R语言网络数据可视化(1):igraph基础

(本文首发于个人公众号“数据与平行世界”,欢迎关注)
这是一个互联的世界,那些存在着相互联系的系统,我们称其为网络。
1、网络可视化
网络可视化的目的,是希望能够获得对这些相互联系的复杂系统的直观理解。对网络进行可视化,可以展示网络的参与者和它们的联系,可以发现网络的结构和社区,可以表现信息(风险、能量等等)在网络系统中的扩散过程,也可以揭示网络随时间演化的规律。
网络可视化的类型有很多,可以表现系统网络结构(或层次结构)的图形,比如网络图(图1)、弧线图(arc diagram)、蜂巢图(hive plot)、和弦图(chord diagram)(图2)、树图、热力图等都可以归入网络可视化的范畴。本文将以示例的方式,展示网络可视化的一些方法及其R实现。


首先,我们来了解一下网络的基本概念。一个网络G,也可以称为图(graph)或网络图,是一种包含了节点V(即网络参与者,也称顶点)与边E(即节点之间的连接关系)的数学结构,记作G={V,E}。可以使用一个矩阵来存放节点之间的连接关系,这个矩阵称为邻接矩阵。如果网络中两个节点之间的边是有方向的,即从节点u出发指向节点v,这就是一个有向网络(有向图),否则称为无向网络(无向图)。网络的边也可以赋予权重,称为加权网络。
2、igraph
igraph是一个“历史悠久”的开源项目,提供了一组简单易用且功能强大的网络分析工具。igraph有多种语言接口,包括了R\Python\C++等等。尽管(无论在R还是Python中)已经有了更多的网络分析和可视化工具,igraph依然是最好的出发点。
在本文中,我们会使用几个示例。第一个示例叫做phone.call,来自于GitHub上的一个R包navdata(注,这是一个假想的数据集,里边有一个不存在的国家Slovania):
###安装并载入这个包
library(devtools)
