
聊聊中药网络药理学的发文思路

从小白能懂的角度,聊生信方方面面。大家好,我是解螺旋的雪球。最近有很多学中医的小伙伴也在后台咨询,中医类课题怎么做生信?是不是也能零成本发文章?是不是也能做到零代码?首先呢,中医类课题能发生信类课题是肯定的。高通量测序一下中药干预与否的不同分组,按挑圈联靠的分析逻辑,寻找差异基因,富集聚类分析,构建互作网络,临床预后分析的四步走也是没有问题的。想要零成本发文章,得在公共数据库里找到合适的数据集。但是经过GEO/ArrayExpress这些包含各种疾病各种干预手段的高通量数据集检索就能发现,含有你预期的那个中药或者活性成分的数据集简直是大海捞针,几乎找不到。这时候怎么办呢?这时候有一个中药/药物特有的零代码分析套路——药物网络药理学分析套路。
什么是网络药理学?
中药复方是中医防病治病的主要形式,具有多成分、多靶点的特点。基于系统生物学与系统药理学的网络药理学的分析,对于我们研究中药药效具有指导意义 。网络药理学是基于药物与药物之间在结构、功效等方面的相似性,并考虑到机体内靶标分子、生物效应分子的多种相互作用关系,通过构建药物-药物、药物-靶标等网络,来预测药物的功效以及特定功效对应的药物。
中药网络药理学的分析思路
1、零代码纯干实验分析
题目一般是:基于中药网络药理学的某方剂/药对/中药治疗某疾病/改善某表型的分子机制研究。
这类课题,一般IF在1-3分,侧重于整体的分析。一般分三步走。
第一步,通过数据库/文本挖掘/软件预测等手段找到某方剂/药对/中药中的有效靶点。这一步的加分项可以是,通过计算机模拟和体外实验(SPR分析,Biocore)等验证药物小分子与靶分子之间的之间作用位点。
第二步,通过GO/KEGG富集分析,筛选靶分子相关的生物学功能和分子通路。
第三步,构建互作网络。可以是药物-活性成分-相关生物学功能/通路之间的互作网络,可以是以活性成分-相关生物学功能/通路-表型/疾病之间的互作网络,可以是靶分子之间的互作网络,也可以是以靶分子为中心构建ceRNA互作网络。
这一过程中的每一步的预测,也可以同时根据预测网站/软件等分析工具加上对应的统计值的table。这样就显得工作量满满了。
2、干湿结合的中药网络药理学研究
这类研究,侧重于实验研究,一般IF在3-5分之间。把网络药理学当作筛选靶基因、相关生物学功能、通路的预测手段,也是按三步走的策略,每一步再通过常规的分子生物学、细胞生物学的技术加以验证。
3、网络药理学与生信结合的分析套路
这类研究,把生信分析套路和网络药理学套路有机结合,一般IF在1-6分左右。
第一步,通过数据库/文本挖掘/软件预测等手段找到某方剂/药对/中药中的有效靶点。这一步的加分项可以是,通过计算机模拟和体外实验(SPR分析,Biocore)等验证药物小分子与靶分子之间的之间作用位点。
第二步,通过分析正常组和疾病组的高通量测序/芯片结果,筛选差异表达基因。
第三步,将药物预测到的靶分子与差异表达基因取交集,得到与差异表达的与药物相关的靶分子。
第四步,通过GO/KEGG富集分析,筛选靶分子相关的生物学功能和分子通路。
第五步,构建互作网络。可以是药物-活性成分-相关生物学功能/通路之间的互作网络,可以是以活性成分-相关生物学功能/通路-表型/疾病之间的互作网络,可以是靶分子之间的互作网络,也可以是以靶分子为中心构建ceRNA互作网络。
这一过程中的每一步的预测,也可以同时根据预测网站/软件等分析工具加上对应的统计值的table。
第六步,可以做免疫微环境的相关分析,或者表型相关的分析。
第七步,如果有临床相关数据,可以做临床相关性分析和预测模型的分析套路,包括常见的三表一图(基线资料表、单因素、多因素、生存曲线图),以及ROC,Nomogram,Lasso回归等分析。也可以分不同的亚组进行分析。
网络药理学常用数据库
1、疾病数据库
预测疾病对应的靶点及相关分析
OMIM数据库 http://www.omim.org/
PharmGkb 数据库 http://www.pharmgkb.org/
GAD数据库 http://geneticassociationdb.nih.gov/
Drugbank 数据库 http://www.drugbank.ca/
TTD 数据库 (Therapeutic Target Database) http://db.idrblab.org/ttd/
蛋白互作数据库
STRING数据库 https://string-db.org/
BioGRID数据库 https://thebiogrid.org/
化学药物与蛋白互作——STRING数据库的孪生姐妹,中药单体成分/化合物靶点预测
STITCH数据库 http://stitch.embl.de/
CTD数据库 (Comparative Toxicogenomics Database)http://ctdbase.org/
基因互作预测数据库
GeneMANIA数据库 http://www.genemania.org
化学结构搜索的数据库
Pubchem数据库 https://pubchem.ncbi.nlm.nih.gov/
蛋白分子数据库
Uniprot数据库 https://www.uniprot.org/
PDB数据库 https:// http://www.rcsb.org/#Category-search
中药数据库——中药方剂有效成分的查找、筛选和分析
TCMSP数据库 http://5th.tcmspw.com/tcmsp.php
BATMAN-TCM数据库 http://bionet.ncpsb.org/batman- tcm/
功能富集分析数据库——分子功能和信号通路
David https://david.ncifcrf.gov/
KEGG https://www.kegg.jp/
WebGestalt http://www.webgestalt.org/
高通量分析数据库
GEO 数据库 https://www.ncbi.nlm.nih.gov/gds/
TCGA数据库 http://www.tcga.org/
分子对接数据库
systemsDOCK http://systemsdock.unit.oist.jp/iddp/home/index
CPI-BIO http://cpi.bio-x.cn/drar/
PharmMapper https://omictools.com/pharmmapper-tool
2、常用分析软件
Cytoscape
3、常用的编程语言
R语言
Perl语言 (不必须)
网络药理学文章拆解
下面给大家解构一篇2019年发表在Drug Design, Development and Therapy的一篇中药网络药理学文章Systematic elucidation of the mechanism of geraniol via network pharmacology,影响因子2.9。
本研究的主变量牻牛儿醇,从芳香植物精油提取出来的有效成分。


