
推荐系统中的embedding技术

本文是作者基于相关研究和实际工作经验总结而得,加以自己的理解,欢迎大家拍砖,一起讨论交流和学习,加深对技术的理解,方便以后对业务最更好的技术选型。
随着DNN模型在推荐领域中被广泛使用,embedding技术成为推荐系统的标配,从最初的item2vec到图表示学习,不同的模型学习的侧重点不同,因此希望通过这篇文章总结一下在推荐系统中常见的embedding技术。方便大家在构建自己的推荐系统时,了解各个算法的原理和边界,选择合适的算法应对自己的业务挑战。
在我们的实践中,embedding主要用于召回阶段的item表示学习,用于近邻查询,在线上根据用户的兴趣进行召回。在描述具体算法之前,我们要讲述一下召回系统在算法层面需要满足的几个特点:
- 相关性:保证召回和用户的兴趣相关。
- 泛化性:对中长尾兴趣的表达充分,防止头部资源domain整个结果。
- 新颖性:防止出现信息茧房,帮助用户发现新的兴趣,符合兴趣迁移的规律。
相关性往往是召回最先保证的,可能是从资源meta信息出发的相关(content based),也可能是通过资源共现推导的相关(cf)。算法通常对热门资源的学习表现比较好,因为有充分的数据可以学习,但有时候过度热门的资源,也会影响中长尾资源的训练,此时需要对热门资源做一些打压处理。新颖性和相关性通常来说都是相对的,很难在一个算法中同时优化相关性和新颖性,因此往往新颖性是通过explore队列,运用一些启发式的规则实现的。因此,下面的算法基本都是在保证相关性的基础下使用的。
Item2Vec
item2vec是从word2vec中继承而来。将用户对item的行为构建出doc,通过大量用户的行为组成doc集合来训练每个item的embedding。与NLP不同的是,词之间是有明确的顺序关系,而在推荐系统中,用户对资源的行为可能不存在很强的先后顺序(场景而定)。微软于2016年提出item2vec[1]中对这一点有明确表示,通过random shuffle序列打破时序关系,或者是将skip-gram模型的window设置成序列的长度,出现在同一个序列中的item之间均是相似的。通过如下的目标函数可以看出:
\frac1K\sum_{i=1}^K\sum_{-c<=j<=c,j\ne0}log(w_{i+j}|w_i) (标准的word2vec)
\frac1K\sum_{i=1}^K\sum_{j\ne i}^Klog(w_j|w_i) (item2vec)
Youtube DNN


Youtube DNN已经在很多公司中有过成功实践,相比于普通的item2vec,引入丰富的用户侧特征(包括用户的观看和搜索历史),为模型带入了丰富的side information,从而学习到的模型更加全面,泛化能力强。模型的最后一层全连接的输出作为user embedding表达(最后一层relu的输出向量)。对于item embedding,模型最后会过一层softmax对用户实际交互郭的item进行监督训练。softmax公式如下:
P(y=j|x) = \frac{e^{x^Tw_j}}{{\sum_{k=1}^K}e^{{x^T}{w_k}}} ,其中x是用户侧向量,w矩阵就是所有item的向量表达。
由此可见,user和item的embedding在同一个向量空间内,可以直接通过user进行召回,也可以计算item之间的相似度,根据user对item的兴趣表达,进行item2item的召回。
DSSM


DSSM是微软提出的一种双塔DNN模型,最初用在搜索引擎的排序中,一侧为query,一侧为doc。如果是pair-wise的方式训练,如图2所示,同时引入正负doc学习。在推荐系统中,通常一侧为user,一侧为item。通过引入用户侧和资源测丰富的特征,能够提高模型的泛化能力。在召回算法中,我们使用两个塔的输出作为embedding表达。
DSSM模型既可以用于排序模型,也可以用于召回模型。不同的是,排序算法我们可以采用用户的显式行为来进行正负样本的划分(如展现和点击),但是在召回算法中,我们需要引入负采样,召回的语义是在全量资源池中选择与用户相关性强的item进行召回,如果仅用线上为用户展示但未点击的样本作为负样本,学习的模型受之前推荐结果的影响,不符合召回系统的设计原理。因此负采样在召回中十分重要,通常会借鉴word2vec中的方法进行热度负采样。
Siamese Network
Siamese Network与DSSM类似,也是双塔结构,只不过两个塔是同质的。其最早用在图像领域,用于衡量输入的相似程度。由于两个输入是同质的,因此两个塔之间的模型结构和参数都是共享的。


