Linux性能优化11:磁盘IO的调度模型

[介绍]
这一篇讲磁盘IO的模型。
[Linux文件IO子系统]
Linux的文件IO子系统是Linux中最复杂的一个子系统(没有之一)。读者可以参考以下这个图:https://www.thomas-krenn.com/de/wikiDE/images/2/2d/Linux-storage-stack-diagram_v4.0.pdf
如果你懒得跳过去,这里贴一个:
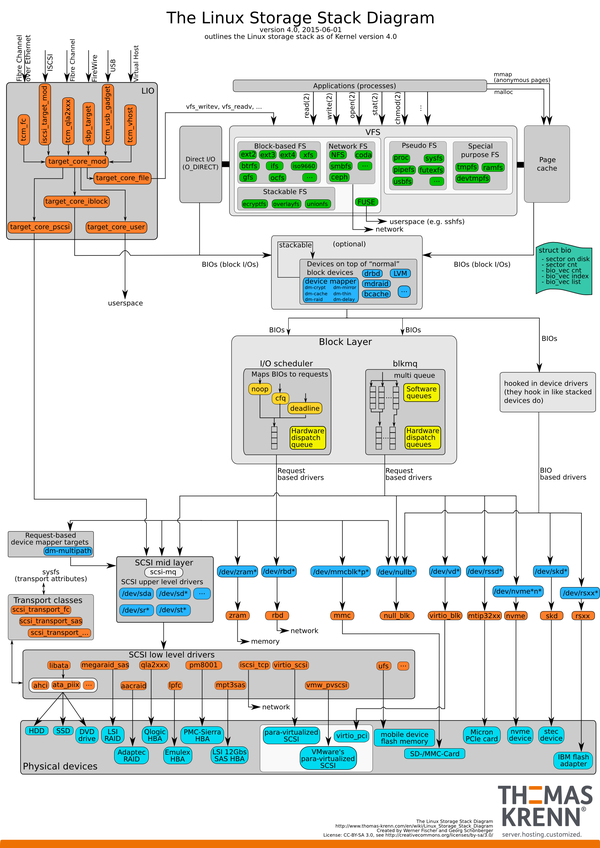

存储系统可以认为有两个部分,第一个部分站在用户的角度,提供读写的接口。这里的名称空间是以流为中心的。第二部分站在存储设备的角度,提供读写接口,这里的名称空间是以块为中心。插在两者中间提供承接的是文件系统(不是指VFS,我指的是Ext4这样的文件系统)。
简单理解,你的应用程序发出一个读写请求,文件系统负责定位这个读写请求的位置,换成块设备的块,然后把这个请求发到设备上,把文件写入内存中,你的应用程序就从内存中获得数据。
所以,你会发现,上下两个部分是个异步的运行模型,对上半部分来说,不到没有办法的时候(比如你第一次要磁盘中的数据),让数据一直留在内存中是最好的。因为谁知道你后面还会不会修改这个地方呢?如果你还要读写,同步到磁盘中不是白干了?所以,数据什么时候和磁盘同步,是个独立的逻辑,和你的应用的要求(比如主动sync),内存空间的大小(比如你Pagecache占据太多的内存了),都有关系。
这个文档不是讨论Cache部分的行为,这个部分理解到这里为止。稍深入一点的介绍可以看这里:Linux 中 mmap() 函数的内存映射问题理解? - in nek 的回答。这部分的模型是纯软件模型,用一般热点方法分析就可以了。
本文主要关注下半部分的通用部分的模型,也就是上面图中Block Layer的运行模型。
[Block Layer调度模型]
数据从Pagecache同步到磁盘上,发出的请求称为一个request,一个request包含一组bio,每个bio包含要同步的数据pages,你要把Page和磁盘的数据进行同步。
和网络子系统不同,磁盘的调度是有要求的,不是说你发一个page,我就帮你写进去,你再发一个page,我就给你再写一个进去。你要写磁盘的一个地方,磁盘要先把磁头物理上移动到那个轨道上,然后才能写,你让磁头这样移来移去的,磁盘的性能就很难看了。
Linux的IO调度器称为evelator(电梯),因为Linus开始实现这个系统的时候,使用的就是电梯算法。
坐过电梯很容易理解什么是电梯算法,电梯的算法是:电梯总是从一个方向,把人送到有需要的最高的位置,然后反过来,把人送到有需要的最低一个位置。这样效率是最高的,因为电梯不用根据先后顺序,不断调整方向,走更多的冤枉路。
为了实现这个算法,我们需要一个plug的概念。这个概念类似马桶的冲水器,你先把冲水器用塞子堵住,然后开始接水,等水满了,你一次把塞子拔掉,冲水器中的水就一次冲出去了。在真正冲水之前,你就有机会把数据进行合并,排序,保证你的“电梯”可以从一头走到另一头,然后从另一头回来。
我们前面讲IO系统的时候就提过磁盘调度子系统的ftrace跟踪,这里我们深入看看blktrace跟踪到的事件的含义:
请求相关
- Q - queued:bio请求进入调度
- G - get request:分配request
- I - inserted:request进入io调度器
调度相关
- B - bounced:硬件无法访问内存,需要把内存降低到硬件可访问
- M - back merge:请求和前一个从后面合并
- F - front merge:请求和前一个从前面合并
- X - split:请求分析为多个request(很可能是因为硬件不支持太大的请求)
- A - remap:基于分区等,重新映射request的位置
- R - requeue: Request重新回到调度队列
- S - sleep:调度器进入休眠P - plug:调度队列插入设备(准备合并)
- U - unplug:调度队列离开设备(全部一次写入设备中)
- T - unplug due to timer超时,而不是数据足够发起的unplug
发出相关
- C - complete:完成一个request的调度(无论成功还是失败)