根据摘要,我们可以得到这些信息:作者应用了TCMSP数据库、TCD数据库,进行了GO和KEGG富集分析,建立了药物-靶点-通路的分子网络。是不是看上去很简单,也不需要任何编程技巧呢?我们来看看具体作者是如何操作的。
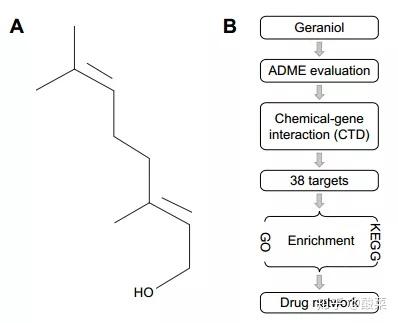
▲ Figure 1 介绍了牻牛儿醇的分子结构和文章整体的设计框架。作者在Pubchem数据库中下载到牻牛儿醇的分子结构。B图是文章的设计框架,首先作者确定了牻牛儿醇的研究主变量,接下来对牻牛儿醇的吸收、分布、代谢和排泄进行定性分析,用CTD数据库筛选出可能的作用靶点;对得到的靶点进行GO分析和KEGG分析;构建化学成分-靶点-通路之间的网络图。
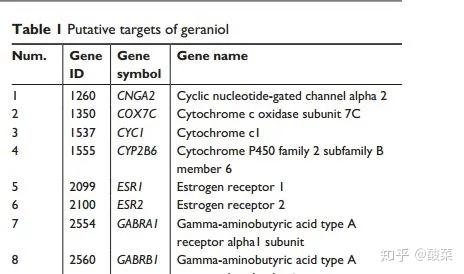