install_github("kassambara/navdata")
library("navdata")
###载入数据集
data("phone.call")这个数据集表示的是在某段时间内欧洲部分国家领导人之间的通话次数。由数据可见,这是一个由source指向destination,以通话次数为权重的有向加权网络。
> head(phone.call)
# A tibble: 6 x 3
source destination n.call
<chr> <chr> <dbl>
1 France Germany 9
2 Belgium France 4
3 France Spain 3
4 France Italy 4
5 France Netherlands 2
6 France UK 32.1 创建igraph网络对象
igraph有特定的网络(图)对象类“igraph”。建立一个图的最简单的方法是用函数graph.formula()手工输入节点的对应关系,考虑到实际上的网络规模都是比较大的,我们几乎不会用到这种方法。更常用的方式有两种:
(1)从数据框(节点列表和边列表)建立网络对象
这种方法需要我们先建立两个数据框:
- 边列表:包含节点标签和节点的其他属性
- 节点列表:包含节点之间联系(也就是边)和边的属性
此时,可以使用graph_from_data_frame()建立igraph对象。
(2) 从邻接矩阵建立网络对象
如果数据集是表示节点连接关系的矩阵形式(比如说就像相关系数矩阵那样),可以使用graph_from_adjacency_matrix()建立igraph对象
对于phone.call这个数据集,要创建节点列表,需要将source和destination这两列包含的各个国家的名称提取出来,即提取独特的行观测,这使用dplyr包的distinct函数来实现。然后,我们创建一个新变量location,表示这些节点的地理位置:
library(tidyverse)
name<-data.frame(c(phone.call$source,phone.call$destination))
nodes<-name%>%
distinct()%>%
mutate(location=c("western","western","central","nordic","southeastern",
"southeastern","southeastern","southern","sourthern",
"western","western","central","central","central","central","central"))
colnames(nodes)<-c("label","location")下面来看边列表。数据集phone.call的前两列分别表示了边出发和终结的节点。所以这个数据集就是边列表的形式,第三列n.call可以作为边的权重。我们把这些列的名称改成更直观的名字:
edges<-phone.call%>%
rename(from=source,to=destination,weight=n.call)现在可以创建一个igraph对象了:
library(igraph)
net_pc<-graph_from_data_frame(
d=edges,vertices=nodes,
directed=TRUE)
net_pc可以看到输出的igraph对象:
IGRAPH 329e987 DNW- 16 18 --
+ attr: name (v/c), location (v/c), weight (e/n)
+ edges from 329e987 (vertex names):
[1] France ->Germany Belgium ->France France ->Spain
[4] France ->Italy France ->Netherlands France ->UK
[7] Germany ->Austria Germany ->Poland Belgium ->Germany
[10] Germany ->Switzerland Germany ->Czech republic Germany ->Netherlands
[13] Danemark->Germany Croatia ->Germany Croatia ->Slovania
[16] Croatia ->Hungary Slovenia->Germany Hungary ->Slovania 329e987是这个对象的名称,DNW- 16 18 --表示这是一个有向(D)、有命名(N)且加权(W)的网络,它有16个节点和18条边。它具有的节点属性是name , location ,具有的边属性是weight。
我们可以通过V()和E()对节点和边的属性进行访问,如:
V(net_pc)
V(net_pc)$location (结果略)
这种方法也可以用于指定或修正相应的节点和边的属性,这在igraph可视化中是很常用的。
还可以从net_pc这个网络中提取边列表或者邻接矩阵:
###提取边列表
as_edgelist(net, names=T)
###提取邻接矩阵
as_adjacency_matrix(net, attr="weight")
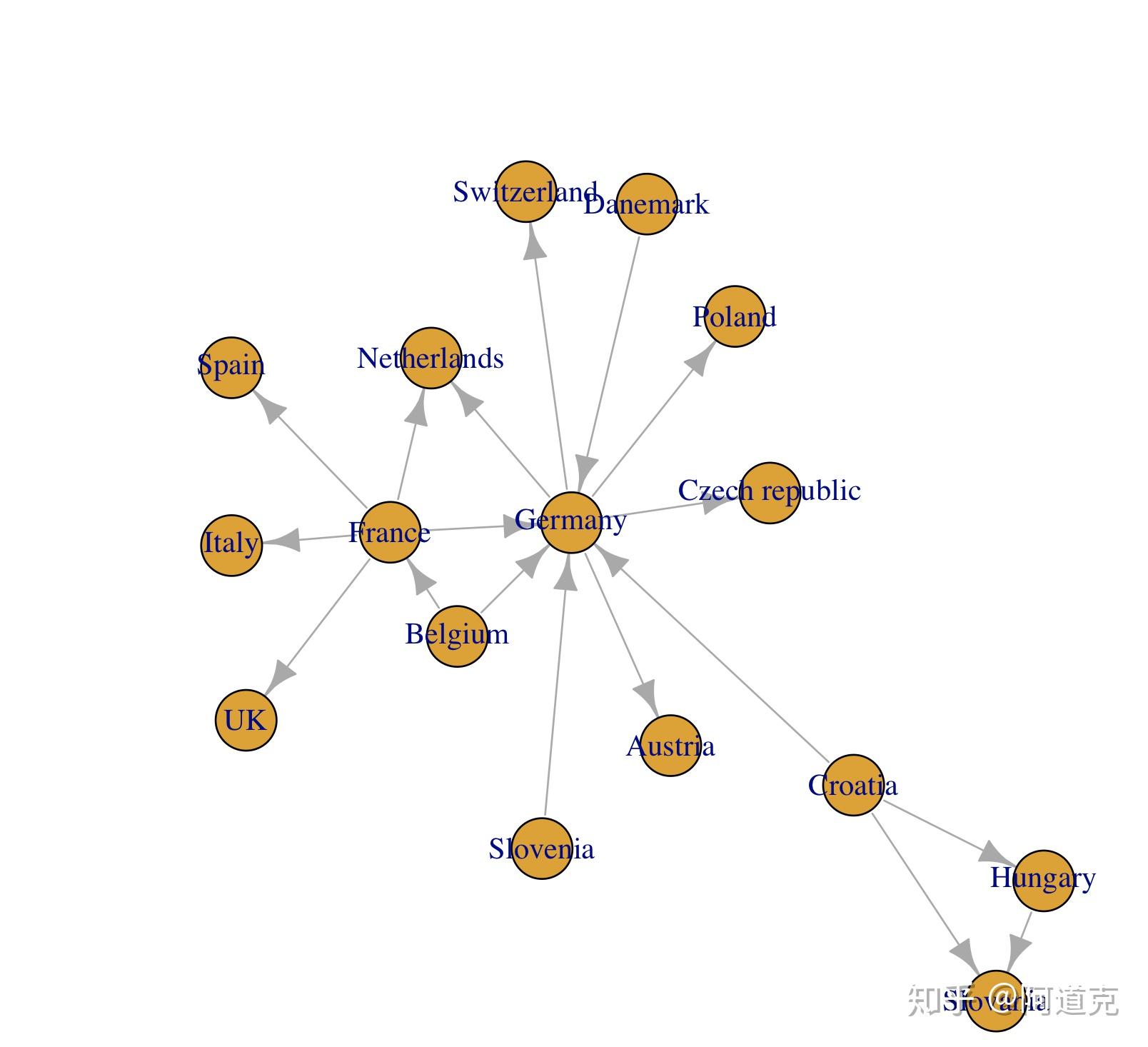
(结果略)现在可以看一下这个网络了(图3):
plot(net_pc)
2.2 igraph可视化基础
igraph的plot函数中提供了大量的参数用于展示节点、边以及图形的各种属性,其中涉及节点的参数是以vertex.开头的,涉及边的参数是以edge.开头的。