- D - issued:发送到设备,这个是从下层硬件驱动发起的
我们通过对这些事件的跟踪,对照硬件的特性大概就可以知道运行的模型是否正常了。
[多调度器支持]
但情况千变万化,不是每种磁盘,每个场景都可以用一样的算法。所以,现在Linux可以支持多个IO调度器,你可以给每个磁盘制定不同的调度算法,这个在/sys/block/<dev>/queue/scheduler中设置。它的用户接口设计得很好,你看看它的内容就明白我的意思了:
noop [deadline] cfq
上面三个是我的PC上支持的三个算法,其中被选中的算法是deadline,写另一个名字进去可以选定另一个调度算法。
我们简单理解一下这三个算法:
noop是no operation,就是不调度的算法,有什么请求都直接写下去。这通常用于两种情形:你的磁盘是比如SSD那样的内存存储设备,根本不需要调度,往下写就对了。第二种情形是你的磁盘比较高级,自带调度器,OS不需要自作聪明,有什么请求直接往下扔就好了。这两种情况就应该选noop算法
deadline是一个改良的电梯算法,基本上和电梯算法一样,但加了一条,如果部分请求等太久了(deadline到了,默认读请求500ms,写请求5s),电梯就要立即给我掉头,先处理这个请求。
CFQ,呵呵,这个名字是不是有种特别熟悉的感觉?对了,它就是我们前面我们讲CPU调度器时提到的CFS,完全公平调度器。这个算法按任务分成多个队列,按队列的“完全公平”进行调度。
利用这个算法,可以通过ionice设定每个任务不同的优先级,提供给调度器进行分级调度。例如:
ionice -c1 -n3 dd if=/dev/zero of=test.hd bs=4096 count=1000这个命令要求后面的dd命令按三级实时策略进行调度(实时策略需要root权限)。
ionice不需要CFS就可以工作,只是没有CFQ,策略并不能很好得到执行。通常我们在Desktop上使用deadline,在服务器上用QFQ。
对调优来说,切换调度器和相关调度参数是最简单的方案。更多的其他考虑,那就是看你怎么跟踪了。
[多队列]
另一方面,一个块设备一个队列的策略,面对新的存储设备,也开始变得不合时宜了。我们这样来体会一下这个问题:
普通的物理硬盘,每秒可以响应几百个request(IOPS)
SSD1,这个大约是6万
SSD2,~9万
SSD3,~50万
SSD4,~60万
SSD5,~78.5万
一个队列?开玩笑!
一个队列会带来如下问题:
1. 全部IO中断会集中到一个CPU上
2. 不同NUMA节点也会集中到一个CPU上
3. 所有CPU访问一个队列会造成前面提到的Amdahl模型的spinlock问题
所以,和网络一样,现在块设备子系统也支持多队列模型,称为mq-blk。也和队列网卡一样,这个特性需要你的硬件支持多队列,如果你使用scsi库,你需要你的设备支持mq-scsi。使用m-blk后,io调度器直接作用在每个queue上。
[AIO]
AIO的名字叫异步IO,其实本质上并非是对文件系统的异步封装,而是从块设备层直接出访问接口,只是这个接口恰好是异步的,所以才叫AIO。
AIO的实现在内核fs/aio.c中,现在好像还没有对应的库封装(请注意,posix的aio(7)文档描述的AIO接口是POSIX库自己对文件系统的封装,而Linux内核的AIO现在没有库的封装,需要用户自己做系统调用来实现。除非特别指出,本文涉及的AIO接口都指向Linux内核的AIO,而不是Posix的AIO。
AIO包括如下系统调用:
io_setup() 创建一个context上下文
io_destroy()删除context
io_submit() 发出命令
io_get_events() 接收命令(事件)
io_cancel() 取消
这个接口不用过多解释,猜都能猜到怎么用(具体细节自己上网搜),这里想说明的是调度模型。本质上,AIO的“事件”就是我们前面分析块设备接口中的一个“命令”(读写都可以),一个io_submit()就是一次plug(),unplug()的过程,也就是你发起一个submit,发出一组iocb,每个iocb就是一个读写操作,submit的时候就先plug,把请求堵住,然后把iocb灌进去,然后unplug,把请求发出去。
所以,对AIO的跟踪不会比一般的跟踪复杂,因为都是跟踪块设备层的方法。