▲ Table 1 作者在CTD数据库中通过筛除非人源靶基因和设置阈值chemical-gene interaction >1,筛选到了38个潜在靶点基因。
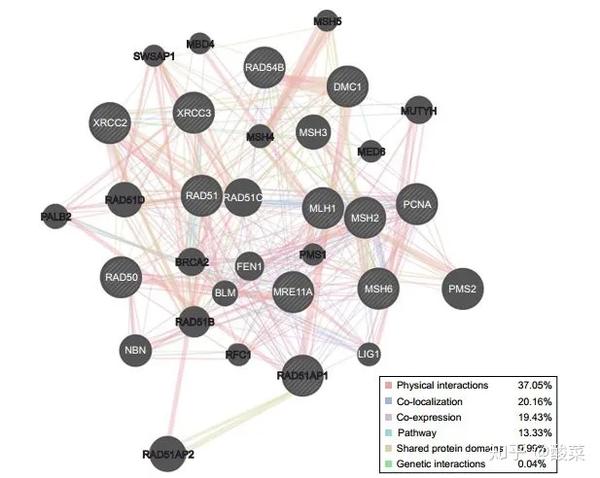

▲ Figure 2 作者通过geneMania数据库对38个靶点基因的相互作用关系、性质进行进一步分析。
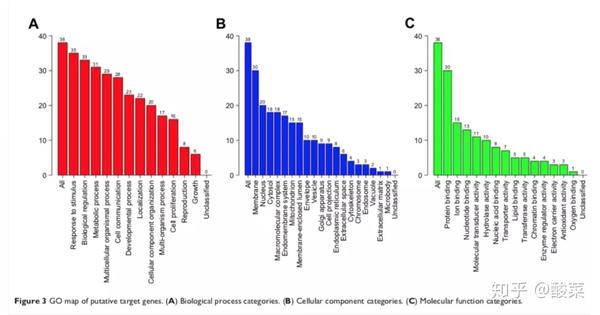

▲ Figure3 使用WebGestalt进行GO分析。
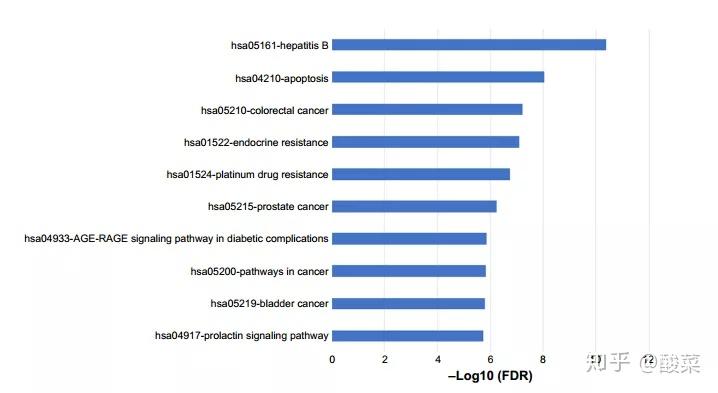

▲ Figure 4 作者通过WebGestalt数据库对靶点基因进行GO和KEGG富集分析(上图显示的KEGG富集分析结果)
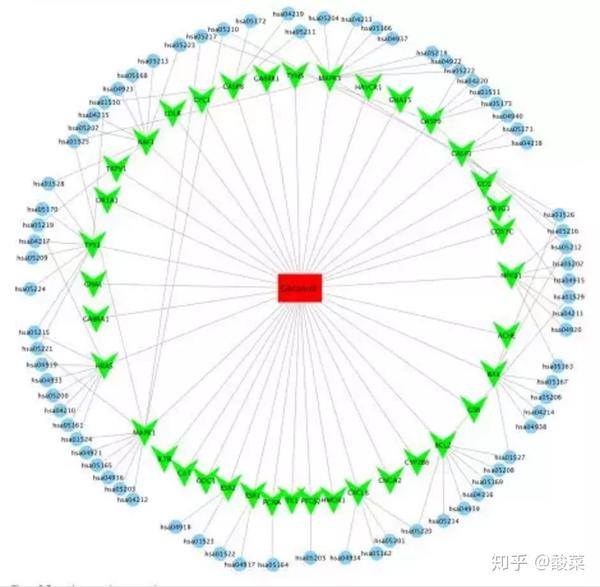

▲ Figure 5 作者将之前得到的信息导入cytoscape软件,进行可视化处理,最终构建了化学成分-靶点-通路网络。
以上就是一个经典的2-3分的中药网络药理学的SCI文章的工作量。小伙伴看到这里有没有很心动呢,简单几下操作,零编程技巧,就能出一篇文章。如果你还懂点生信,能做点分子和细胞的实验验证,还会有大概率冲击更高分的SCI期刊哦~
转载请注明:解螺旋·临床医生科研成长平台