On Mnist


ON speech Recognition


结论
On MNIST
效果非常更好。对于迁移训练集数据中包含无标签数据或者某些类别数据缺失,依然能够有很好的表现。说明该模型具有非常的推广能力。
On Speech Recognition
组合模型中的所有“知识”都可以被蒸馏集成到精简模型中,这样极大的减少部署的难度。
[1]. Ba, J., Caruana, R.: Do deep nets really need to be deep? In: Advances in neural information processing systems. (2014) 2654–2662 3
[2]. Wu J, Leng C, Wang Y, et al. Quantized Convolutional Neural Networks for Mobile Devices[J]. arXiv preprint arXiv:1512.06473, 2015.
[3]. Han S, Mao H, Dally W J. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding[J]. CoRR, abs/1510.00149, 2015, 2.
[4]. Courbariaux M, Hubara I, Soudry C O M D, et al. Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to+ 1 or−[J].
[5]. Rastegari M, Ordonez V, Redmon J, et al. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks[J]. arXiv preprint arXiv:1603.05279, 2016.
[6]. Wen H, Zhou S, Liang Z, et al. Training Bit Fully Convolutional Network for Fast Semantic Segmentation[J]. arXiv preprint arXiv:1612.00212, 2016.
[7]. Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