在召回中,主要是通过用户行为来构建孪生网络,比如用户点击A,同时在一个session中也点击了B,则A和B可以构成一组pair。负样本采用和DSSM相同的方法,用负采样的方式获得负样本。Siamese也可以有point-wise和pair-wise两种训练方法,point-wise则根据是否为正例采用交叉熵损失函数,pair-wise则采用max margin损失函数使正负例之间有区分性。具体采用哪种损失函数要根据自己的场景和实际的AB测试来选择。不过通常来讲,pair-wise的方式能够得到更好的结果,因为在召回阶段我们强调相关性而不是优化最终的CTR。
前边的方法本质都是使用不同的方法描述item之间的共现关系,而且都是通过同一个用户与不同资源的相互行为构建关系。但其实推荐中往往涉及到不同的实体,实体之间的关系复杂。如在信息流产品中,有user,item,author等不同的实体,同时也会存在点击,展现,点赞,评论,关注等不同的关系。图是描述复杂关系很好的载体,基于图也发展出很多模型。
DeepWalk/Node2Vec
DeepWalk是图中随机游走类算法的早期模型,Node2Vec在游走的方式上进行优化,但是核心思想都是通过随机游走的方式生成游走序列。模型的假设是游走序列上的item是相似的,然后用skip-gram模型来训练,学习这种相似(共现)关系。
图相关的算法,第一步是要构建图,从节点和边来划分,主要可以分为几类。从节点的类型来看,图可以是同构的,也可以是异构的。从边来看,图可以分为有向和无向图,也会有有权和无权图的划分。在DeepWalk中,我们认为是无向等权重的同构图。在DeepWalk的官方开源实现中,https://github.com/phanein/deepwalk,邻接节点未带入权重信息,如果业务场景中对关系的权重重度依赖,可以考虑修改源码,在游走的时候按照权重进行概率游走。另外,如果是异构图,依然可以采用DeepWalk的游走思想,但是提炼metapath[2]进行游走。


本质上讲,DeepWalk类的随机游走算法是无监督模型。相比于item2vec,游走的序列更深,因此能够发掘更多隐含的共现关系,模型有一定的新颖性。但是随机游走类算法学习的依然是结构上的相似性,受用户行为的限制。需要考虑引入side information,结合cf和content based类的算法优势进行建模,因此就有了GNN类的模型。
GCN/GraphSage
GNN的模型中,目前尝试过GCN算法,使用GraphSage[3]的开源实现。GCN之所以能够成功,相比于item2vec加大了感受野,每个item的表达被周围更多的节点影响,有一种众人拾柴火焰高的感觉,学习到的结果不容易有偏差,而且对中长尾的资源效果也不错。而相比于DeepWalk等算法,引入节点的属性信息。DeepWalk相当于只采用了节点的ID类信息,因此对长尾学习的不好。通过特征的引入,模型可以通过特征来泛化,比如热门作者的冷门资源就可以通过meta信息进行泛化,更容易找到近邻被召回。
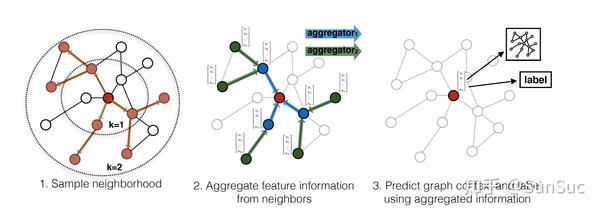

使用GraphSage有几点注意:
- maxdegree:图在初始化过程中会根据max_degree对图采样,如果不想让关键信息丢失,此处需要重点考虑。比如修改更大的max_degree(不是一个好选择),或者是在加载之前自己来做采样保留关键信息。
- 在查找邻居节点的信息时,也会进行节点采样。而github开源实现中,sample_1和sample_2的含义容易让人产生误解,sample_1表示第一层采样(第一次节点更新),并不是与中心节点第一层邻居采样个数的含义。
在实现时,最好我们能够引入自己的采样方法,能够控制关键信息被学习到。
综上,是在工作中实际使用过的embedding方法,也是一段时间的学习总结,欢迎大家一起讨论。
[1] Barkan O, Koenigstein N. Item2vec: neural item embedding for collaborative filtering[C]//2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP). IEEE, 2016: 1-6.
[2] Dong Y, Chawla N V, Swami A. metapath2vec: Scalable representation learning for heterogeneous networks[C]//Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 2017: 135-144.
[3] Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[C]//Advances in neural information processing systems. 2017: 1024-1034.


也欢迎大家关注我的公众号,给我留言讨论。
