Ranking loss系列(二)Triplet loss

Triplet loss 来自论文:FaceNet: A Unified Embedding for Face Recognition and Clustering [1],提出的目的是使网络学到更好的人脸 embdding,即同一个人的不同输入通过网络输出的 embdding 之间距离尽量小,不同人得到的 embdding 之间距离尽量大。同样的思想也可以应用在行人重识别等个体 identify 或细粒度分类任务中。
基本思想
区别于 Contrastive loss 通过一对样本构造 Pairwise Ranking Loss,Triplet loss 通过一个三元组 <a,p,n> 来构造损失函数,具体地:
选择一个样本 embdding 作为 anchor,找到该样本的同类 embdding 作为 positive,找到不同于该样本类别的 embdding 作为 negative。
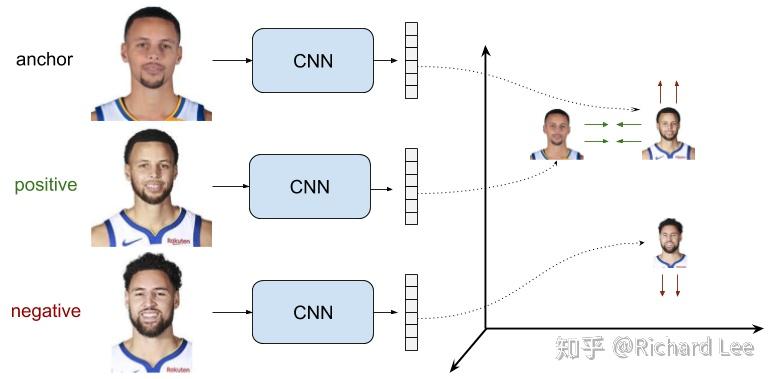

目标函数是使得 <a,p> 之间距离小于 <a,n> ,或者更进一步要求距离差距大于margin,即:
L=max(d(a,p)−d(a,n)+margin,0) \\
三元组的可能分布如下:
- Easy Triplets: d(a,n) > d(a,p)+margin 。负样本的距离已经大于正样本的距离,且满足间隔裕量margin。此时损失 L 为 0。
- Hard Triplets: d(a,n) < d(a,p) 。负样本的距离比正样本的距离还小,此时损失 L 大于margin。
- Semi-Hard Triplets: d(a,p) < d(a,n) < d(a,p)+margin 。负样本的距离虽比正样本大,但不满足间隔裕量margin。此时损失 L 大于0,但小于margin。
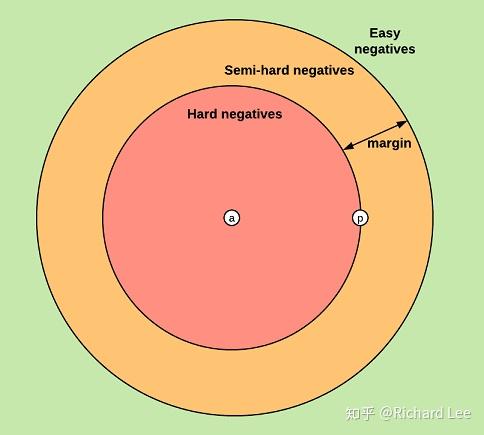

Easy Triplets 显然不应加入训练,因为它的损失为0,加在loss里面会拉低loss的平均值。Hard Triplets 和 Semi-Hard Triplets 的选择则见仁见智,针对不同的任务需求,可以只选择Semi-Hard Triplets或者Hard Triplets,也可以两者混用。
具体实现
- Batch Alll
在一个batch中,对每个anchor,找到所有 Hard Triplets 和 Semi-Hard Triplets 计算损失。
- Batch Hard
在一个batch中,对每个anchor,找到距离最近的 negative 和距离最远的 positive,组成一个 Hard Triplets 计算损失。
# 1. 计算特征向量两两之间距离矩阵
# 2. 构造 Hard Triplets 和 Semi-Hard Triplets
# 3. 计算ranking margin loss
# pytorch
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, reduction='mean')
# tensorflow
tf.contrib.losses.metric_learning.triplet_semihard_loss相关文献:
FaceNet: A Unified Embedding for Face Recognition and Clustering
参考:
Triplet-Loss原理及其实现、应用
Understanding Ranking Loss