除了在plot()中指定节点和边的参数之外,还可以使用前面提到的V()和E(),直接在igraph对象中添加相应的属性。这两种方法的区别在于,在plot()中指定的参数并不会改变图的属性。比如,我们先按照位置指定节点的颜色,按照权重指定边的宽度(这两个属性会保存在net_pc对象中),然后在plot()的参数中指定节点的大小(与节点的度成比例,节点度是与这个节点相连的边的个数)、节点标记的大小和位置、边的颜色、箭头的大小和边的弯曲程度(图4):
###计算节点的度
deg<-degree(net_pc,mode="all")
###设置颜色
vcolor<-c("orange","red","lightblue","tomato","yellow")
###指定节点的颜色
V(net_pc)$color<-vcolor[factor(V(net_pc)$location)]
###指定边的颜色
E(net_pc)$width<-E(net_pc)$weight/2
plot(net_pc,vertex.size=3*deg,
vertex.label.cex=.7,vertex.label.dist=1,
edge.color="gray50",edge.arrow.size=.4, edge.curved=.1)
###添加图例
legend(x=-1.5,y=1.5,levels(factor(V(net_pc)$location)),pch=21,col="#777777",pt.bg=vcolor)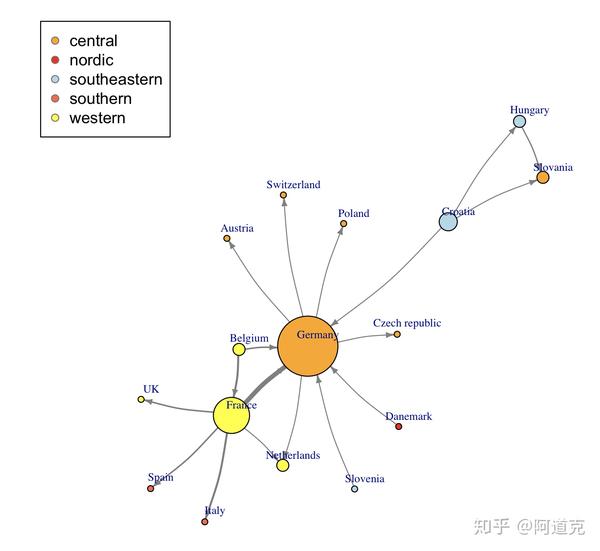
2.2 网络布局
网络布局指的是确定网络中每个节点坐标的方法。
igraph中提供了多种布局算法,其中最有用的是几种力导向(Force-directed)布局算法。力导向布局试图得到一个美观的图形,其中的边在长度上相似,并且尽可能少地交叉。它们把图形模拟成一个物理系统。节点是带电粒子,当它们靠得太近时会互相排斥。这些边充当弹簧,将连接的节点吸引在一起。结果,节点在图示区域中均匀分布,并且布局直观,因为共享更多连接的节点彼此更接近。这些算法的缺点是速度很慢,因此在大于1000个顶点的图中使用的频率较低。
使用力导向布局时,可以使用niter参数控制要执行的迭代次数。默认设置为500次迭代。对于大型的图,可以降低该数字以更快地获得结果,并检查它们是否合理。
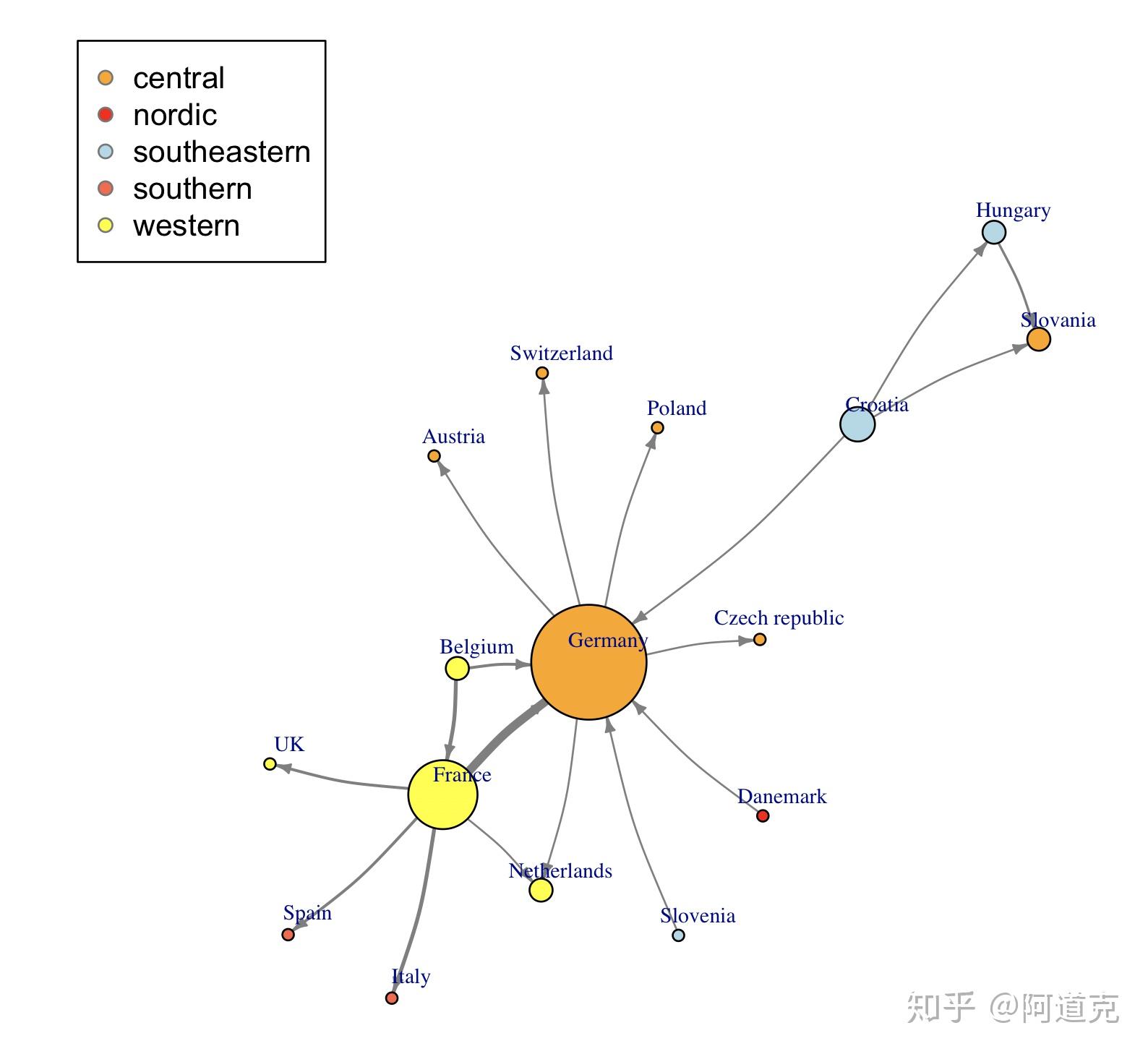
Fruchterman-Reingold是最常用的力导向布局算法:
l <- layout_with_fr(net_pc)
plot(net_pc, layout=l)
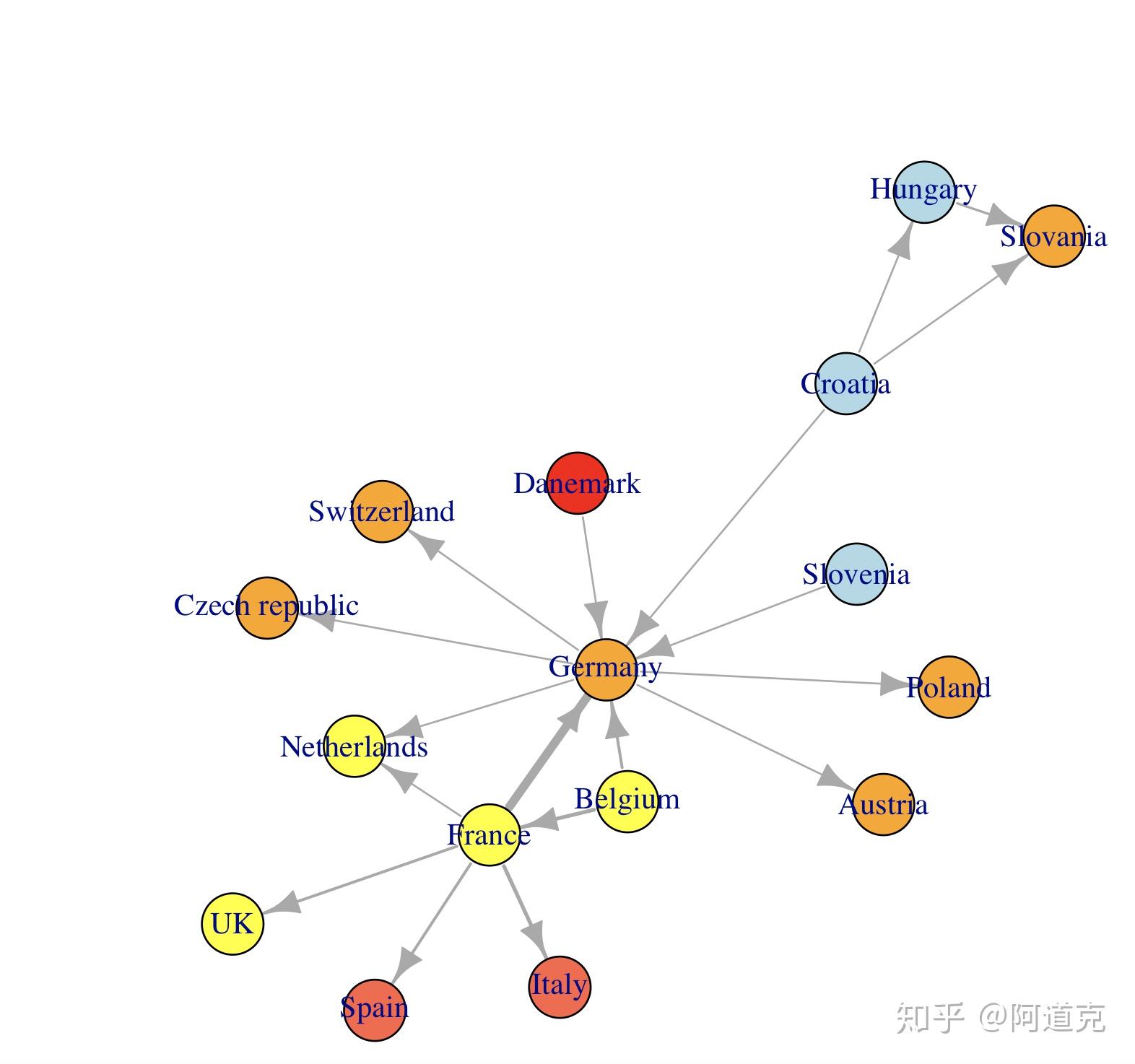
Fruchterman Reingold布局具有随机性,不同的运行将导致略有不同的布局配置。将布局保存在对象l当中,可以使我们多次获得完全相同的结果(也可以实现指定随机数种子seed())。
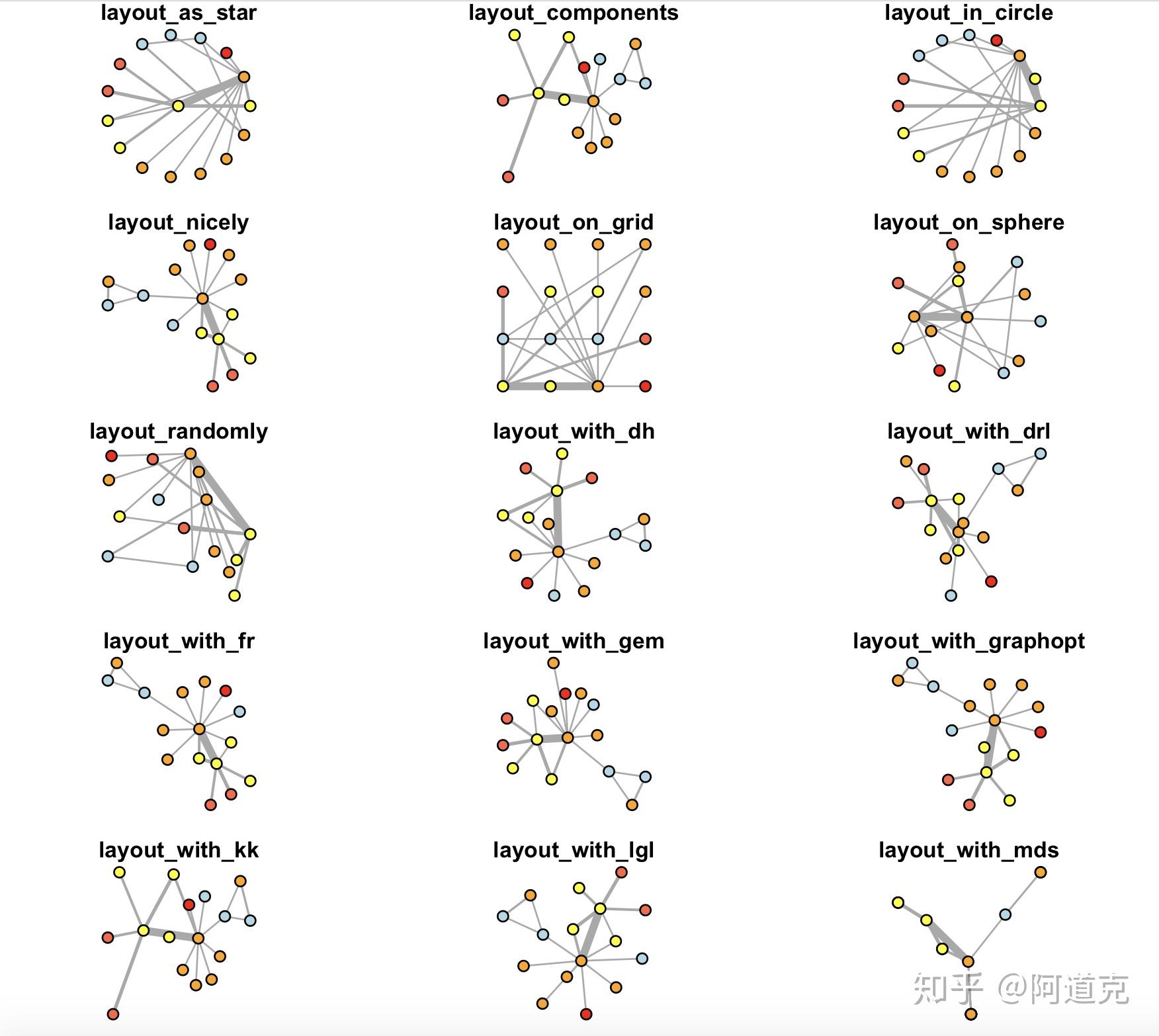
我们通过一张图来展示所有的(用于单模图的)布局方式(图6):
layouts <- grep("^layout_", ls("package:igraph"), value=TRUE)[-1]
# Remove layouts that do not apply to our graph.
layouts <- layouts[!grepl("bipartite|merge|norm|sugiyama|tree", layouts)]
par(mfrow=c(5,3), mar=c(1,1,1,1))
for (layout in layouts) {
print(layout)
l <- do.call(layout, list(net_pc))
plot(net_pc, vertex.label="",edge.arrow.mode=0, layout=l, main=layout) }